
Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Java


Cet article va créer un analyseur PDF en Java en utilisant la bibliothèque IronPDF de manière efficace.
IronPDF for Java est une bibliothèque Java PDF qui permet la création, la lecture et la manipulation de documents PDF avec facilité et précision. Il s'appuie sur le succès d'IronPDF for .NET et offre des fonctionnalités efficaces sur différentes plates-formes. IronPDF for Java utilise le IronPdfEngine qui est rapide et optimisé pour les performances.
Avec IronPDF, vous pouvez extraire du texte et des images à partir de fichiers PDF et il permet également de créer des PDF à partir de diverses sources y compris des chaînes HTML, des fichiers, des URL et des images. De plus, vous pouvez facilement ajouter du nouveau contenu, insérer des signatures avec IronPDF, et intégrer des métadonnées dans les documents PDF. IronPDF est spécifiquement conçu pour Java 8+, Scala et Kotlin, et est compatible avec les plateformes Windows, Linux et Cloud.
fromFileextractAllTextrenderUrlAsPdf pour rendre un PDF à partir d'une URLextractAllImagesPour réaliser un projet PDF Parsing en Java, vous aurez besoin des outils suivants :
Java IDE : Vous pouvez utiliser n'importe quel IDE prenant en charge Java. Il existe plusieurs IDE Java disponibles pour le développement. Ici, ce tutoriel utilisera IntelliJ IDE. Vous pouvez utiliser NetBeans, Eclipse, etc.
Projet Maven : Maven est un gestionnaire de dépendances et permet de gérer le projet Java. Maven pour Java peut être téléchargé depuis le site officiel de Maven. IDE Java IntelliJ a un support intégré pour Maven.
IronPDF - Vous pouvez télécharger et installer IronPDF for Java de plusieurs façons.
pom.xml dans un projet Maven. :ProductInstallVisitez le site du dépôt Maven pour le dernier package IronPDF pour Java.
Un téléchargement direct depuis la page de téléchargement officielle de Iron Software.
pom.xml : <dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.5</version>
</dependency>Une fois que toutes les conditions préalables sont installées, la première étape consiste à importer les packages IronPDF nécessaires pour travailler avec un document PDF. Ajoutez le code suivant en haut du fichier Main.java :
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;Certaines méthodes disponibles dans IronPDF nécessitent une licence pour être utilisées. Vous pouvez acheter une licence ou essayer IronPDF gratuitement dans le cadre d'une version d'essai. Vous pouvez régler la touche comme suit :
License.setLicenseKey("YOUR-KEY");Pour analyser un document existant pour l'extraction de contenu, la classe PdfDocument est utilisée. Sa méthode statique fromFile est utilisée pour analyser un fichier PDF à partir d'un chemin spécifique avec un nom de fichier spécifique dans un programme Java. Le code est le suivant :
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));
Document analysé
IronPDF for Java fournit une méthode facile pour extraire du texte de documents PDF. L'extrait de code suivant permet d'extraire des données textuelles d'un fichier PDF :
String extracted_text = parsedDocument.extractAllText();Le code ci-dessus produit la sortie indiquée ci-dessous :
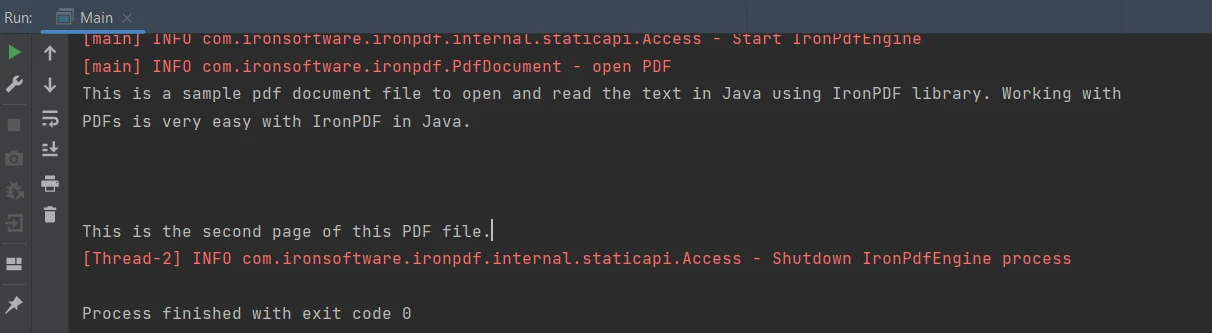
Sortie
Les capacités d'IronPDF for Java ne se limitent pas aux PDF existants, mais peuvent également créer et analyser un nouveau fichier pour en extraire le contenu. Ici, ce tutoriel créera un fichier PDF à partir d'une URL et en extraira le contenu. L'exemple suivant montre comment réaliser cette tâche :
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extracted_text = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extracted_text);
}
}Le résultat est le suivant :
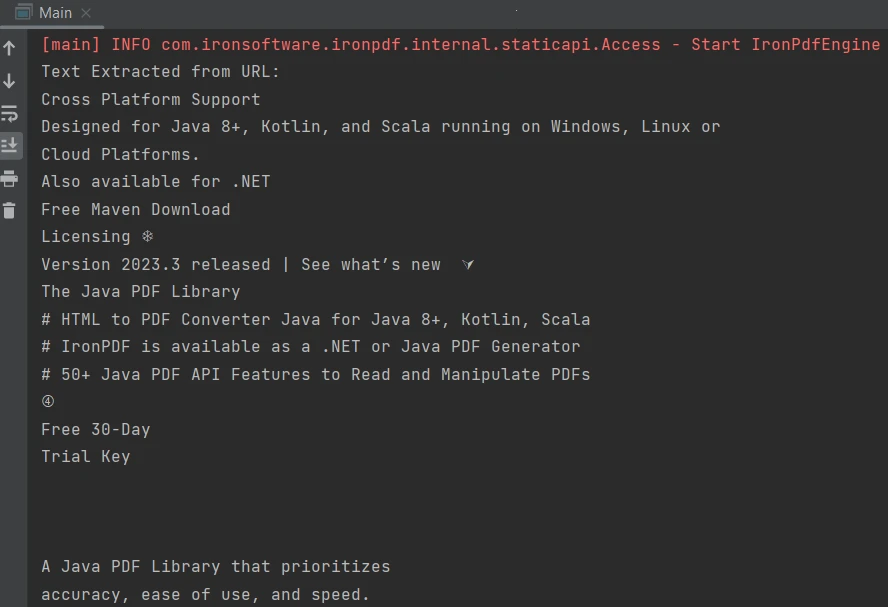
Sortie
IronPDF offre également une option facile pour extraire toutes les images des documents analysés. Ici, le tutoriel utilisera l'exemple précédent pour voir à quel point il est facile d'extraire les images des fichiers PDF.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}La méthode [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages()) retourne une liste de BufferedImages. Chaque BufferedImage peut ensuite être enregistré sous forme d'images PNG à un emplacement à l'aide de la méthode ImageIO.write. Le fichier PDF analysé contient 34 images et chaque image est parfaitement extraite.

Images extraites
Extraire le contenu des limites tabulaires dans un fichier PDF est facilité avec un simple code en une ligne utilisant la [méthode extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText(). L'extrait de code suivant montre comment extraire du texte d'un tableau dans un fichier PDF :
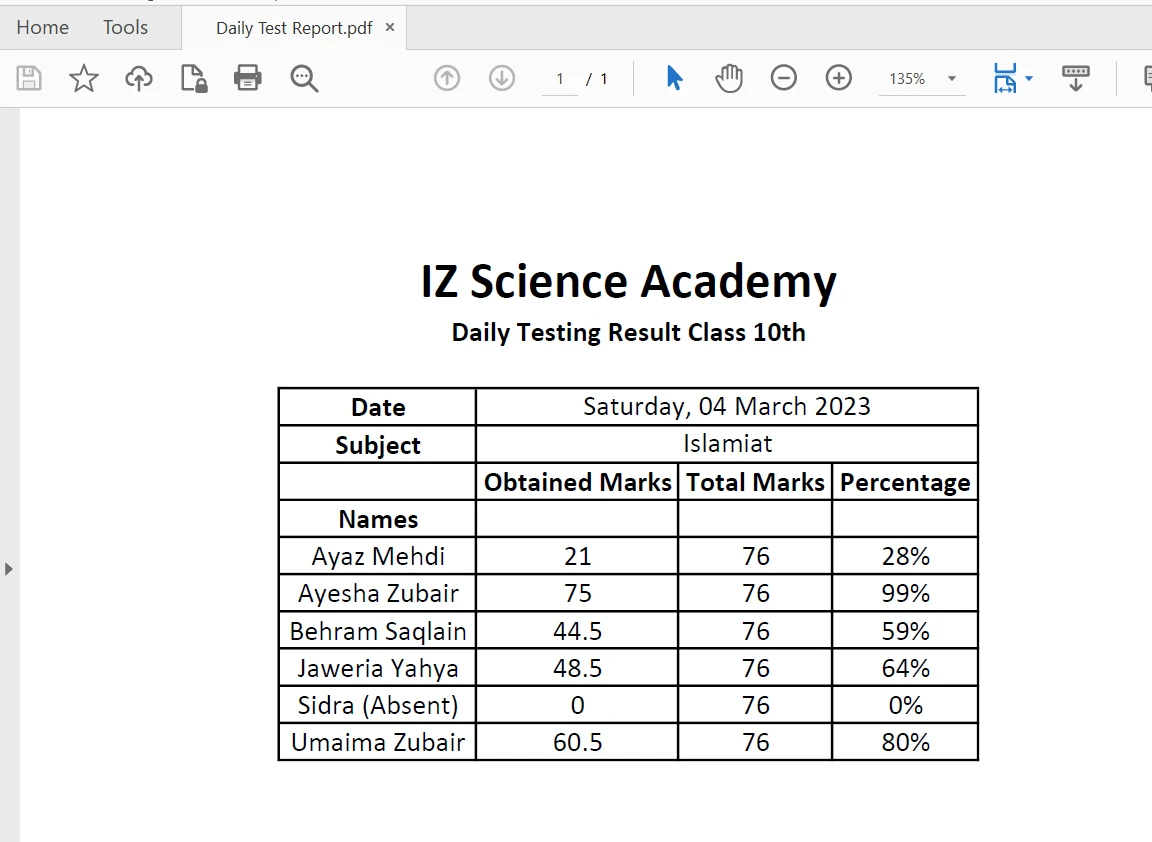
Tableau dans le PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extracted_text = parsedDocument.extractAllText();
System.out.println(extracted_text);Le résultat est le suivant :
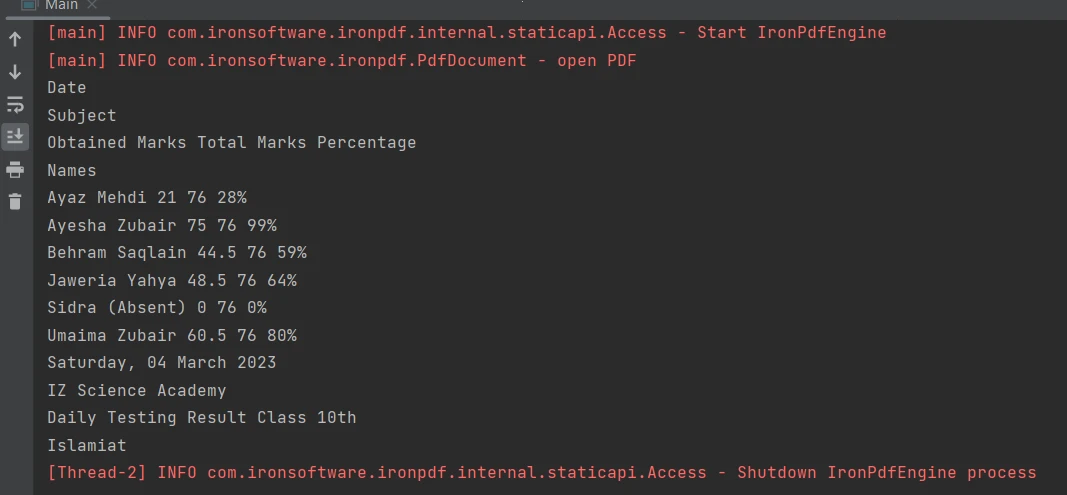
Sortie
Cet article a démontré comment analyser un document PDF existant ou créer un nouveau fichier analyseur PDF à partir d'une URL pour en extraire des données en Java en utilisant IronPDF. Après ouverture du fichier, il peut extraire des données tabulaires, des images et du texte du PDF, et peut également ajouter le texte extrait à un fichier texte pour une utilisation ultérieure.
Pour plus d'informations détaillées sur la manière de travailler avec des fichiers PDF de manière programmatique en Java, veuillez visiter ces exemples de création de fichiers PDF.
La bibliothèque IronPDF for Java est gratuite à des fins de développement avec une version d'essai gratuite disponible. Toutefois, pour un usage commercial, il peut être licencié par IronSoftware, à partir de $749.
Darrius Serrant est titulaire d'une licence en informatique de l'Université de Miami et travaille en tant qu'ingénieur marketing Full Stack WebOps chez Iron Software. Attiré par le code depuis son plus jeune âge, il a vu l'informatique comme à la fois mystérieuse et accessible, en faisant le support parfait pour la créativité et la résolution de problèmes.
Chez Iron Software, Darrius apprécie de créer de nouvelles choses et de simplifier des concepts complexes pour les rendre plus compréhensibles. En tant que l'un de nos développeurs résidents, il a également fait du bénévolat pour enseigner aux étudiants, partageant son expertise avec la prochaine génération.
Pour Darrius, son travail est épanouissant car il est apprécié et a un réel impact.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau