Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque Node.js PDF


Node.js a gagné une traction significative en tant que plateforme côté serveur populaire pour développer des applications web. PDFs(Format de document portable)sont un format de document universellement accepté, largement utilisé pour partager et présenter des données. Avec les bons outils, les développeurs peuvent créer, manipuler et modifier des documents PDF directement depuis leurs applications Node.js.
C'est là que les bibliothèques PDF pour Node.js deviennent utiles. Ces bibliothèques permettent aux développeurs de créer, modifier, fusionner et convertir des PDF par programmation. Dans cet article, nous allons comparer quatre bibliothèques PDF pour Node.js : IronPDF for Node.js, PDFKit, pdf-lib et pdf-parse.
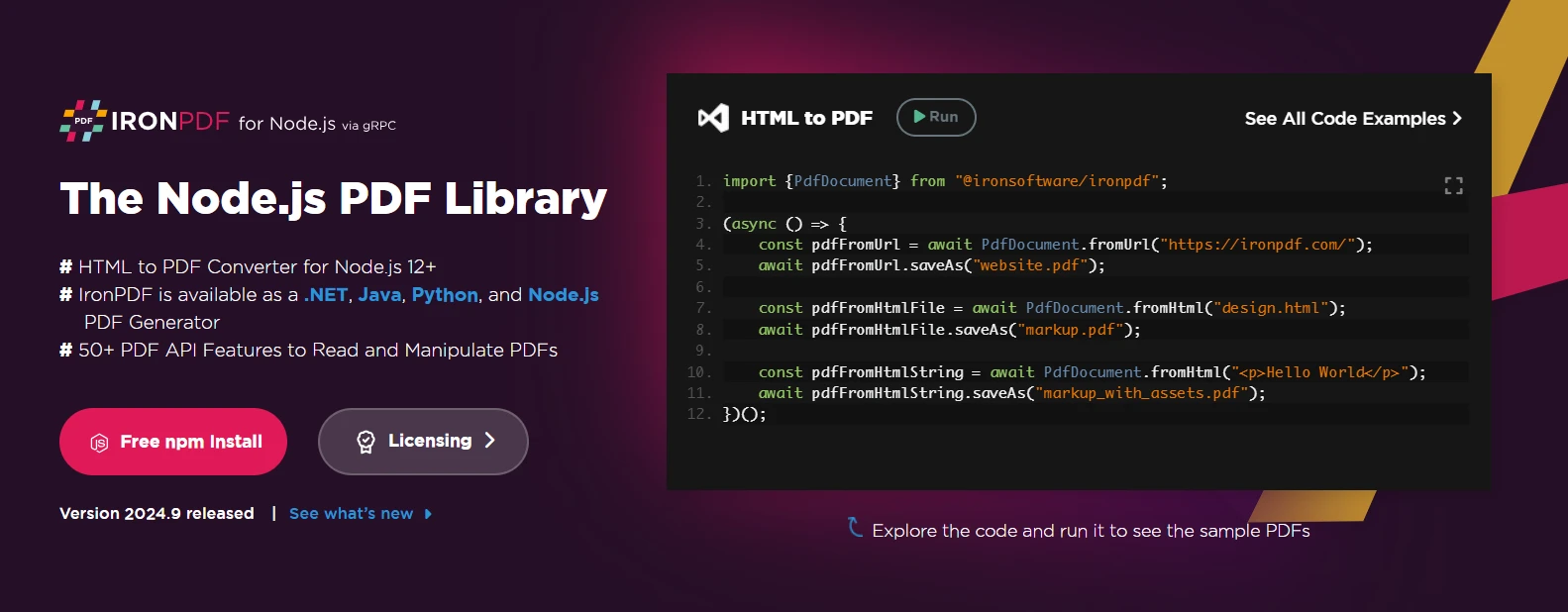
IronPDFest une bibliothèque PDF haut de gamme conçue par Iron Software pour simplifier la génération et la manipulation de PDF pour les développeurs. À l'origine connu pour son implémentation .NET, IronPDF prend également en charge Node.js, offrant une large gamme de fonctionnalités permettant aux développeurs de créer et manipuler des documents PDF dans leurs applications de générateur de PDF Node.js.
IronPDF utilise la puissance de Chromium pour un rendu de haute qualité, ce qui le rend particulièrement apte à convertir un fichier HTML, y compris des mises en page complexes et du contenu dynamique, en fichiers PDF. Que vous développiez des applications web nécessitant l'automatisation de documents, la génération de factures ou le rendu de contenu dynamique, IronPDF dispose de tous les outils nécessaires pour vous aider.
Voici quelques-unes de ses fonctionnalités clés importantes :
API entièrement documentée et exemples de code.
Pour plus d'informations détaillées sur IronPDF et ses fonctionnalités, veuillez visiter ce documentation page.
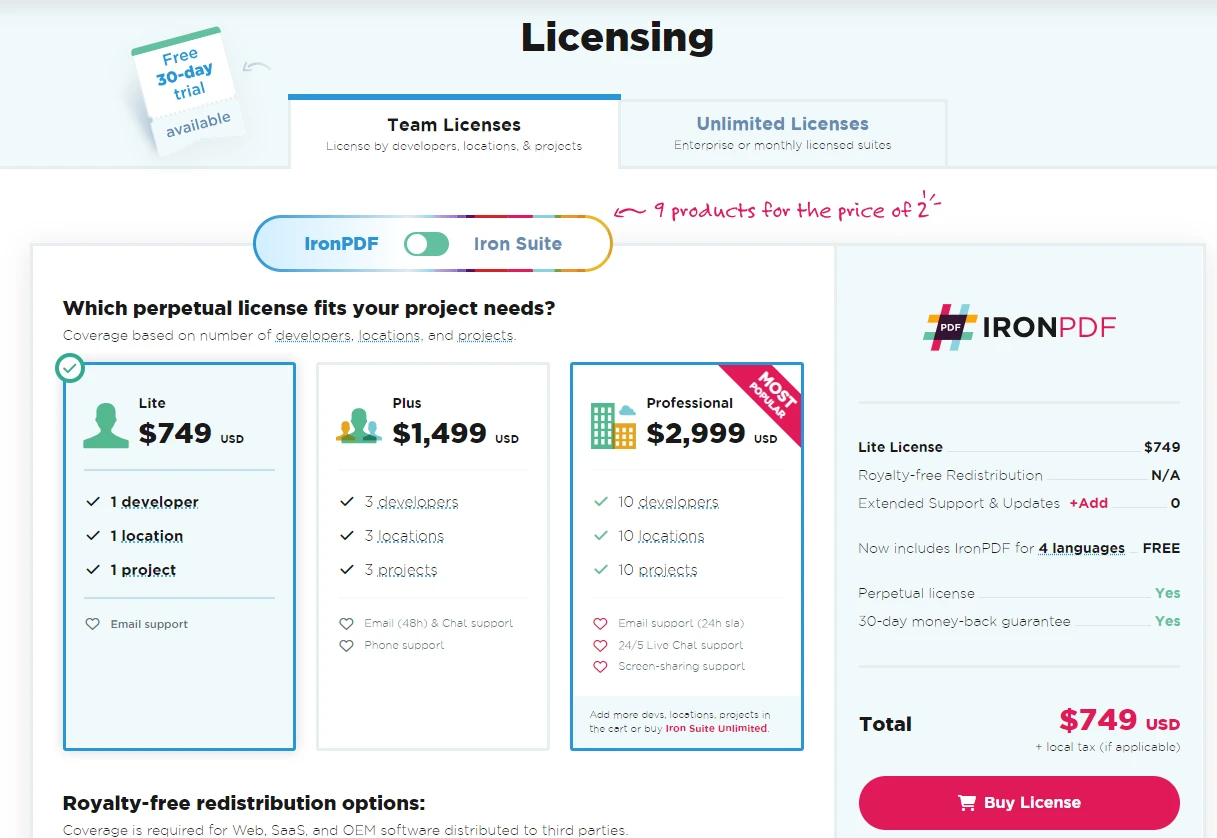
IronPDF propose une offre commercialelicenseest disponible, permettant aux développeurs de tester les fonctionnalités de la bibliothèque avant de s'engager à un achat.
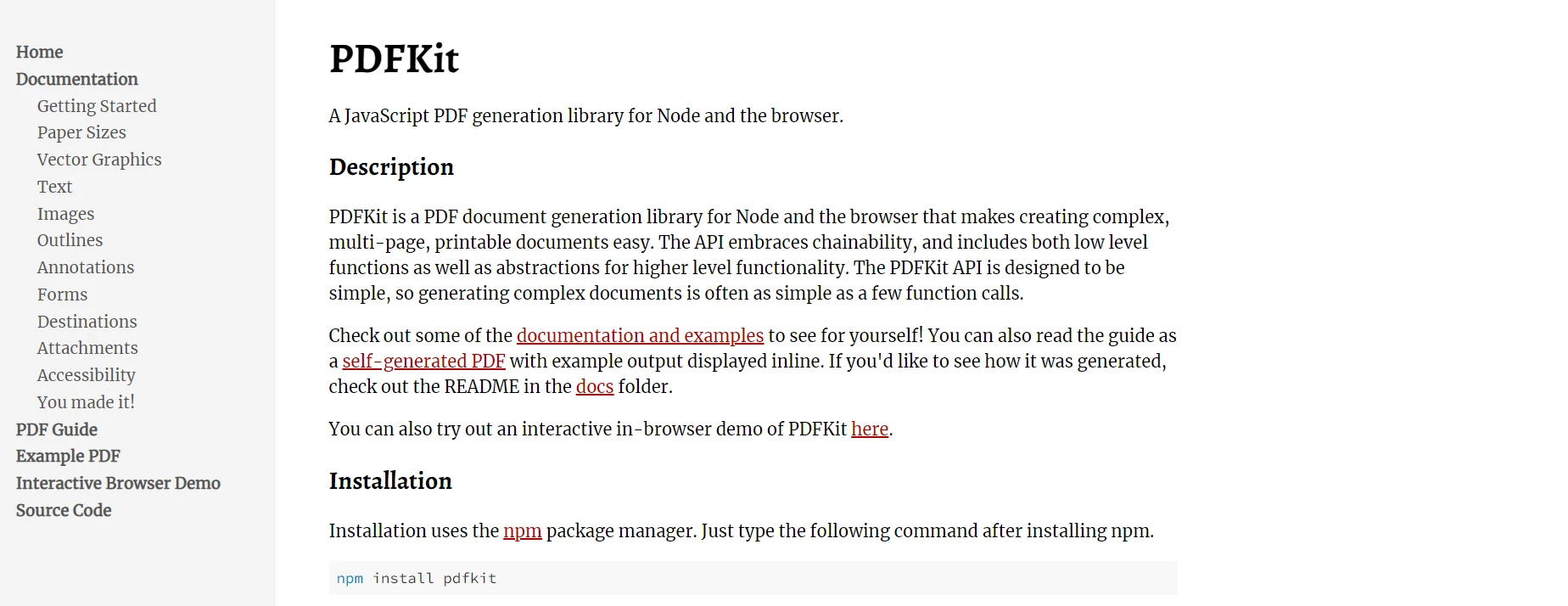
PDFKitest une bibliothèque open-source populaire pour Node.js qui offre une solution simple et efficace pour générer des PDF à partir de zéro. Il permet aux développeurs de créer des PDFs par programmation avec des fonctionnalités telles que l'ajout de texte, d'images, de graphiques vectoriels, et plus encore. L'une des principales forces de PDFKit est sa capacité à gérer la génération de grands fichiers PDF en diffusant directement la sortie, plutôt qu'en chargeant l'ensemble du document en mémoire, ce qui est extrêmement bénéfique pour les applications traitant de grandes ensembles de données ou de rapports.
La simplicité et la légèreté de PDFKit en font un choix idéal pour les développeurs qui n'ont besoin que de fonctionnalités de base pour la génération de PDF. Il est bien adapté aux applications telles que la génération dynamique de rapports, de factures ou de documents imprimables. PDFKit permet de personnaliser le texte, les polices, les couleurs, et vous permet même de dessiner des formes et des lignes personnalisées dans le PDF. La communauté autour de PDFKit est également très active, ce qui garantit qu'il reste à jour et reçoit des améliorations régulières.
Voici quelques caractéristiques clés de PDFKit :
Génération basée sur le streaming, permettant la gestion de fichiers volumineux.
Pour plus de détails sur les fonctionnalités et l'utilisation, vous pouvez télécharger ce guide PDF depuisici.
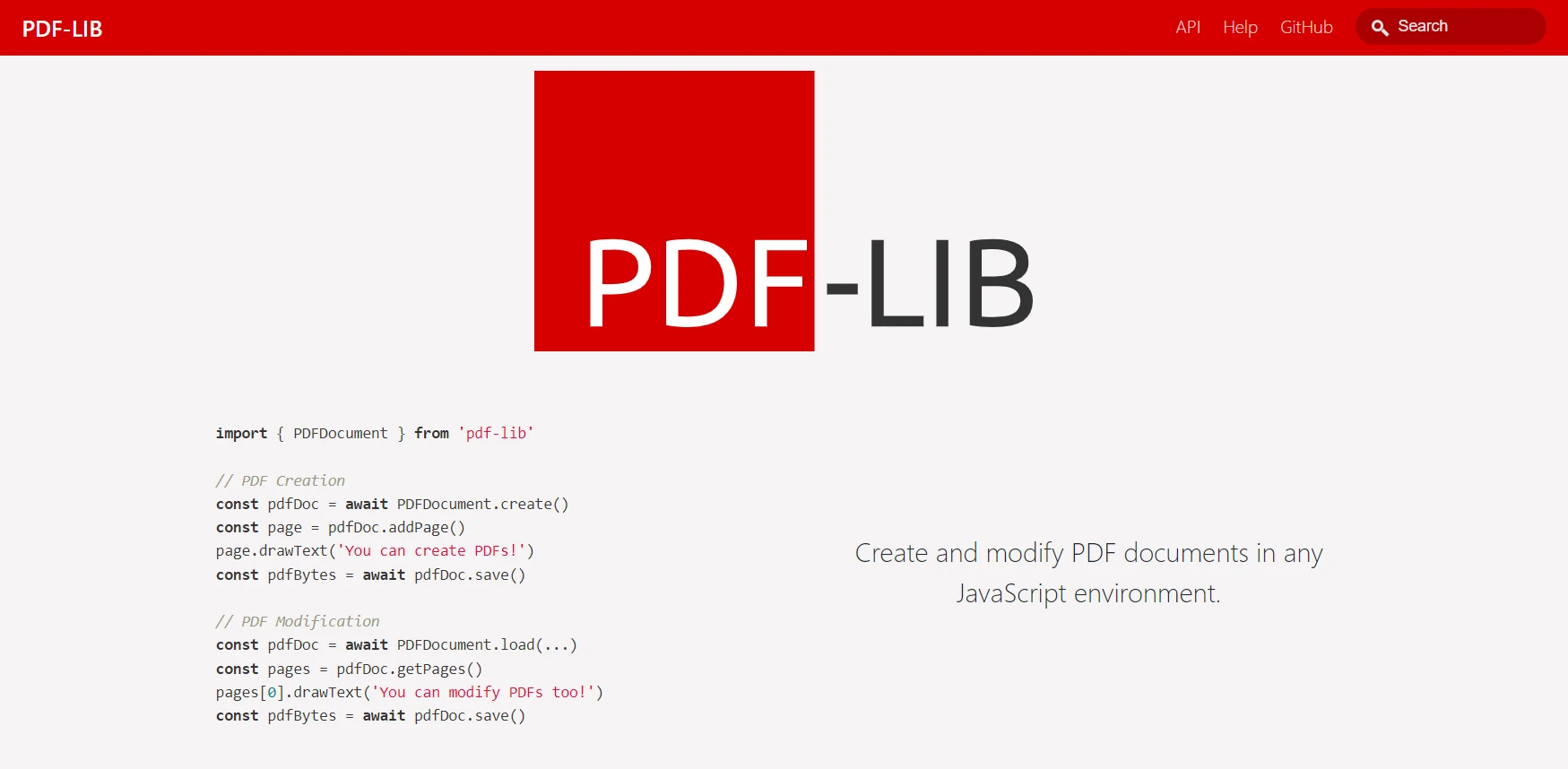
PDF-LIBest une bibliothèque open-source qui excelle tant dans la création de nouveaux fichiers PDF que dans la modification des fichiers existants. Contrairement à PDFKit, qui est principalement axé sur la création de PDF, pdf-lib offre un ensemble de fonctionnalités plus polyvalentes, permettant aux développeurs non seulement de générer de nouveaux PDF mais aussi de manipuler des documents existants. Cela fait de pdf-lib un outil puissant pour un large éventail de cas d'utilisation, tels que le remplissage de formulaires, l'ajout de texte ou d'images à des fichiers PDF existants, et même la fusion ou la division de fichiers PDF.
L'une des principales fonctionnalités de pdf-lib est sa capacité à travailler avec des champs de formulaire. Cela est particulièrement utile pour les applications où les utilisateurs doivent remplir ou signer des documents PDF, tels que des contrats ou des documents juridiques. Les développeurs peuvent pré-remplir des champs de formulaire ou extraire des données à partir de formulaires existants en utilisant la bibliothèque. Il prend également en charge l'intégration de polices personnalisées, le dessin de graphiques et l'application d'annotations, ce qui en fait un outil flexible pour des tâches PDF plus complexes. De plus, pdf-lib est conçu pour être utilisé entièrement côté client, ce qui permet aux développeurs de mettre en œuvre des fonctionnalités PDF directement dans le navigateur, ouvrant ainsi un tout nouveau champ de possibilités pour les applications web.
Voici quelques caractéristiques clés importantes de PDF-LIB :
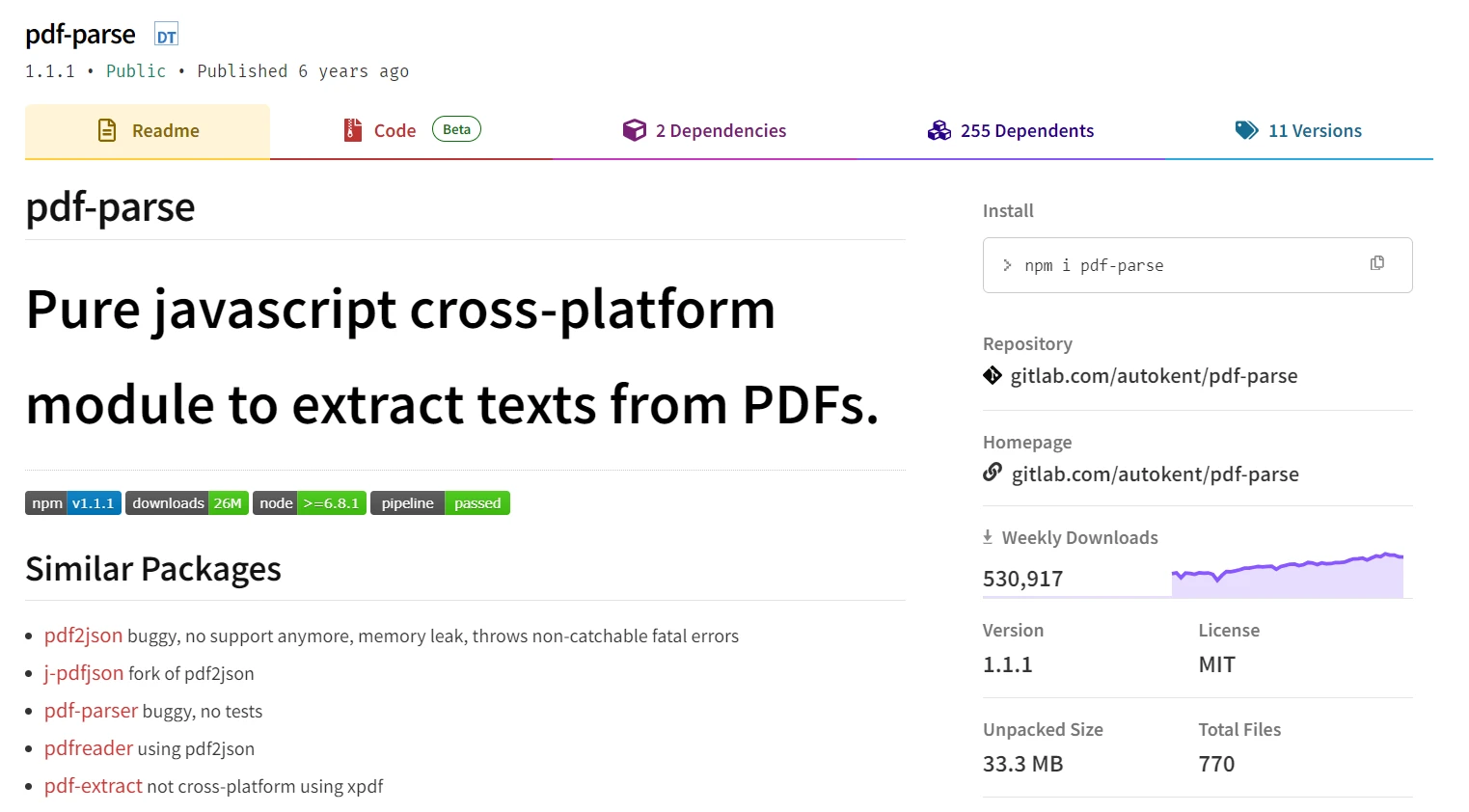
pdf-parseest une bibliothèque Node.js spécialisée, axée sur l'extraction de données à partir de PDFs plutôt que sur leur création ou modification. C'est un outil open-source conçu pour aider les développeurs à extraire du texte, des métadonnées et d'autres contenus à partir de documents PDF existants. C'est particulièrement utile pour les applications qui doivent traiter et analyser des fichiers PDF, comme les moteurs de recherche, les outils de traitement de données, ou les systèmes nécessitant l'analyse et l'extraction de documents.
L'outil pdf-parse excelle par sa simplicité et sa facilité d'utilisation. Avec seulement quelques lignes de code, les développeurs peuvent analyser un document PDF et récupérer son contenu texte ou ses métadonnées. Cela le rend idéal pour les cas d'utilisation où les fichiers PDF doivent être indexés, recherchés ou convertis en d'autres formats. C'est également un excellent choix pour les applications qui ont besoin d'extraire du texte à partir de documents numérisés en utilisant l'OCR.(Reconnaissance optique de caractères)en conjonction avec un autre outil OCR. pdf-parse peut gérer une variété de PDF, même ceux complexes comportant plusieurs colonnes de texte ou des images intercalées avec du texte.
Cependant, pdf-parse est limité car il n'offre aucune fonctionnalité pour créer ou modifier des PDF. Si votre projet nécessite des fonctionnalités plus avancées, telles que la manipulation de PDF ou le remplissage de formulaires, vous devrez le combiner avec une autre bibliothèque. De plus, pdf-parse peut parfois rencontrer des difficultés pour extraire du texte à partir de PDF fortement formatés ou chiffrés, ce qui peut nécessiter des étapes de traitement supplémentaires. Néanmoins, pour des tâches simples d'extraction de texte, pdf-parse reste une option fiable et facile à utiliser dans l'écosystème Node.js.
Chacune de ces bibliothèques PDF pour Node.js offre des avantages uniques en fonction des exigences du projet. IronPDF for Node.jsse distingue par son ensemble de fonctionnalités étendu et sa capacité à convertir un contenu HTML complexe en PDF avec une haute fidélité, bien qu'il soit accompagné d'une licence commerciale. PDFKit est parfait pour des besoins simples et gratuits de génération de PDF, tandis que pdf-lib équilibre la création et la modification dans un package gratuit. Enfin, pdf-parse est votre solution privilégiée pour l'extraction de texte à partir de PDF.
Lors du choix d'une bibliothèque PDF pour votre projet Node.js, il est essentiel d'évaluer les besoins de votre application. Si votre projet nécessite une manipulation avancée de documents PDF complexes et un rendu HTML, IronPDF est un excellent choix. Pour une création PDF basique, PDFKit ou pdf-lib sont d'excellentes alternatives gratuites, et si votre objectif est l'extraction de données, pdf-parse pourrait être l'outil qu'il vous faut.
npm i @ironsoftware/ironpdf
Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau