Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Python


PDF(Format de document portable) est le format de fichier le plus populaire pour le transfert de données sur internet, car il préserve le formatage du contenu et permet de sécuriser les données à l'aide de permissions de sécurité. Dans certains cas, il est nécessaire de convertir des fichiers PDF en images JPG ou tout autre format d'image tel que PNG, BMP, TIFF ou GIF. Il existe de nombreuses ressources en ligne disponibles pour la conversion JPG, mais à quel point serait-il cool de créer notre propre outil de conversion PDF vers image en Python ?
Python est un langage de programmation de haut niveau qui est utilisé pour construire des applications logicielles, des sites web, automatiser des tâches, effectuer des analyses de données et réaliser des tâches d'intelligence artificielle et d'apprentissage automatique. C'est également un langage de script puisqu'il est interprété, ce qui le rend plus puissant en termes de développement et de test rapides.
Pour créer un convertisseur de PDF en image, il faut que Python 3+ soit installé sur l'ordinateur. Téléchargez et installez la dernière version à partir du sitesite officiel.
Dans cet article, nous allons créer notre propre application de conversion d'images en utilisant les bibliothèques PDF to image de Python. Pour ce faire, nous utiliserons deux des bibliothèques les plus populaires de Python : PDF2Image et PyMuPDF.
Installez la bibliothèque Python pour convertir les PDF en images.
Chargement d'un fichier PDF existant à partir de n'importe quel emplacement.
Utiliser des méthodes de conversion.
Parcourir les pages du fichier.
Ouvrez l'application Python IDLE et appuyez sur les touches Ctrl + N. L'éditeur de texte s'ouvre. Vous pouvez utiliser l'éditeur de texte de votre choix pour ce faire.
Enregistrez le fichier sous le nom pdf2image.py, dans le même emplacement que le fichier PDF que vous souhaitez convertir en images.
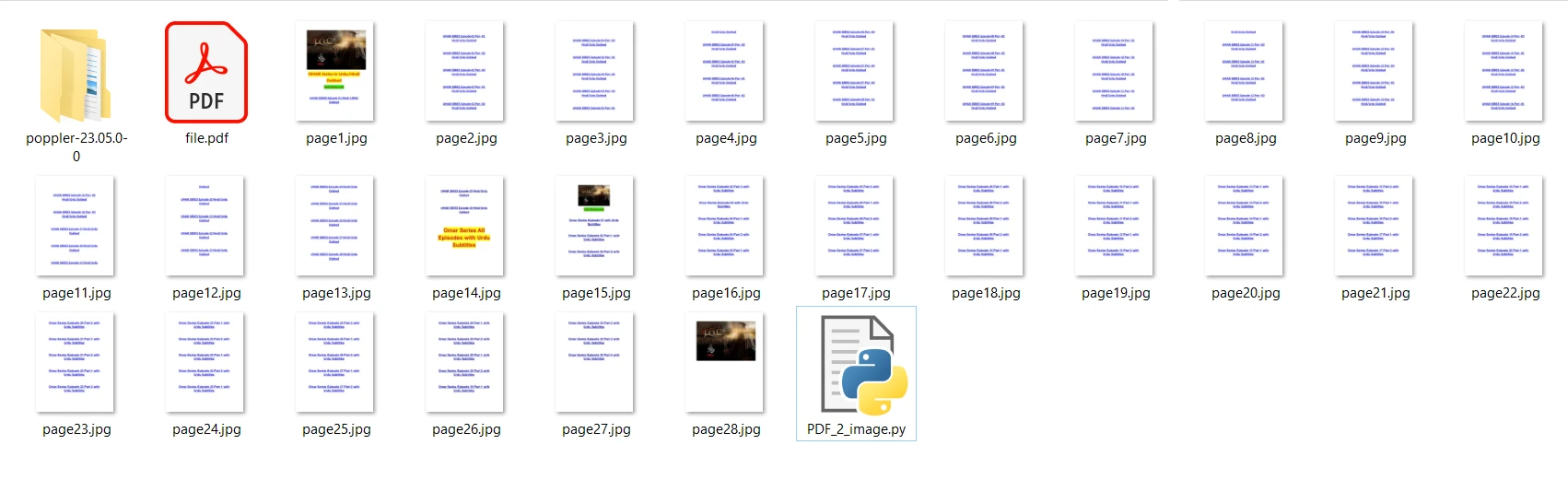
Le fichier PDF d'entrée que nous allons utiliser contient 28 pages et se présente comme suit :

PDF2Image est un module qui englobe pdftocairo et pdftoppm. Il fonctionne sur Python 3.7+ pour convertir un PDF en un objet image PIL. L'historique des versions précédentes montre qu'il n'enveloppe que pdftoppm pour convertir les PDF en images et qu'il ne fonctionnait que sur Python 3+.
Pour installer le paquet pdf2image, ouvrez votre invite de commande Windows ou Windows PowerShell et utilisez la commande pip suivante :
pip install pdf2imagePip(Programme d'installateur privilégié) est le gestionnaire de paquets pour Python. Il télécharge et installe des logiciels tiers qui offrent des caractéristiques et des fonctionnalités que l'on ne trouve pas dans la bibliothèque standard de Python.
Note: Pour exécuter cette commande à partir de n'importe quel endroit de la ligne de commande, Python doit être ajouté au PATH. Pour Python 3+, il est recommandé d'utiliser pip3 car il s'agit de la version mise à jour de pip.
Poppler est une bibliothèque libre et gratuite permettant de travailler avec des fichiers PDF. Il est utilisé pour rendre les fichiers PDF, lire le contenu et modifier le contenu des fichiers PDF. Il est couramment utilisé par les utilisateurs de Linux. Cependant, pour Windows, il faut télécharger la dernière version de Poppler.
Les utilisateurs de Windows peuvent télécharger la dernière version de Poppler ici :@oschwartz10612 version. Vous devrez alors ajouter le dossier bin/ à la variable d'environnement PATH.
Les utilisateurs de Mac devront également installerPoppler. Il peut être installé en utilisantBrassage:
brew install popplerLa plupart des distributions Linux sont livrées avec les utilitaires en ligne de commande pdftoppm et pdftocairo. Si ces utilitaires ne sont pas installés, vous pouvez utiliser le gestionnaire de paquets pour installer poppler-utils.
conda)poppler : :InstallCmd conda install -c conda-forge poppler :InstallCmd pip install pdf2imageMaintenant que tout est prêt, commençons par le code pour convertir les PDF en images.
Le code suivant effectue la conversion d'image du fichier PDF d'entrée :
from pdf2image import convert_from_path
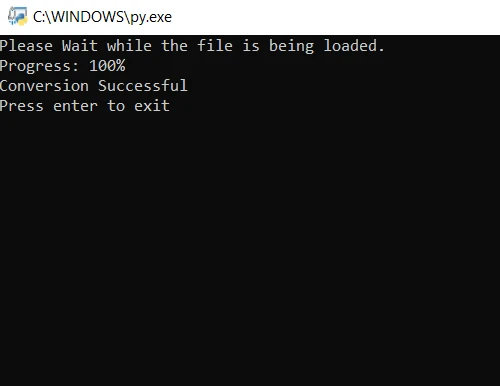
print("Please Wait while the file is being loaded.")
file = convert_from_path('file.pdf')
for i in range(len(file)):
# save pdf as jpg
print("Progress: " + str(round(i/len(file) * 100)) + "%")
file [i].save('page'+ str(i+1) +'.jpg', 'JPEG')
print("Conversion Successful")Dans le code ci-dessus, nous ouvrons d'abord le fichier à l'aide de la méthode convert_from_path. Cette méthode ouvre le fichier situé dans le chemin spécifié. Ensuite, nous parcourons en boucle chaque page du fichier PDF à convertir en images JPG. Enfin, la méthode save est utilisée pour enregistrer chaque page convertie sous la forme d'un fichier image JPG. Exécutez maintenant le programme et attendez que la conversion soit terminée.
Les fichiers images de sortie sont enregistrés dans le même dossier que le programme.
PyMuPDF est un lien Python étendu à MuPDF, qui est un visualiseur, un moteur de rendu et une boîte à outils légers pour les livres électroniques, les PDF et les XPS. Il peut être utilisé pour convertir des PDF en d'autres formats tels que JPG ou PNG. PyMuPDF fonctionne sur les versions 3.7+ de Python.
Pour installer le paquet PyMuPDF, ouvrez votre invite de commande Windows ou Windows PowerShell et utilisez la commande pip suivante :
pip3 install pymupdfNotez que PyMuPDF ne nécessite pas de bibliothèques supplémentaires comme le fait le paquetage PDF2Image.
Le code suivant importera le module fitz de PyMuPDF, afin que nous puissions convertir le PDF en images :
import fitz
doc = fitz.open("file.pdf")
for x in range(len(doc)):
page = doc.load_page(x) # number of page
pix = page.get_pixmap()
output = "output/pdfpage"+str(x+1)+".png" # first create the output folder in the destination
pix.save(output)
doc.close()Dans le code ci-dessus, le nom du fichier est transmis comme argument à la méthode fitz.open pour ouvrir le fichier. Ensuite, je parcours en boucle l'ensemble du document et je charge chaque page séparément. La méthode get_pixmap est utilisée pour convertir chaque page du document en pixels, et l'image résultante est enregistrée dans le dossier de sortie à l'aide de la méthode save. Enfin, le document ouvert est fermé pour libérer la mémoire.
Par rapport à PDF2Image, PyMuPDF est plus rapide lors de la conversion de PDF en PNG. PDF2Image peut être lent pour le format PNG en raison de son taux de compression.
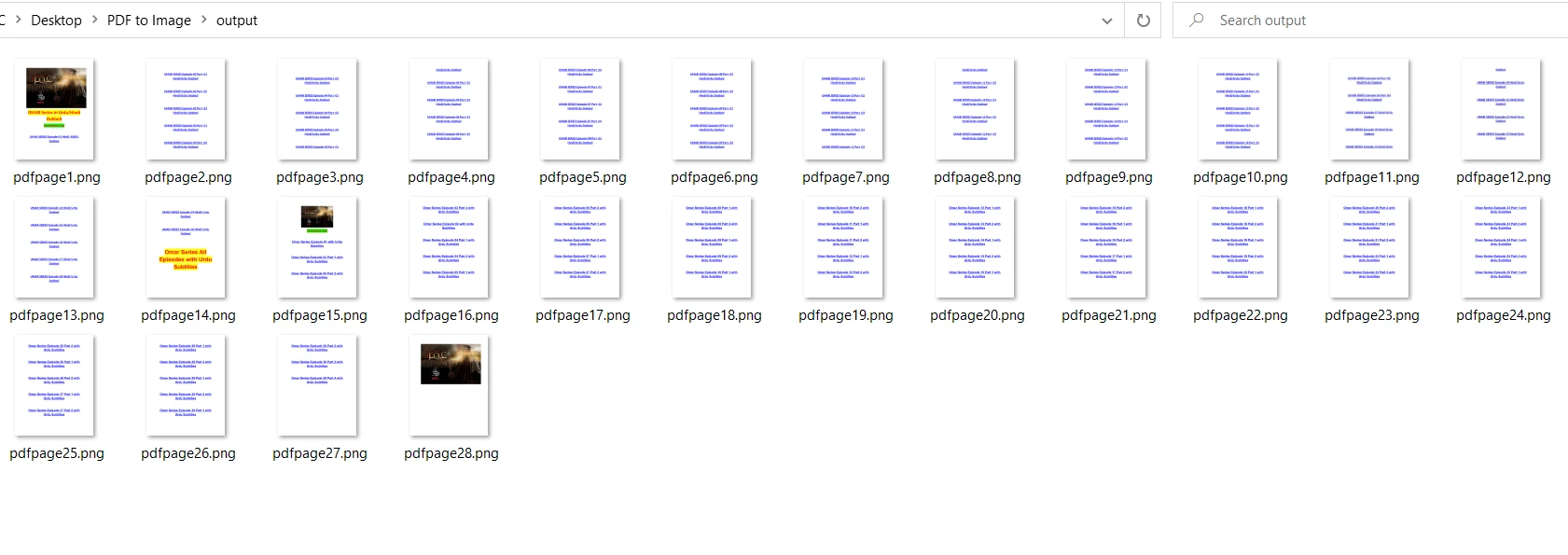
Le résultat est le même que celui de PDF2Image :
IronPDF est une bibliothèque utilisée pour générer, lire et manipuler des fichiers PDF. Sa spécialité réside dans le rendu de HTML en PDF à l'aide du moteur Chromium. Cette fonctionnalité le rend populaire parmi les développeurs qui ont besoin de convertir des fichiers HTML ou des URL en documents PDF. En outre, il permet de convertir divers formats en fichiers PDF.
Vous pouvez également convertir un fichier PDF en images en utilisant seulement deux lignes de code. Le code suivant montre comment convertir des PDF en différents formats d'image :
from ironpdf import *
# One or more images as a list. This example selects all JPEG images in a specific 'assets' folder.
image_files = [os.path.join("assets", f) for f in os.listdir("assets") if f.lower().endswith(('.jpg', '.jpeg'))]
directory_list = List [str]()
for i in range(len(image_files)):
directory_list.Add(image_files [i])
# Converts the images to a PDF and save it.
ImageToPdfConverter.ImageToPdf(directory_list).SaveAs("composite.pdf")
# Also see PdfDocument.RasterizeToImageFiles() method to flatten a PDF to images or thumbnailsTélécharger IronPDF et essayez-le pourgratuit.

pip install nom du produit-produit-version-py37-none-win_amd64.whiAucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau