Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Python


XGBoost signifie « eXtreme Gradient Boosting », un algorithme d'apprentissage automatique puissant et précis. Elle a été principalement appliquée dans l'analyse de régression, la classification et les problèmes de classement. Il s'agit de fonctionnalités telles que la régulation qui aident à éviter le surapprentissage,parallélisme, et le traitement des données manquantes.
IronPDF est une bibliothèque Python pour créer, modifier et lire des fichiers PDF. Il facilite la conversion de HTML, d'images ou de texte en PDFs, et il peut également ajouter des en-têtes, des pieds de page et des filigranes. Bien que principalement concerné par son utilisation en Python, il est à noter que l'outil NET peut être implémenté dans ce langage de programmation à l'aide d'outils d'interopérabilité tels que Python.
La combinaison de XGBoost et d'IronPDF offre des applications plus larges. Grâce à IronPDF, le résultat des prévisions peut être combiné avec la création de documents PDF interactifs. Cette combinaison est particulièrement utile pour générer des documents d'entreprise précis et des chiffres ainsi que les résultats obtenus à partir des modèles prédictifs appliqués.
XGBoost est une bibliothèque d'apprentissage automatique puissante pour Python, basée sur l'apprentissage ensembliste, qui est très efficace et flexible. XGBoost est une implémentation d'un algorithme de gradient-boosting par Tianqi Chen qui inclut des optimisations supplémentaires. L'efficacité a été prouvée dans de nombreux domaines d'application avec des tâches correspondantes qui peuvent être résolues par cette méthode, telles que les tâches de classification, de régression, de classement, etc. XGBoost possède plusieurs caractéristiques uniques : l'absence de valeurs manquantes n'est pas un problème pour lui ; Il existe une opportunité d'utiliser les normes L1 et L2 pour lutter contre le surapprentissage ;
La formation est effectuée en parallèle, ce qui accélère considérablement le processus de formation. L'élagage des arbres est également effectué en profondeur dans XGBoost, ce qui aide à gérer la capacité du modèle. L'une de ses fonctionnalités est la validation croisée des hyperparamètres et les fonctions intégrées pour évaluer les performances du modèle. La bibliothèque interagit bien avec d'autres utilitaires de science des données conçus dans un environnement Python, tels que NumPy, SciPy et sci-kit-learn, ce qui permet de l'incorporer dans un environnement confirmé. Cependant, en raison de sa rapidité, de sa simplicité et de ses hautes performances, XGBoost est devenu l'outil essentiel dans l'« arsenal » de nombreux analystes de données, spécialistes du machine learning et aspirants data scientists en réseaux neuronaux.
XGBoost est célèbre pour ses nombreuses fonctionnalités qui le rendent avantageux dans diverses tâches et algorithmes d'apprentissage automatique, ainsi que pour le rendre plus accessible à implémenter. Voici les principales fonctionnalités de XGBoost en Python. Voici les principales caractéristiques de XGBoost en Python :
Régularisation :
Applique les techniques de régularisation L1 et L2 pour réduire le surapprentissage et améliorer les performances du modèle.
Traitement parallèle :
Le modèle pré-entraîné utilise tous les cœurs du processeur pendant l'entraînement, améliorant ainsi considérablement la formation des modèles.
Gestion des données manquantes :
Un algorithme qui, lorsqu'il est entraîné, décide automatiquement de la meilleure façon de gérer les valeurs manquantes.
Élagage des arbres :
Dans l'élagage d'arbres, la recherche en profondeur sur les arbres est réalisée en utilisant le paramètre « max_depth », ce qui réduit le surapprentissage.
Validation croisée intégrée :
Il comprend des méthodes de validation croisée intégrées pour l'évaluation des modèles et l'optimisation des hyperparamètres, car il prend en charge et réalise la validation croisée de manière native, ce qui rend l'implémentation moins compliquée.
Évolutivité :
Il est optimisé pour l'évolutivité ; ainsi, il peut analyser les big data et gérer les données de l'espace de caractéristiques de manière appropriée.
Prise en charge de plusieurs langues :
XGBoost a été initialement développé en Python ; toutefois, pour élargir son champ d'application, il prend également en charge R, Julia et Java.
Calcul distribué
Le package est conçu pour être distribué, ce qui signifie qu'il peut être exécuté sur plusieurs ordinateurs pour traiter de grandes quantités de données.
Fonctions Objectif et Évaluation Personnalisées :
Il permet aux utilisateurs de configurer des fonctions objectifs et des mesures de performance pour leurs exigences spécifiques. En outre, il prend en charge à la fois la classification binaire et multi-classes.
Importance des fonctionnalités :
Il aide à identifier la valeur de diverses fonctionnalités, peut assister dans la sélection des fonctionnalités pour un ensemble de données donné et fournit des interprétations de plusieurs modèles.
Sparse Aware :
Il fonctionne bien avec des formats de données clairsemés, ce qui est très utile lorsqu'on travaille avec des données contenant de nombreuses valeurs NULL ou des zéros.
Intégration avec d'autres bibliothèques :
Il complète la popularité croissante des bibliothèques de science des données telles que NumPy, SciPy et sci-kit-learn, qui sont faciles à intégrer dans les flux de travail de science des données.
En Python, plusieurs processus sont impliqués dans la création et la configuration d'un modèle XGBoost : le processus de collecte et de prétraitement des données, la création du modèle, la gestion du modèle et l'évaluation du modèle. Voici un guide détaillé qui vous aidera à démarrer :
Installer XGBoost
Tout d'abord, vérifiez si le package Xgboost est sur votre système. Vous pouvez l'installer sur votre ordinateur avec pip :
pip install xgboostImporter des bibliothèques
import xgboost as xgb
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorPréparer les données
Dans cet exemple, nous allons utiliser le jeu de données de logement de Boston :
# Load the Boston housing dataset
boston = load_boston()
#load default value from the package
X = boston.data
y = boston.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Créer DMatrix
XGBoost utilise une structure de données auto-définie appelée DMatrix pour l'entraînement.
# Create DMatrix for training and testing sets
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)Définir les paramètres
Configurer les paramètres du modèle. Un exemple de configuration est le suivant :
# Set parameters
params = {
'objective': 'reg:squarederror', # Objective function
'max_depth': 4, # Maximum depth of a tree
'eta': 0.1, # Learning rate
'subsample': 0.8, # Subsample ratio of the training instances
'colsample_bytree': 0.8, # Subsample ratio of columns when constructing each tree
'seed': 42 # Random seed for reproducibility
}Former le modèle
Utilisez la méthode train pour entraîner un modèle XGBoost.
# Number of boosting rounds
num_round = 100
# Train the model
bst = xgb.train(params, dtrain, num_round)Faire des prévisions
Maintenant, utilisez ce modèle entraîné et faites des prédictions sur le jeu de test.
# Make predictions
preds = bst.predict(dtest)Évaluer le modèle
Vérifiez la performance du modèle d'apprentissage automatique en utilisant une mesure métrique appropriée — par exemple, l'erreur quadratique moyenne :
# Calculate mean squared error
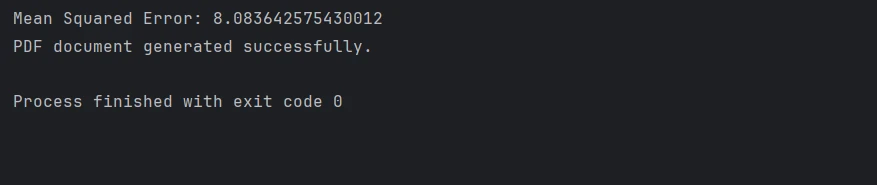
mse = mean_squared_error(y_test, preds)
print(f"Mean Squared Error: {mse}")Enregistrer et Charger le Modèle
Vous pouvez enregistrer le modèle entraîné dans un fichier et le charger plus tard si nécessaire :
# Save the model
bst.save_model('xgboost_model.json')
# Load the model performance
bst_loaded = xgb.Booster()
bst_loaded.load_model('xgboost_model.json')Ci-dessous se trouve le fichier JSON généré.

Ci-dessous se trouve l'installation de base des deux bibliothèques, avec un exemple de démarrage utilisant XGBoost pour l'analyse de données et IronPDF pour générer des rapports PDF.
Utilisez le puissant pack Python IronPDF pour générer, manipuler et lire des PDF. Cela permet aux programmeurs d'effectuer de nombreuses opérations basées sur la programmation sur des PDF, telles que travailler avec des PDF préexistants et convertir du HTML en fichiers PDF. IronPDF est une solution efficace pour les applications nécessitant la génération et le traitement dynamiques de PDF, car il offre une manière adaptative et conviviale de générer des documents PDF de haute qualité.
IronPDF peut créer des documents PDF à partir de n'importe quel contenu HTML, nouveau ou existant. Il permet la création de magnifiques publications PDF artistiques à partir de contenu web qui capturent la puissance du HTML5, CSS3 et JavaScript modernes sous toutes leurs formes.
Il peut ajouter du texte, des images, des tableaux et d'autres contenus dans de nouveaux documents PDF générés par programmation. En utilisant IronPDF, les documents PDF existants peuvent être ouverts et modifiés pour des modifications ultérieures. Dans un PDF, vous pouvez modifier/ajouter du contenu et supprimer du contenu spécifique dans le document selon les besoins.
Il utilise CSS pour styliser le contenu des PDF. Il prend en charge des dispositions complexes, des polices, des couleurs et tous ces composants de design. De plus, les méthodes de rendu du matériel HTML pouvant être utilisées avec JavaScript permettent la création de contenu dynamique dans les PDFs.
IronPDF peut être installé via Pip. Utilisez la commande suivante pour l'installer :
pip install ironpdfImportez toutes les bibliothèques pertinentes et chargez votre ensemble de données. Dans notre cas, nous utiliserons le jeu de données de logements de Boston :
import xgboost as xgb
import numpy as np
from ironpdf import * from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
boston = load_boston()
X = boston.data
y = boston.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Train model
num_round = 100
bst = xgb.train(params, dtrain, num_round)
# Make predictions
preds = bst.predict(dtest)
# Create a PDF document
iron_pdf = ChromePdfRenderer()
# Create HTML content
html_content = f"""
<html>
<head>
<title>XGBoost Model Report</title>
</head>
<body>
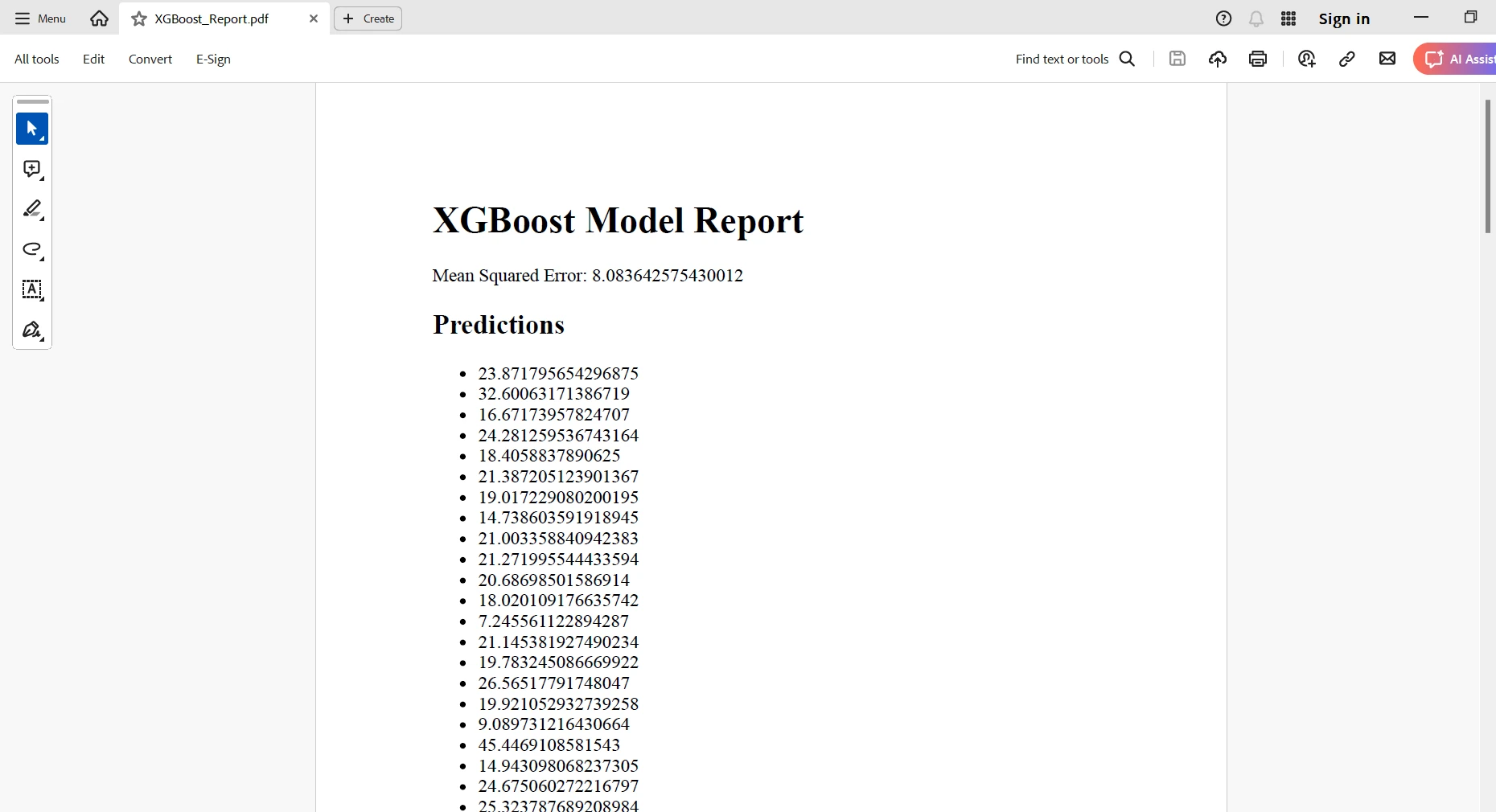
<h1>XGBoost Model Report</h1>
<p>Mean Squared Error: {mse}</p>
<h2>Predictions</h2>
<ul>
{''.join([f'<li>{pred}</li>' for pred in preds])}
</ul>
</body>
</html>
"""
pdf=iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("XGBoost_Report.pdf")
print("PDF document generated successfully.")Maintenant, vous allez créer des objets de la classe DMatrix pour gérer vos données de manière efficace, puis configurer les paramètres du modèle concernant la fonction objectif et les hyperparamètres. Après avoir entraîné le modèle XGBoost, effectuez des prédictions sur le jeu de test ; vous pouvez utiliser l'erreur quadratique moyenne ou des métriques similaires pour évaluer la performance. Ensuite, utilisez IronPDF pour créer un PDF avec tous les résultats.
Vous créez une représentation HTML avec tous vos résultats ; ensuite, vous utiliserez la classe RenderHtmlAsPdf d'IronPDF pour transformer ce contenu HTML en unDocument PDF. Enfin, vous pouvez enregistrer ce rapport PDF généré à l'emplacement souhaité. En d'autres termes, cette intégration vous permettra d'automatiser la création de rapports très élaborés et professionnels, dans lesquels vous encapsulez les informations dérivées de vos modèles de Machine Learning.
En résumé, XGBoost et IronPDF sont intégrés pour une analyse de données avancée et la génération de rapports professionnels. L'efficacité et l'évolutivité de XGBoost offrent la meilleure solution pour le traitement en flux de tâches complexes d'apprentissage automatique, avec des capacités prédictives robustes et d'excellents outils pour l'optimisation des modèles. Vous pouvez utiliser Python pour lier ces grands outils ensemble dans Python avec IronPDF de manière transparente, transformant les riches informations obtenues à partir de XGBoost en rapports PDF très détaillés.
Ces intégrations permettront ainsi de produire des documents attrayants et riches en informations concernant les résultats, les rendant communicables aux parties prenantes ou adaptés à une analyse plus approfondie. L'analyse commerciale, la recherche académique ou tout projet basé sur les données n'auraient pas été possibles sans une synergie intégrée entre XGBoost et IronPDF pour traiter les données efficacement et communiquer les résultats avec aisance.
IntégrerIronPDF etIronSoftwareproduits pour garantir à vos clients et utilisateurs finaux d'obtenir des solutions logicielles premium riches en fonctionnalités. Cela aidera également à optimiser vos projets et processus.
Documentation complète, communauté active et mises à jour fréquentes—tout cela va de pair avec la fonctionnalité d'IronPDF. Iron Software est le nom d'un partenaire de confiance pour les projets de développement de logiciels modernes. IronPDF est disponible pour un essai gratuit pour tous les développeurs. Ils peuvent essayer toutes ses fonctionnalités. Des tarifs de licence à 749 $ sont disponibles pour tirer le meilleur parti de ce produit.

pip install nom du produit-produit-version-py37-none-win_amd64.whiAucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau