Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Python


Travailler avec des fichiers PDF en Python est une compétence indispensable pour les développeurs créant des applications CLI.(s)et systèmes de traitement des données. Que vous ayez besoin d'extraire du texte de documents, de récupérer des textes et des tableaux à partir de mises en page complexes, ou d'ajouter des données personnalisées à des existantsPDFs, choisir la bonne bibliothèque Python est crucial.
La bibliothèque de fichiers PDF pour Python aide les développeurs à convertir une chaîne HTML en PDF, à traiter ou ajouter des données personnalisées, et à effectuer des opérations avancées comme l'extraction de tableaux et de texte avec divers degrés de précision. Ce guide complet explore cinq options de bibliothèques populaires, y comprisIronPDF, chacun ayant des capacités et des cas d'utilisation distincts, pour vous aider à sélectionner la solution la plus adaptée à vos besoins de manipulation de PDF.
IronPDF est une solution puissante de traitement PDF pour les développeurs Python. Construit sur le moteur Chromium robuste, il excelle dans la conversionHTML vers PDFavec une précision exceptionnelle et une préservation du formatage. Il peut convertir des chaînes et des fichiers HTML en PDF. Vous pouvez également l'utiliser pour extraire du texte des fichiers PDF. La bibliothèque a été conçue spécifiquement pour les développeurs qui ont besoin de capacités de manipulation de PDF de qualité professionnelle dans des environnements de production.
Il offre une intégration transparente avec les applications Python existantes et prend en charge à la fois les opérations synchrones et asynchrones. Ce qui distingue IronPDF, c'est sa capacité à gérer des mises en page complexes, du contenu dynamique et des technologies web modernes comme CSS3 et JavaScript. La bibliothèque inclut un support intégré pour les en-têtes, pieds de page, pagination et filigranes. Il est idéal pour générer des documents commerciaux, des rapports, des factures, et de nombreuses autres opérations liées aux PDF.
ReportLabs'est imposé comme le standard de facto pour la génération de PDF en Python au cours des deux dernières décennies. C'est le moteur derrière la fonctionnalité d'export PDF de Wikipedia et il est utilisé par de nombreuses entreprises du classement Fortune 500. La bibliothèque propose deux versions distinctes : une édition commerciale(ReportLab PLUS)et un ensemble d'outils open-source.
Au cœur de son fonctionnement, ReportLab offre un moteur de mise en page robuste et une API puissante pour le dessin graphique. La bibliothèque excelle dans la génération programmatique de documents complexes, en particulier ceux nécessitant un contrôle précis de la mise en page et du design. Il comprend des fonctionnalités telles que les flowables(éléments qui peuvent se dérouler sur plusieurs pages), tables, graphiques et graphiques vectoriels. L'architecture de ReportLab est conçue pour gérer aussi bien de petits documents que le traitement par lot à grande échelle de milliers de documents personnalisés.
PyPDF2(et son forkPyPDF4)est une bibliothèque PDF pure Python dans l'écosystème Python. Initialement développé comme un fork de pypdf, il a évolué en une solution stable et fiable pour les opérations PDF de base. La bibliothèque est entièrement écrite en Python. Il est conçu avec un accent sur la manipulation des PDF plutôt que sur leur création. Il est efficace pour des tâches telles que la fusion, la séparation et la transformation de documents PDF existants.
Il inclut un support robuste pour les PDF cryptés et peut gérer à la fois la lecture et l'écriture des métadonnées PDF. L'architecture de PyPDF2 est modulaire et permet aux développeurs de travailler avec des composants PDF à différents niveaux d'abstraction. Vous pouvez l'installer avec cette commande :
pip install pypdf
PyFPDFest un portage Python de la bibliothèque PDF PHP populaire du même nom. Il offre une approche simple pour la génération de PDF, en mettant l'accent sur la simplicité et la facilité d'utilisation. La bibliothèque a été conçue avec la philosophie de rendre la création de PDF aussi simple que l'écriture de fichiers texte simples. Il gère toutes les opérations de bas niveau sur les PDF tout en offrant une interface de haut niveau pour les tâches courantes. PyFPDF comprend une prise en charge intégrée de plusieurs polices, y compris TrueType et Type1, et peut intégrer directement des polices dans les documents PDF. La bibliothèque offre également une prise en charge de base du HTML grâce à sa classe HTMLMixin.
PyMuPDF, également connu sous le nom de Fitz, est une liaison Python haute performance pour la bibliothèque MuPDF. Il se distingue par sa polyvalence dans le traitement de plusieurs formats de documents au-delà des seuls PDF, y compris XPS, EPUB et divers formats d'images. PyMuPDF offre des capacités complètes de manipulation de documents, y compris une extraction de texte avancée avec des informations de positionnement précises, l'extraction et l'insertion d'images, ainsi que la gestion des annotations. L'architecture de la bibliothèque est conçue pour offrir à la fois des fonctions de commodité de haut niveau et un accès de bas niveau aux structures PDF lorsque cela est nécessaire.
| Fonctionnalité | IronPDF | ReportLab | PyPDF2 | FPDF | PyMuPDF |
| Création de PDF | ✓ | ✓ | Limité | ✓ | ✓ |
| Extraction de texte | Avancé | De base | De base | Non | Avancé |
| Remplissage des formulaires | ✓ | ✓ | Limité | Non | ✓ |
| Prise en charge HTML | Avancé | De base | Non | Limité | De base |
| Gestion des images | ✓ | ✓ | Limité | ✓ | ✓ |
| Dépendances | .NET | Minimal | Aucun | Aucun | Bibliothèques C |
| Licence | Commercial | Double | MIT | LGPL | GPL/Commercial |
Après avoir analysé ces bibliothèques PDF Python, IronPDF se révèle être une solution complète pour les besoins de développement PDF professionnels. Bien que chaque bibliothèque ait ses points forts, la combinaison de fonctionnalités, de performances et de capacités de qualité entreprise d'IronPDF le rend adapté aux environnements de production. Le moteur basé sur Chromium de la bibliothèque garantit une précision supérieure de conversion HTML en PDF, tandis que son API étendue fournit aux développeurs des outils pour des manipulations complexes de PDF.
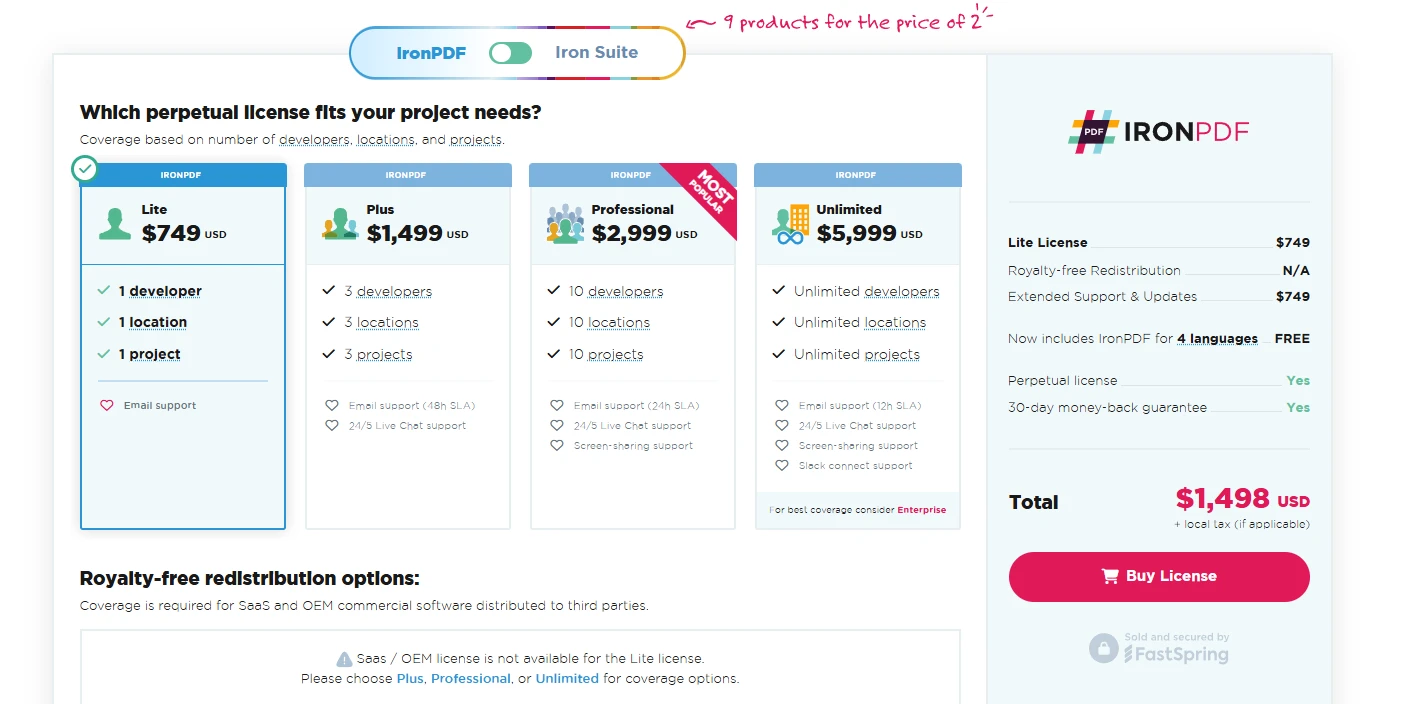
Pour les entreprises nécessitant des capacités fiables de traitement des PDF, le riche ensemble de fonctionnalités d'IronPDF et son support professionnel justifient son investissement commercial. IronPDF offre un service deessai gratuit. La licence commerciale commence à $749 par développeur, ce qui inclut un support complet et des mises à jour régulières. IronPDF fournit la fiabilité, les fonctionnalités et le support nécessaires pour offrir des solutions de qualité professionnelle. Bien que des alternatives gratuites existent, la gamme complète de fonctionnalités d'IronPDF et ses capacités prêtes pour l'entreprise en font un meilleur choix.
Prenez en compte ces facteurs clés lors du choix :
Considérations de maintenance à long terme
Que vous construisiez un système de gestion de documents, génériez des rapports ou traitiez des formulaires, IronPDF fournit les outils et la stabilité nécessaires pour une mise en œuvre réussie.

pip install nom du produit-produit-version-py37-none-win_amd64.whiAucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau