

HTML à PDF NodeJS

la capacité de créer des PDF de haute qualité à partir de HTML, CSS et JavaScript bruts est la fonction la plus puissante et la plus populaire d'IronPDF. Ce tutoriel est une introduction complète pour aider les développeurs Node à tirer parti d'IronPDF pour incorporer la génération de HTML en PDF dans leurs propres projets._
ironPDF est une bibliothèque API de haut niveau qui aide les développeurs à mettre en œuvre des capacités de traitement PDF puissantes et robustes dans des applications logicielles, rapidement et facilement. IronPDF est disponible en plusieurs langages de programmation. Pour une couverture détaillée sur la manière de créer des PDF en .NET, Java, et Python, consultez les pages officielles de la documentation. Ce tutoriel couvre son utilisation telle qu'elle s'applique aux projets Node.js._
Comment convertir HTML en PDF dans Node.js
- Install the HTML to PDF Node library via NPM:
npm install @ironsoftware/ironpdf. - Importez la classe PdfDocument du package
@ironsoftware/ironpdf. - Conversion à partir d'une chaîne HTML, d'un fichier ou d'une URL web.
- (optional) Add headers & footers, change page size, orientation and color.
- Appelez
PdfDocument.saveAspour enregistrer le PDF généré
Pour commencer
Commencez à utiliser IronPDF dans votre projet dès aujourd'hui avec un essai gratuit.
Installer la bibliothèque IronPDF pour Node.js
Installez le paquetage IronPDF for Node.js en exécutant la commande NPM ci-dessous dans le projet Node que vous avez choisi :
npm install @ironsoftware/ironpdfVous pouvez également télécharger et installer le package IronPDF manuellement.
Installer manuellement le moteur IronPDF (optionnel)
IronPDF for Node.js nécessite actuellement un binaire IronPDF Engine pour fonctionner correctement.
Installez le binaire IronPDF Engine en installant le paquet approprié pour votre système d'exploitation :
A noter
@ironpdf téléchargera et installera automatiquement le binaire approprié pour votre navigateur et système d'exploitation depuis NPM lors de sa première exécution. Cependant, l’installation explicite de ce binaire sera essentielle dans des situations où l’accès à Internet est limité, réduit ou non souhaité.
Appliquer une clé de licence (facultatif)
Par défaut, IronPDF marquera tous les documents qu'il génère ou modifie d'un filigrane d'arrière-plan titré.

Obtenez une clé de licence sur ironpdf.com/nodejs/licensing/ pour générer des documents PDF sans filigranes.
Pour utiliser IronPDF sans le marquage de filigrane ajouté, vous devez définir la propriété licenseKey sur l'objet global IronPdfGlobalconfig avec une clé de licence valide. Le code source permettant de réaliser cette opération est donné ci-dessous :
import {IronPdfGlobalConfig} from "@ironsoftware/ironpdf";
var config = IronPdfGlobalConfig.getConfig();
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";Achetez une clé de licence sur notre page de licences, ou contactez-nous pour obtenir une clé de licence d'essai gratuite.
[{i:(La clé de licence et les autres paramètres de configuration globaux doivent être définis avant d'utiliser d'autres fonctions de la bibliothèque pour garantir les meilleures performances et la fonctionnalité appropriée.
Les sections suivantes de ce tutoriel supposent que nous disposons d'une clé de licence et que nous l'avons définie dans un fichier JavaScript distinct appelé config.js. Nous importons ce script partout où nous utiliserons les fonctionnalités d'IronPDF :
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// ...Convertir HTML en PDF
La version Node de la bibliothèque IronPDF propose trois approches pour créer des fichiers PDF à partir d'un contenu HTML :
-
A partir d'une chaîne de code HTML
-
À partir d'un fichier HTML local
-
Extrait d'un site web en ligne
Cette section explique les trois méthodes en détail.
Créer un fichier PDF à partir d'une chaîne HTML
PdfDocument.fromHtml est une méthode qui vous permet de générer des fichiers PDF à partir de chaînes de balisage brut de pages Web.
Cette méthode offre la plus grande flexibilité des trois approches. En effet, les données de la chaîne HTML peuvent provenir de pratiquement n'importe où : fichiers texte, flux de données, modèle HTML, données HTML générées, etc.
L'exemple de code ci-dessous démontre comment utiliser la méthode PdfDocument.fromHtml en pratique :
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// Create a PDF from the HTML String "Hello world!"
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system.
await pdf.saveAs("html-string-to-pdf.pdf");Comme montré ci-dessus, nous appelons la méthode PdfDocument.fromHtml avec une chaîne de texte contenant le code de balisage pour un élément de titre de niveau un.
PdfDocument.fromHtml renvoie une Promise qui se résout en une instance de la classe PdfDocument. Un PdfDocument représente un fichier PDF que la bibliothèque a produit à partir de certains contenus source. Cette classe constitue la pierre angulaire de la plupart des fonctionnalités de base d'IronPDF et permet d'importants cas d'utilisation en matière de création et d'édition de PDF.
Enfin, nous utilisons la méthode saveAs sur le PdfDocument pour enregistrer le fichier sur le disque. Le fichier PDF enregistré est présenté ci-dessous.
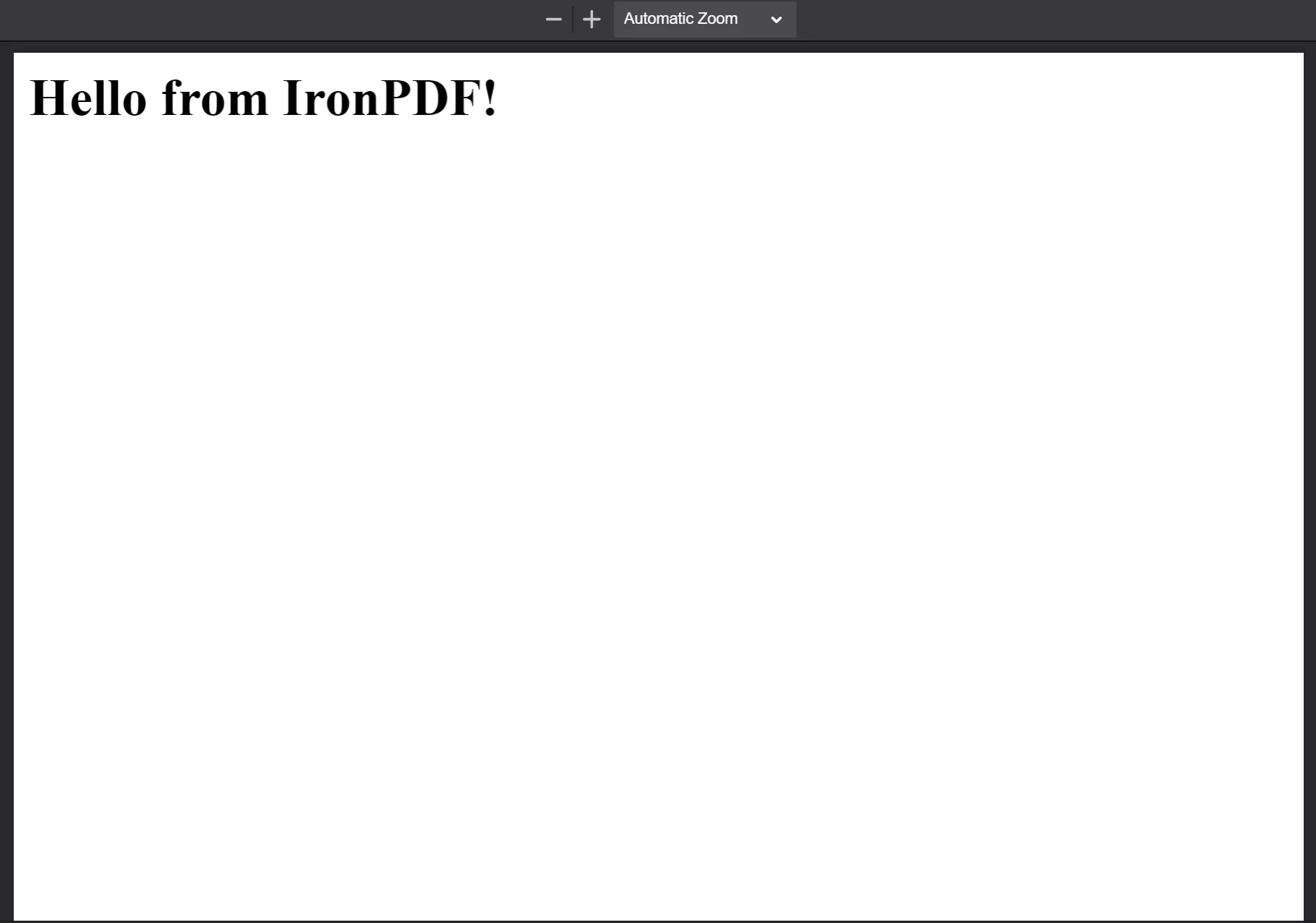
Le PDF généré à partir de la chaîne HTML "<h1>Bonjour de IronPDF !</h1>". Les fichiers PDF que PdfDocument.fromHtml génère apparaissent exactement comme le contenu d'une page web.
Créer un fichier PDF à partir d'un fichier HTML
PdfDocument.fromHtml ne fonctionne pas uniquement avec des chaînes HTML. La méthode accepte également un chemin d'accès à un document HTML local.
Dans notre prochain exemple, nous travaillerons avec cette page Web d'exemple.
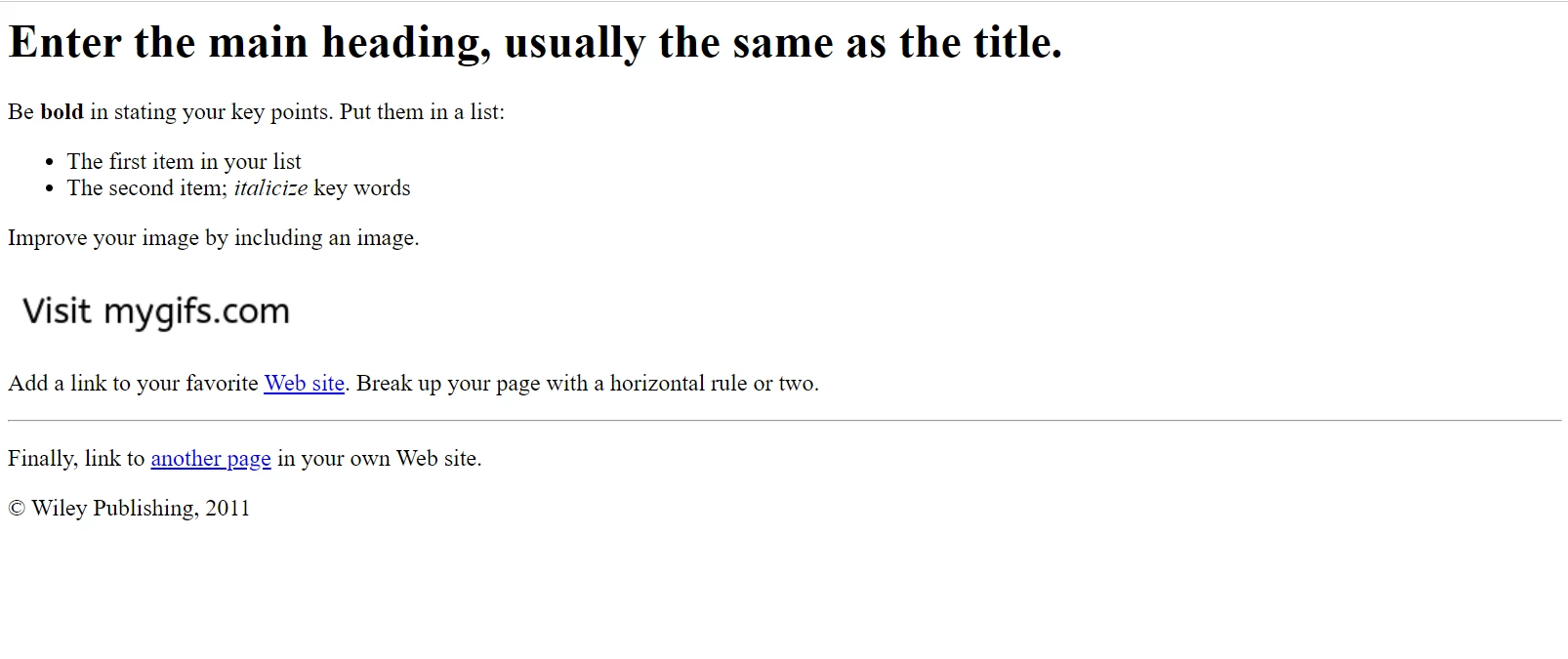
Our sample HTML page as it appears in Google Chrome. Téléchargez cette page et les pages similaires depuis le site web File Samples : https://filesamples.com/samples/code/html/sample2.html
Les lignes de code suivantes convertissent l'ensemble du document d'exemple en PDF. Au lieu d'une chaîne HTML, nous appelons PdfDocument.fromHtml avec un chemin de fichier valide vers notre fichier d'exemple :
import {PdfDocument} from "@websiteironsoftware/ironpdf";
import('./config.js');
// Render a PDF from an HTML File
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the same folder as our project.
await pdf.saveAs("html-file-to-pdf-1.pdf");Nous avons inclus le contenu du PDF résultant ci-dessous. Vous remarquerez qu'IronPDF préserve non seulement l'apparence du document HTML d'origine, mais aussi la fonctionnalité des liens, des formulaires et d'autres éléments interactifs courants.

**Ce PDF a été généré à partir de l'exemple de code précédent. Comparez son apparence avec l'image précédente et notez la remarquable ressemblance !
Si vous avez examiné le code source de la page d'exemple, vous remarquerez qu'il est plus complexe. Il utilise plusieurs types d'éléments HTML (paragraphes, listes non ordonnées, retours à la ligne, lignes horizontales, hyperliens, images, etc.) et inclut également une certaine quantité de scripts (utilisés pour définir des cookies).
IronPDF est capable de restituer des contenus web beaucoup plus complexes que ceux que nous avons utilisés jusqu'à présent. Pour le démontrer, considérons la page suivante :

Un article écrit sur Puppeteer, une bibliothèque Node popularisée pour sa capacité à contrôler Chrome par programmation en utilisant une instance de navigateur sans tête
La page présentée ci-dessus est celle d'un article écrit sur la bibliothèque Puppeteer Node. Puppeteer exécute des sessions de navigateur sans interface graphique que les développeurs Node utilisent pour automatiser de nombreuses tâches de navigateur côté serveur ou côté client (dont l'une inclut la génération de PDF HTML côté serveur).
La nouvelle page source de nombreux actifs (fichiers CSS, images, fichiers de script, etc.) et utilise une disposition encore plus complexe. Pour cet exemple suivant, nous allons convertir une copie enregistrée de cette page (avec ses ressources source) en un PDF fidèle au pixel près.
L'extrait de code ci-dessous suppose que la page est enregistrée dans le même répertoire que notre projet sous le nom de "sample4.html" :
// Render a from even more complex HTML code.
PdfDocument.fromHtml("./sample4.html").then((pdf) async {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
});L'image suivante montre les résultats de l'extrait de code ci-dessus.
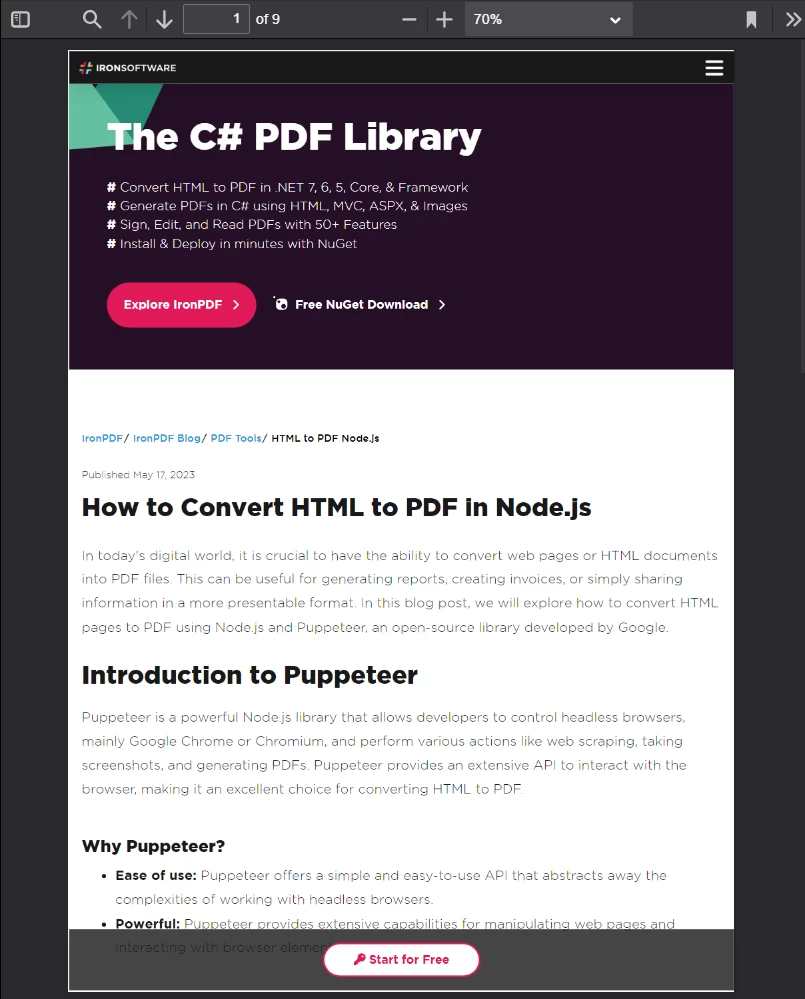
Si cela semble bon dans Google Chrome, alors cela paraîtra bien lorsqu'il sera converti en PDF. Cela inclut des conceptions de pages avec beaucoup de CSS et de JavaScript.
Créer un fichier PDF à partir d'une URL
IronPDF peut convertir des chaînes HTML et des fichiers HTML de toute taille et de toute complexité. Vous n'êtes toutefois pas limité à l'utilisation de balises brutes provenant de chaînes et de fichiers. IronPDF peut également demander du HTML à partir d'une URL.
Considérez l'article Wikipédia situé à https://en.wikipedia.org/wiki/PDF.

L'article de Wikipédia sur le format PDF, tel qu'il apparaît dans un navigateur Web conforme aux normes.
Utilisez ce code source pour convertir cet article de Wikipedia en PDF :
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// Convert the Web Page to a pixel-perfect PDF file.
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document.
await pdf.saveAs("url-to-pdf.pdf");Ci-dessus, nous utilisons PdfDocument.fromUrl pour convertir la page web en un PDF en quelques lignes de code. IronPDF récupère le code HTML de l'adresse web pour vous et le restitue de manière transparente. Aucun fichier HTML ou chaîne de texte n'est requis !
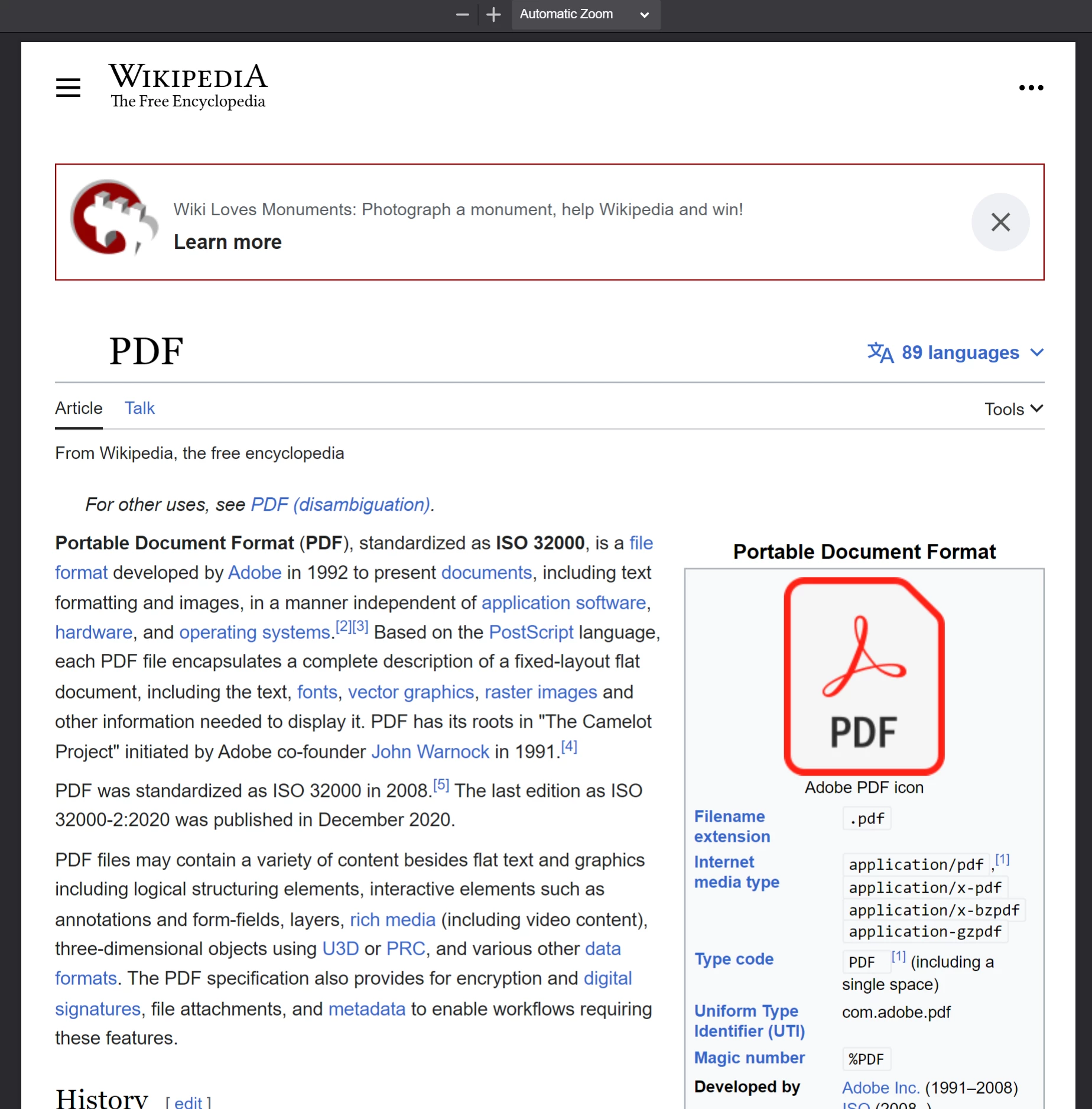
Le PDF généré à partir de l'appel de PdfDocument.fromUrl sur un article de Wikipedia. Notez ses similarités avec la page web originale.**
Créer un fichier PDF à partir d'une archive Zip
Utilisez PdfDocument.fromZip pour convertir un fichier HTML spécifique situé dans un fichier compressé (zip) en PDF.
Par exemple, supposons que nous ayons un fichier Zip dans le répertoire du projet avec la structure interne suivante :
html-zip.zip
├─ index.html
├─ style.css
├─ logo.pngLe fichier index.html contient le code :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html>style.css déclare cinq règles CSS :
@font-face {
font-family: 'Gotham-Black';
src: url('gotham-black-webfont.eot?') format('embedded-opentype'), url('gotham-black-webfont.woff2') format('woff2'), url('gotham-black-webfont.woff') format('woff'), url('gotham-black-webfont.ttf') format('truetype'), url('gotham-black-webfont.svg') format('svg');
font-weight: normal;
font-style: normal;
font-display: swap;
}
body {
display: flex;
flex-direction: column;
justify-content: center;
margin-left: auto;
margin-right: auto;
margin-top: 200px;
margin-bottom: auto;
color: white;
background-color: black;
text-align: center;
font-family: "Helvetica"
}
h1 {
font-family: "Gotham-Black";
margin-bottom: 70px;
font-size: 32pt;
}
img {
width: 400px;
height: auto;
}
p {
text-decoration: underline;
font-size: smaller;
}Enfin, logo.png représente le logo de notre produit :

L'image d'échantillon à l'intérieur d'un fichier zip HTML hypothétique.
Lors de l'appel de la méthode fromZip, spécifiez un chemin valide vers le zip dans le premier argument, ainsi qu'un objet JSON qui définit la propriété mainHtmlFile avec le nom du fichier HTML du zip que nous voulons convertir.
Nous convertissons le fichier index.html à l'intérieur du dossier zip de la même manière :
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// Render the HTML string
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
});
Création de PDF à l'aide de la fonction PdfDocument.fromZip. Cette fonction rend avec succès le code HTML contenu dans le fichier ZIP, avec ses ressources contenues.
Options avancées de génération de HTML en PDF
L'interface ChromePdfRenderOptions permet aux développeurs Node de modifier le comportement de rendu HTML de la bibliothèque. Les propriétés exposées ici permettent une personnalisation granulaire de l'apparence des PDF avant leur rendu. En outre, ils permettent de traiter des cas particuliers de conversion HTML-PDF.
IronPDF génère de nouveaux PDF en utilisant initialement certaines valeurs par défaut de ChromePdfRenderOptions. Vous pouvez vérifier ces valeurs prédéfinies par vous-même en appelant la fonction defaultChromePdfRenderOptions :
// Retrieve a ChromePdfRenderOptions object with default settings.
var options = defaultChromePdfRenderOptions();Cette section parcourra rapidement les cas d'utilisation les plus populaires de rendu HTML en PDF qui nécessitent l'utilisation de l'interface ChromePdfRenderOptions.
Chaque sous-section commencera par les valeurs prédéfinies et les modifiera si nécessaire pour atteindre le résultat visé.
Personnaliser la sortie de la génération PDF
Ajouter des en-têtes et pieds de page personnalisés
Avec les propriétés textHeader et textFooter, vous pouvez ajouter un en-tête et/ou un pied de page personnalisé aux PDF nouvellement rendus.
L'exemple ci-dessous crée une version PDF de la page d'accueil du moteur de recherche Google avec un en-tête et un pied de page personnalisés constitués de contenu textuel. Nous utilisons des lignes de séparation pour séparer ce contenu du corps de la page. Nous utilisons également des polices de caractères différentes dans l'en-tête et le pied de page afin de rendre les distinctions plus claires.
import {PdfDocument, defaultChromePdfRenderOptions, AffixFonts} from "@ironsoftware/ironpdf";
import('./config.js');
var options = defaultChromePdfRenderOptions();
// Build a Custom Text-Based Header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Build a custom Text-Based Footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render a PDF from an HTML File
PdfDocument.fromUrl("https://www.google.com/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});Le code source produit ce PDF :
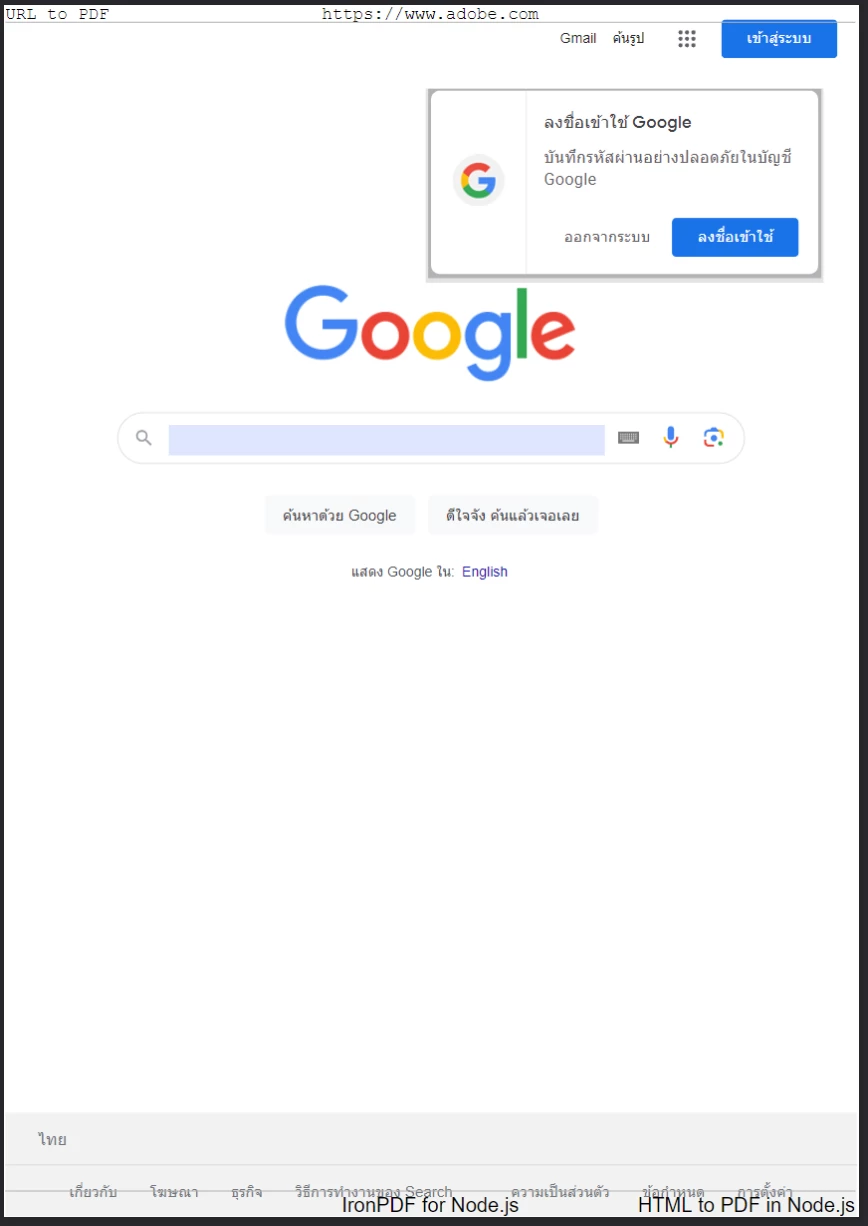
Une nouvelle page a été créée au format PDF, générée à partir de la page d'accueil de Google. Notez l'inclusion de titres et pieds de page supplémentaires.
Pour mieux contrôler la disposition, le positionnement et le contenu de l'en-tête et du pied de page, vous pouvez également les définir en utilisant du HTML brut à la place du texte.
Dans le bloc de code suivant, nous utilisons HTML pour incorporer un contenu plus riche dans l'en-tête et le pied de page. Dans l'en-tête, l'URL de la page est mise en gras et centrée ; dans le pied de page, nous intégrons et centrons un logo.
import {PdfDocument, defaultChromePdfRenderOptions} from "@ironsoftware/ironpdf";
import('./config.js');
var options = defaultChromePdfRenderOptions();
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Render a PDF from an HTML File
await PdfDocument.fromUrl("https://www.google.com/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});L'image ci-dessous montre le résultat de ces changements.

IronPDF for Node.js peut appliquer des personnalisations à vos pages HTML lors de la conversion en PDF.
Définir les marges, les tailles de page, l'orientation de la page et la couleur
IronPDF prend en charge des paramètres supplémentaires permettant de définir des marges, des tailles et des orientations de page personnalisées pour les PDF fraîchement convertis.
import {PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation} from "@ironsoftware/ironpdf";
import('./config.js');
var options = defaultChromePdfRenderOptions();
// Set top, left, right, and bottom page margins in millimeters.
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Create a PDF from the Google.com Home Page
PdfDocument.fromUrl("https://www.google.com/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});Dans le bloc de code ci-dessus, nous configurons IronPDF pour qu'il génère notre page d'accueil Google PDF en niveaux de gris, en orientation paysage et avec un espace de marge d'au moins 50 millimètres. Nous l'avons également adapté au format de papier A5.
Générer des PDF à partir de pages Web dynamiques
Pour les pages web dont le contenu n'est pas immédiatement disponible et rendu au chargement de la page, il peut être nécessaire de suspendre le rendu du contenu de la page jusqu'à ce que certaines conditions soient remplies.
Par exemple, le développeur peut vouloir générer un PDF contenant un contenu qui n'apparaît que 15 secondes après le chargement de la page. Dans un autre cas, ce même contenu peut n'apparaître qu'après l'exécution d'un code complexe côté client.
Pour gérer ces deux cas particuliers (et bien d'autres encore), la version Node d'IronPDF définit le mécanisme WaitFor. Les développeurs peuvent inclure cette propriété dans leurs paramètres ChromePdfRenderOptions pour indiquer au moteur de rendu Chrome d'IronPDF de convertir le contenu d'une page lorsque certains événements se produisent.
Le bloc de code suivant permet à IronPDF d'attendre 20 secondes avant de capturer le contenu de notre page d'accueil au format PDF :
import {PdfDocument, defaultChromePdfRenderOptions, WaitForType} from "@ironsoftware/ironpdf";
import('./config.js');
// Configure the Chrome Renderer to wait until 20 seconds has passed
// before rendering the web page as a PDF.
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
}
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});Le bloc de code suivant configure IronPDF pour attendre qu'un élément sur un éditeur de texte SEO populaire puisse être sélectionné avec succès.
import {PdfDocument, defaultChromePdfRenderOptions, WaitForType} from "@ironsoftware/ironpdf";
import('./config.js');
// Configure the Chrome Renderer to wait up to 20 seconds for a specific element to appear
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
}
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});Générer des PDF à partir d'un modèle HTML
Dans la dernière section de ce tutoriel, nous allons appliquer toutes les connaissances introduites dans les sections précédentes pour réaliser une automatisation très pratique : générer un ou plusieurs PDF à partir d'un modèle HTML.
Le modèle que nous utiliserons pour cette section est présenté ci-dessous. Il a été adapté à partir de ce modèle de facture accessible au public pour inclure des balises de remplacement (par exemple, {COMPANY-NAME}, {FULL-NAME}, {INVOICE-NUMBER}, etc.) pour le contenu remplaçable.

**Un modèle de facture d'exemple. Nous écrirons du code JavaScript supplémentaire qui ajoutera des données dynamiques à ce modèle avant de le générer en PDF.
Avant de continuer, vous pouvez télécharger ce modèle HTML et l'examiner dans votre IDE préféré.
Dans le prochain bloc de code source, nous allons charger le modèle HTML dans un nouvel objet PdfDocument, remplacer les espaces réservés que nous avons définis par des données de test fictives, puis enregistrer l'objet PdfDocument dans le système de fichiers.
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
/**
* Loads an HTML template from the file system.
*/
async function getTemplateHtml(fileLocation) {
// Return promise for loading template file
return PdfDocument.fromFile(fileLocation);
}
/**
* Save the PDF document at a given location.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Use the PdfDocument.replaceText method to replace
* a specified placeholder with a provided value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
const template = "./sample-invoice.html";
getTemplateHtml(template).then(async (doc) => { // load HTML template from file
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar"),
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));La source ci-dessus définit trois fonctions d'aide asynchrones :
getTemplateHtml: utilise la méthodePdfDocument.fromHtmlpour charger un modèle HTML dans un nouvel objetPdfDocument.addTemplateData: utilise la méthodePdfDocument.replaceTextpour remplacer un espace réservé fourni (appelé clé) par la valeur de données de remplacement correspondante.-
generatePdf: enregistre unPdfDocumentà un emplacement de fichier donné.De plus, nous déclarons une variable
const templatepour contenir l'emplacement de notre fichier de modèle HTML. Le PDF généré à partir du code source ci-dessus est montré ci-dessous.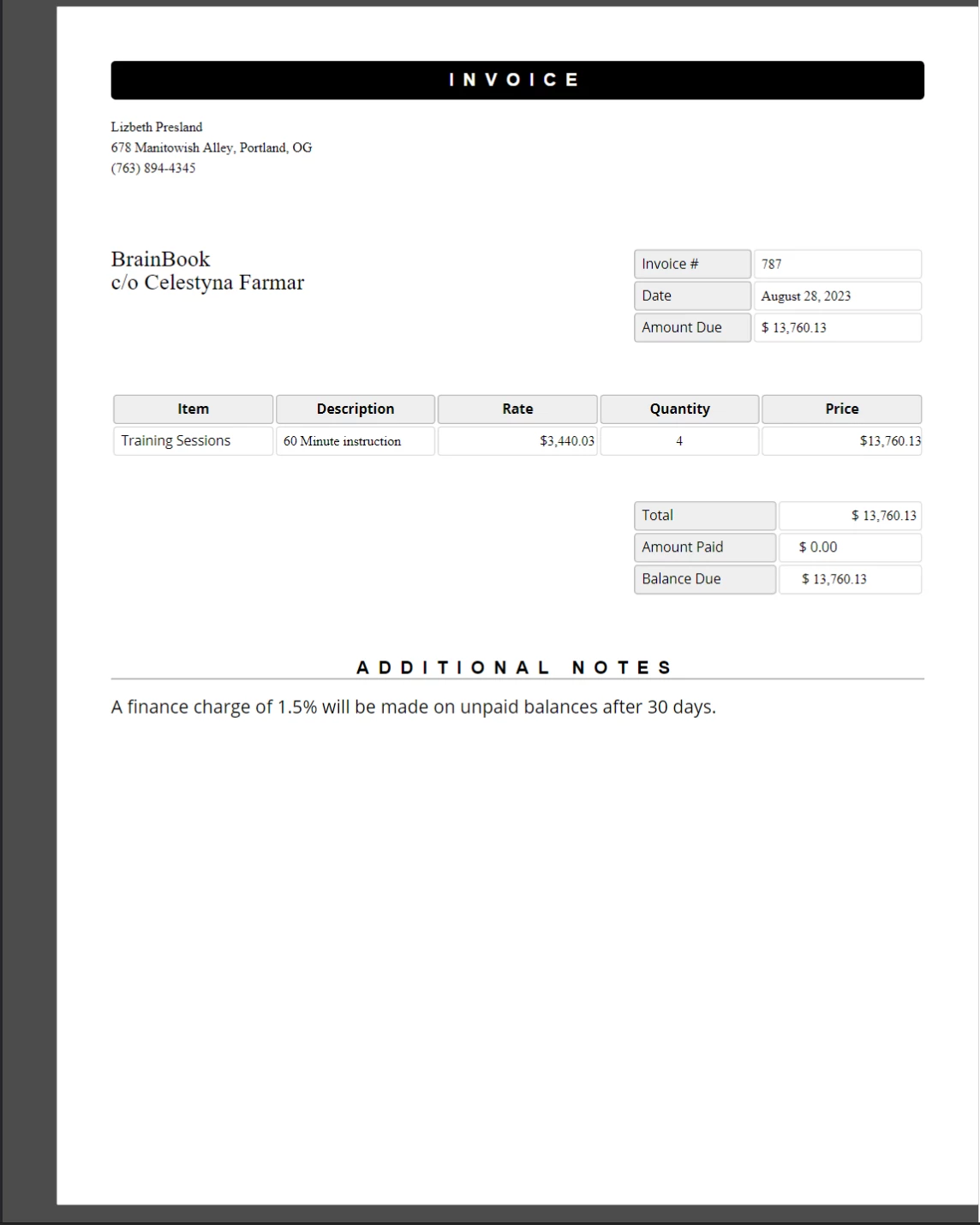
Le nouveau document PDF créé en substituant des espaces réservés définis dans un modèle HTML par des données réelles. Ce document conserve les styles CSS et la mise en page que nous attendrions si aucun remplacement de ce type n'avait jamais eu lieu.**
Pour en savoir plus
Ce tutoriel n'a fait qu'effleurer les possibilités offertes par les fonctions de haut niveau de l'API d'IronPDF. Envisagez d'étudier ces sujets connexes pour approfondir vos connaissances et votre compréhension.
-
La classe
PdfGenerator: c'est une classe utilitaire dédiée à la création d'objetsPdfDocumentà partir de HTML, d'URL, d'archives Zip et d'autres médias sources. Cette classe offre une alternative viable à l'utilisation des fonctions de rendu PDF définies dans la classePdfDocument. HttpLoginCredentials: si vous avez besoin de générer des PDF à partir de pages web qui nécessitent des cookies spécifiques ou qui sont protégées par un mot de passe, alors cette référence vous sera extrêmement utile.
Darrius Serrant est titulaire d'une licence en informatique de l'Université de Miami et travaille en tant qu'ingénieur marketing Full Stack WebOps chez Iron Software. Attiré par le code depuis son plus jeune âge, il a vu l'informatique comme à la fois mystérieuse et accessible, en faisant le support parfait pour la créativité et la résolution de problèmes.
Chez Iron Software, Darrius apprécie de créer de nouvelles choses et de simplifier des concepts complexes pour les rendre plus compréhensibles. En tant que l'un de nos développeurs résidents, il a également fait du bénévolat pour enseigner aux étudiants, partageant son expertise avec la prochaine génération.
Pour Darrius, son travail est épanouissant car il est apprécié et a un réel impact.









