
Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Java


Cet article montre comment les fichiers PDF sont lus en Java à l'aide de la bibliothèque PDF pour le projet Java de démonstration, nomméPrésentation de la bibliothèque IronPDF for Javala traduction doit rester professionnelle et préserver l'exactitude technique tout en expliquant les caractéristiques et les avantages de ces outils de développement.
Installez la bibliothèque PDF pour lire des fichiers PDF en utilisant Java.
Importez les dépendances pour utiliser le document PDF dans le projet.
Charger un fichier PDF existant en utilisantdocumentation de la méthode PdfDocument.fromFile(en anglais).
Extraire le texte du fichier PDF à l'aide de[Explication de la méthode d'extraction de texte en PDF](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()) méthode.
Créez l'objet Metadata en utilisant le[Tutoriel sur l'extraction de métadonnées en PDF](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata()) méthode.
Pour rationaliser le processus de lecture des fichiers PDF dans Java, les développeurs se tournent souvent vers des bibliothèques tierces qui fournissent des solutions complètes et efficaces. L'une de ces bibliothèques est IronPDF for Java.
IronPDF est conçu pour être convivial pour les développeurs, en fournissant une API simple qui fait abstraction des complexités de la manipulation des pages PDF. Avec IronPDF, les développeurs Java peuvent intégrer en toute transparence des fonctionnalités de lecture de fichiers PDF dans leurs projets, réduisant ainsi le temps et les efforts de développement. Cette bibliothèque prend en charge un large éventail de fonctionnalités PDF, ce qui en fait un choix polyvalent pour divers cas d'utilisation.
Les principales fonctionnalités incluent la capacité decréer un fichier PDF à partir de différents formats la traduction doit être réalisée dans un langage simple et clair, y compris HTML, JavaScript, CSS, documents XML et divers formats d'images. De plus, IronPDF offre la possibilité deajouter des en-têtes et des pieds de page aux PDF, créer des tableaux dans des documents PDFet bien d'autres choses encore.
Pour configurer IronPDF, assurez-vous d'avoir un compilateur Java fiable. Cet article recommande d'utiliser IntelliJ IDEA.
Lancer IntelliJ IDEA et initier un nouveau projet Maven.
pom.xml. Insérez les dépendances Maven suivantes pour intégrer IronPDF : :ProductInstallExplorons un exemple simple de code Java qui démontre comment utiliser IronPDF pour lire le contenu d'un fichier PDF. Dans cet exemple, concentrons-nous sur la méthode d'extraction du texte d'un document PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}Ce code Java utilise la bibliothèque IronPDF pour extraire du texte à partir d'un fichier PDF spécifié. Il importera la bibliothèque Java ainsi que définira la clé de licence, une condition préalable à l'utilisation de la bibliothèque. Le code charge ensuite un document PDF à partir du fichier "html_file_saved.pdf" et extrait tout son contenu texte du fichier sous forme de tampon de chaîne interne. Le texte extrait est stocké dans une variable, puis imprimé sur la console.
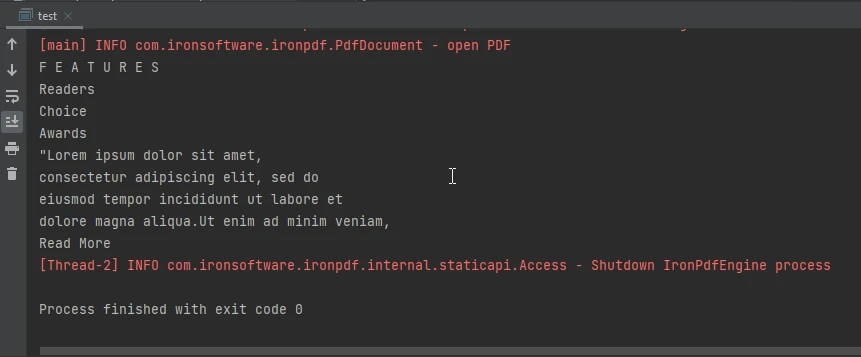
La sortie de la console
Au-delà de l'extraction de texte, IronPDF étend ses capacités à l'extraction de métadonnées à partir de fichiers PDF. Pour illustrer cette fonctionnalité, nous allons nous plonger dans un exemple de code Java qui présente le processus de récupération des métadonnées d'un document PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}Ce code Java utilise la bibliothèque IronPDF pour extraire les métadonnées, en particulier les informations sur l'auteur, d'un document PDF. Cela commence par charger un document PDF à partir du fichier "html_file_saved.pdf." Le code récupère les métadonnées du document en utilisant leDocumentation de la classe MetadataManagerpour ce faire, nous avons besoin de l'aide de l'auteur, en particulier pour obtenir les informations relatives à l'auteur. Les informations extraites sur l'auteur sont stockées dans une variable et imprimées sur la console.
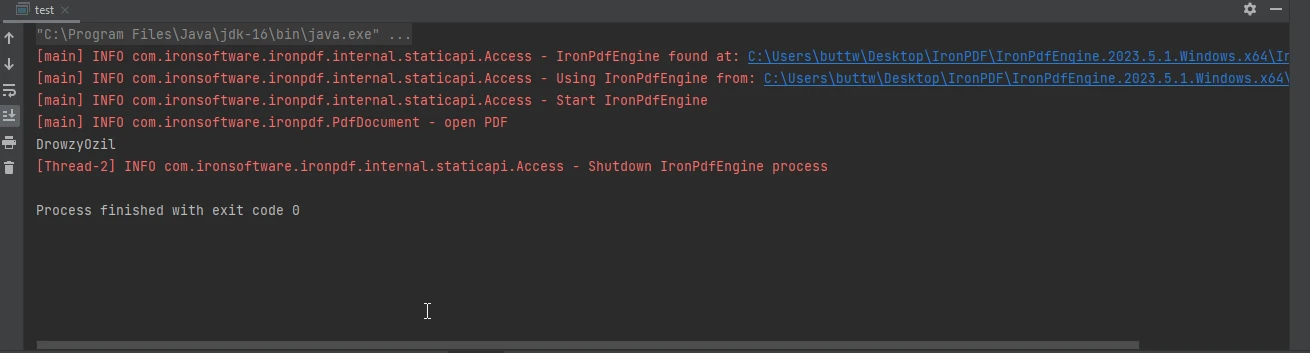
La sortie de la console
En conclusion, lire un document PDF existant dans un programme Java est une compétence précieuse qui ouvre un monde de possibilités pour les développeurs. Qu'il s'agisse d'extraire du texte, des images ou d'autres données, la possibilité de manipuler des PDF par programmation est un aspect crucial de nombreuses applications. IronPDF for Java constitue une solution robuste et efficace pour les développeurs qui souhaitent intégrer des fonctionnalités de lecture de fichiers PDF dans leurs projets Java.
En suivant les étapes d'installation et en explorant les exemples de code fournis, les développeurs peuvent rapidement tirer parti de la puissance d'IronPDF pour créer de nouveaux fichiers et gérer les tâches liées aux PDF en toute simplicité. En plus de cela, on peut également explorer davantage ses capacités à créer des documents cryptés.
Portail des produits IronPDF offre une assistance étendue à ses développeurs. Pour en savoir plus sur le fonctionnement de IronPDF for Java, visitez ces pagespages de documentation complètes. En outre, IronPDF offre un service depage d'offre de licence d'essai gratuite il s'agit d'une excellente occasion de découvrir IronPDF et ses fonctionnalités.
Darrius Serrant est titulaire d'une licence en informatique de l'Université de Miami et travaille en tant qu'ingénieur marketing Full Stack WebOps chez Iron Software. Attiré par le code depuis son plus jeune âge, il a vu l'informatique comme à la fois mystérieuse et accessible, en faisant le support parfait pour la créativité et la résolution de problèmes.
Chez Iron Software, Darrius apprécie de créer de nouvelles choses et de simplifier des concepts complexes pour les rendre plus compréhensibles. En tant que l'un de nos développeurs résidents, il a également fait du bénévolat pour enseigner aux étudiants, partageant son expertise avec la prochaine génération.
Pour Darrius, son travail est épanouissant car il est apprécié et a un réel impact.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau