
Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Java


Cet article explorera comment extraire des images d'un document PDF existant et les enregistrer dans un seul dossier en utilisant le langage de programmation Java. À cet effet, la bibliothèque IronPDF for Java est utilisée pour extraire des images.
extractAllImages pour extraire les imagesIronPDF est une bibliothèque Java conçue pour aider les développeurs à générer, modifier et extraire des données à partir des fichiers PDF dans leurs applications Java. Avec IronPDF, vous pouvez créer des documents PDF à partir de diverses sources, telles que HTML, des images, et plus encore. De plus, vous avez la possibilité de fusionner, diviser et manipuler des PDF existants. IronPDF comprend également des fonctionnalités de sécurité, telles que la protection par mot de passe et les signatures numériques.
Développé et maintenu par Iron Software, IronPDF est connu pour sa capacité à extraire du texte à partir de PDF, HTML et URL. Il s'agit donc d'un outil polyvalent et puissant pour un grand nombre d'applications, que vous créiez des PDF à partir de zéro ou que vous travailliez sur des PDF existants.
Avant d'utiliser IronPDF pour extraire des données d'un fichier PDF, quelques conditions préalables doivent être remplies :
Installation de Java : Assurez-vous que Java est installé sur votre système et que son chemin est défini dans les variables d'environnement. Si vous n'avez pas encore installé Java, suivez les instructions sur la page de téléchargement du site web de Java.
IDE Java : Ayez soit Eclipse, soit IntelliJ installé comme votre IDE Java. Vous pouvez télécharger Eclipse à partir de ce lien et IntelliJ depuis cette page de téléchargement.
Bibliothèque IronPDF : Téléchargez et ajoutez la bibliothèque IronPDF à votre projet en tant que dépendance. Pour obtenir des instructions d'installation, visitez le site web d'IronPDF.
L'installation d'IronPDF for Java est un processus simple, à condition que toutes les conditions requises soient remplies. Ce guide utilisera JetBrains IntelliJ IDEA pour démontrer l'installation et exécuter du code exemple.
Voici ce qu'il faut faire :
Lancer IntelliJ IDEA : Ouvrez JetBrains IntelliJ IDEA sur votre système.
Créer un projet Maven : Dans IntelliJ IDEA, créer un nouveau projet Maven. Ceci fournira un environnement approprié pour l'installation d'IronPDF for Java.
Créer un nouveau projet Maven
Une nouvelle fenêtre apparaît. Saisissez le nom du projet et cliquez sur Terminer.
Entrez le nom du projet
Après avoir cliqué sur Terminer, un nouveau projet s'ouvrira sur un fichier pom.xml pour ajouter les dépendances Maven d'IronPDF for Java.
Ensuite, ajoutez les dépendances suivantes dans le fichier pom.xml ou vous pouvez télécharger le fichier JAR depuis le dépôt Maven suivant.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2025.4.4</version>
</dependency>
Une fois que vous avez placé les dépendances dans le fichier pom.xml, une petite icône apparaîtra dans le coin supérieur droit du fichier.
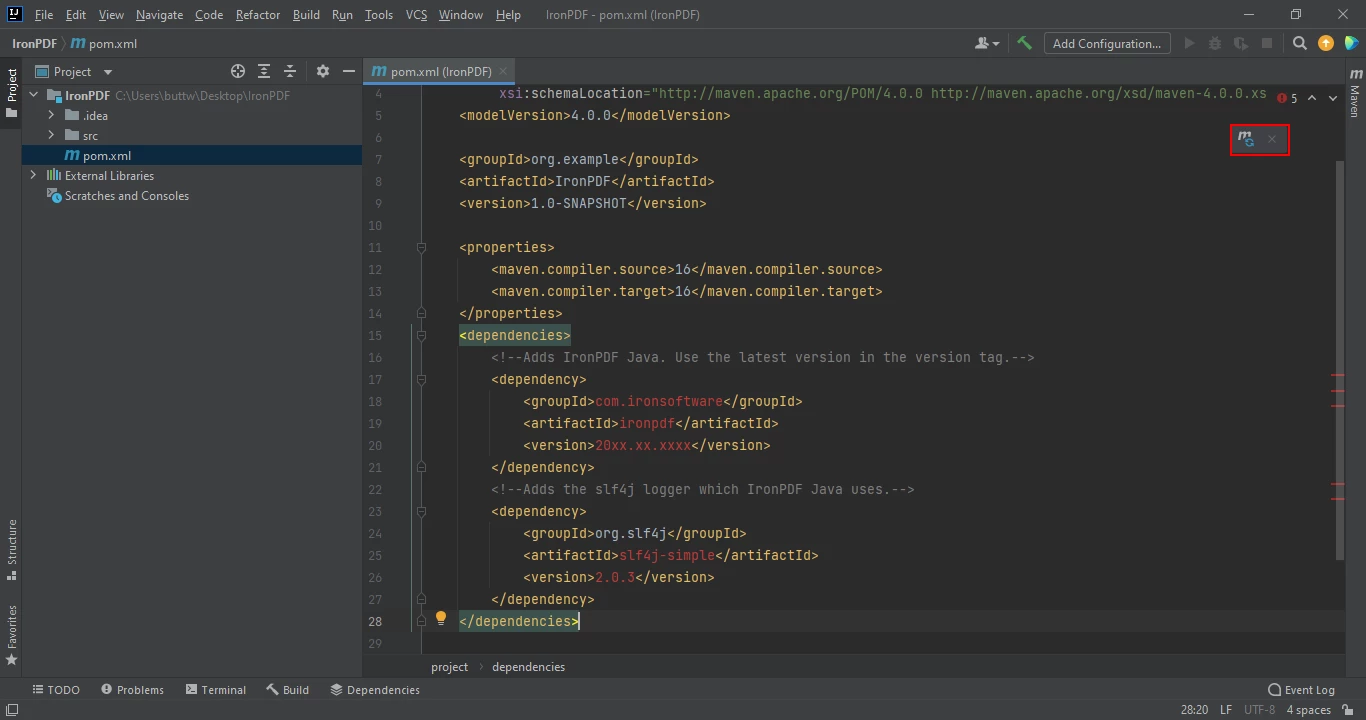
Le fichier pom.xml avec une petite icône pour installer les dépendances
Cliquez sur cette icône pour installer les dépendances Maven d'IronPDF for Java. Cela ne prendra que quelques minutes en fonction de votre connexion internet.
Vous pouvez extraire des images d'un document PDF en utilisant IronPDF avec une méthode unique appelée [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages(). Cette méthode renvoie toutes les images disponibles dans un fichier PDF. Ensuite, vous pouvez enregistrer toutes les images extraites dans le chemin de fichier de votre choix en utilisant la méthode ImageIO.write en fournissant le chemin et le format de l'image de sortie.
Dans l'exemple ci-dessous, les images d'un document PDF seront extraites et sauvegardées dans le système de fichiers en tant qu'images PNG.
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class main {
public static void main(String[] args) throws Exception {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("Final Project Report Craft Arena.pdf"));
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}Le programme ci-dessus ouvre le fichier "Final Project Report Craft Arena.pdf" et utilise la méthode extractAllImages pour extraire toutes les images du fichier dans une liste d'objets BufferedImage. Il enregistre ensuite chaque nouvelle image dans des fichiers PNG distincts portant un nom unique.
Extraction d'images à partir de la sortie PDF
Cette section expliquera comment extraire des images directement à partir des URLs. Dans le code ci-dessous, l'URL est convertie en page PDF, puis la navigation est basculée pour extraire les images du PDF.
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}Dans le code ci-dessus, l'URL de la page d'accueil d'Amazon est fournie en entrée, et elle renvoie 74 images.
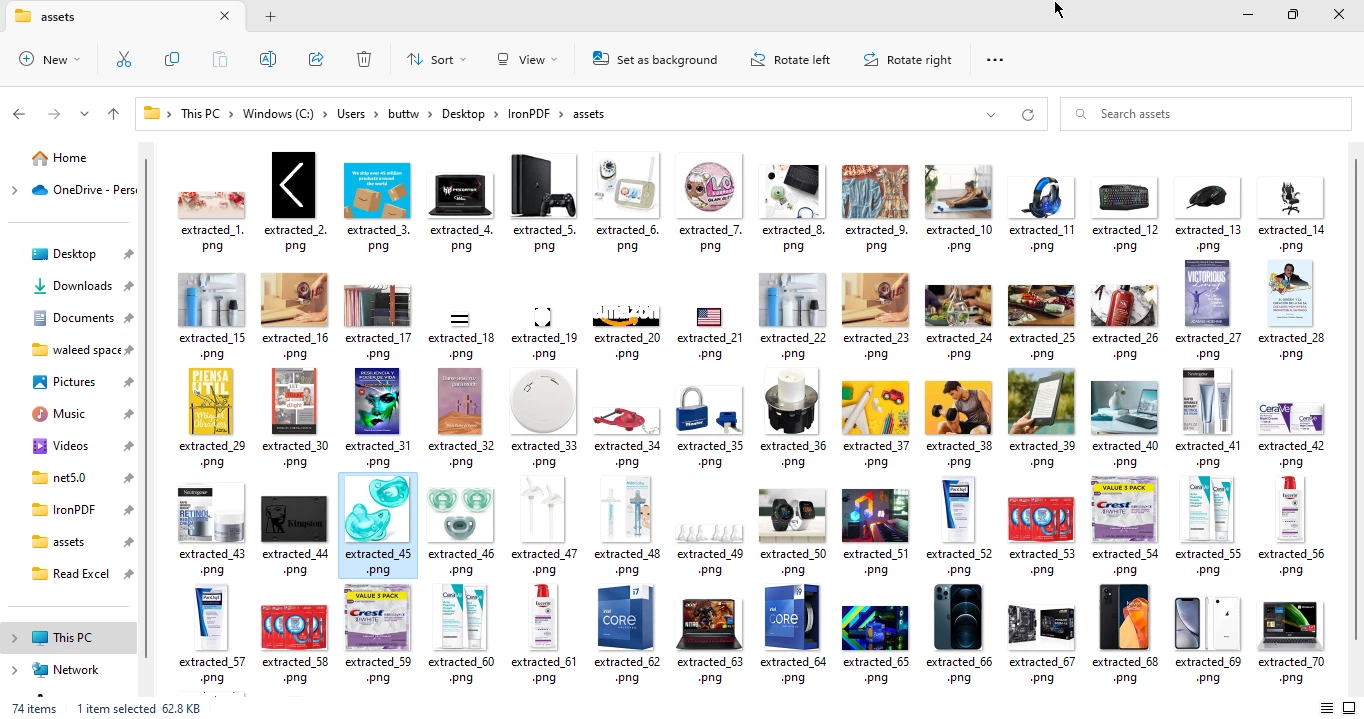
Extraction d'images à partir de la sortie PDF
L'extraction d'images d'un document PDF peut être réalisée en Java à l'aide de la bibliothèque IronPDF. Pour installer IronPDF, vous devez avoir Java, un IDE Java (Eclipse ou IntelliJ), Maven, et la bibliothèque IronPDF installés et intégrés à votre projet. Le processus d'extraction d'images d'un document PDF à l'aide de IronPDF est simple et nécessite juste un appel de méthode à extractAllImages. Vous pouvez ensuite enregistrer les images dans un chemin de fichier de votre choix en utilisant la méthode ImageIO.write.
Cet article propose un guide étape par étape sur la façon d'extraire des images d'un document PDF en utilisant Java et la bibliothèque IronPDF. Plus de détails, y compris des informations sur comment extraire du texte à partir de PDF, peuvent être trouvés dans l'Exemple de Code pour Extraire du Texte.
IronPDF est une bibliothèque avec une licence commerciale, à partir de $749. Cependant, vous pouvez l'évaluer en production avec un essai gratuit.
Darrius Serrant est titulaire d'une licence en informatique de l'Université de Miami et travaille en tant qu'ingénieur marketing Full Stack WebOps chez Iron Software. Attiré par le code depuis son plus jeune âge, il a vu l'informatique comme à la fois mystérieuse et accessible, en faisant le support parfait pour la créativité et la résolution de problèmes.
Chez Iron Software, Darrius apprécie de créer de nouvelles choses et de simplifier des concepts complexes pour les rendre plus compréhensibles. En tant que l'un de nos développeurs résidents, il a également fait du bénévolat pour enseigner aux étudiants, partageant son expertise avec la prochaine génération.
Pour Darrius, son travail est épanouissant car il est apprécié et a un réel impact.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau