Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF (EN ANGLAIS)(Format de document portable)les fichiers jouent un rôle essentiel dans d'innombrables industries, permettant aux entreprises de partager, stocker et gérer des documents en toute sécurité. Pour les développeurs, travailler avec des PDFs implique souvent de créer, lire, convertir et extraire du contenu pour répondre aux besoins des clients. L'extraction de texte à partir de PDF est essentielle pour des tâches telles que l'analyse de données, l'indexation de documents, la migration de contenu ou l'activation des fonctionnalités d'accessibilité. Des bibliothèques modernes commeIronPDFsimplifier ces tâches plus que jamais, en offrant des outils puissants pour manipuler les fichiers PDF avec un minimum d'efforts.
Ce guide se concentre sur l'une des exigences les plus courantes : extraire du texte d'un PDF en C#. Nous vous guiderons pour configurer un projet dans Visual Studio, installer IronPDF et l'utiliser pour effectuer l'extraction de texte avec des exemples de code concis. En cours de route, nous mettrons en lumière les fonctionnalités robustes d'IronPDF, y compris sa capacité à créer, manipuler et convertir des fichiers PDF en utilisant .NET. Que vous développiez des applications nécessitant une gestion intensive des documents ou que vous ayez simplement besoin d'une manipulation efficace des PDF, ce tutoriel vous aidera à démarrer.
IronPDF est un convertisseur PDF robuste qui peut effectuer presque toutes les opérations qu'un navigateur peut effectuer. La création, la lecture et la manipulation de documents PDF sont simples grâce à la bibliothèque .NET pour les développeurs. IronPDF convertit des documents HTML en documents PDF en utilisant le moteur Chrome. IronPDF prend en charge HTML, ASPX, Razor HTML et MVC View, entre autres composants web. L'application Microsoft .NET est prise en charge par IronPDF for .NET(à la fois les applications Web ASP.NET et les applications Windows traditionnelles). IronPDF peut également être utilisé pour créer un document PDF visuellement attrayant.
Nous pouvons créer un document PDF à partir de HTML5, de JavaScript, de CSS et d'images avec IronPDF. En outre, les fichiers peuvent comporter des en-têtes et des pieds de page. Grâce à IronPDF, nous pouvons facilement lire un document PDF. IronPDF dispose également d'un moteur de conversion PDF complet et d'un puissant convertisseur HTML-PDF capable de traiter les documents PDF.
Ouvrez le logiciel Visual Studio et allez dans le menu Fichier. Sélectionnez "Nouveau projet", puis "Application console". Dans cet article, nous allons utiliser une application console pour générer des documents PDF.
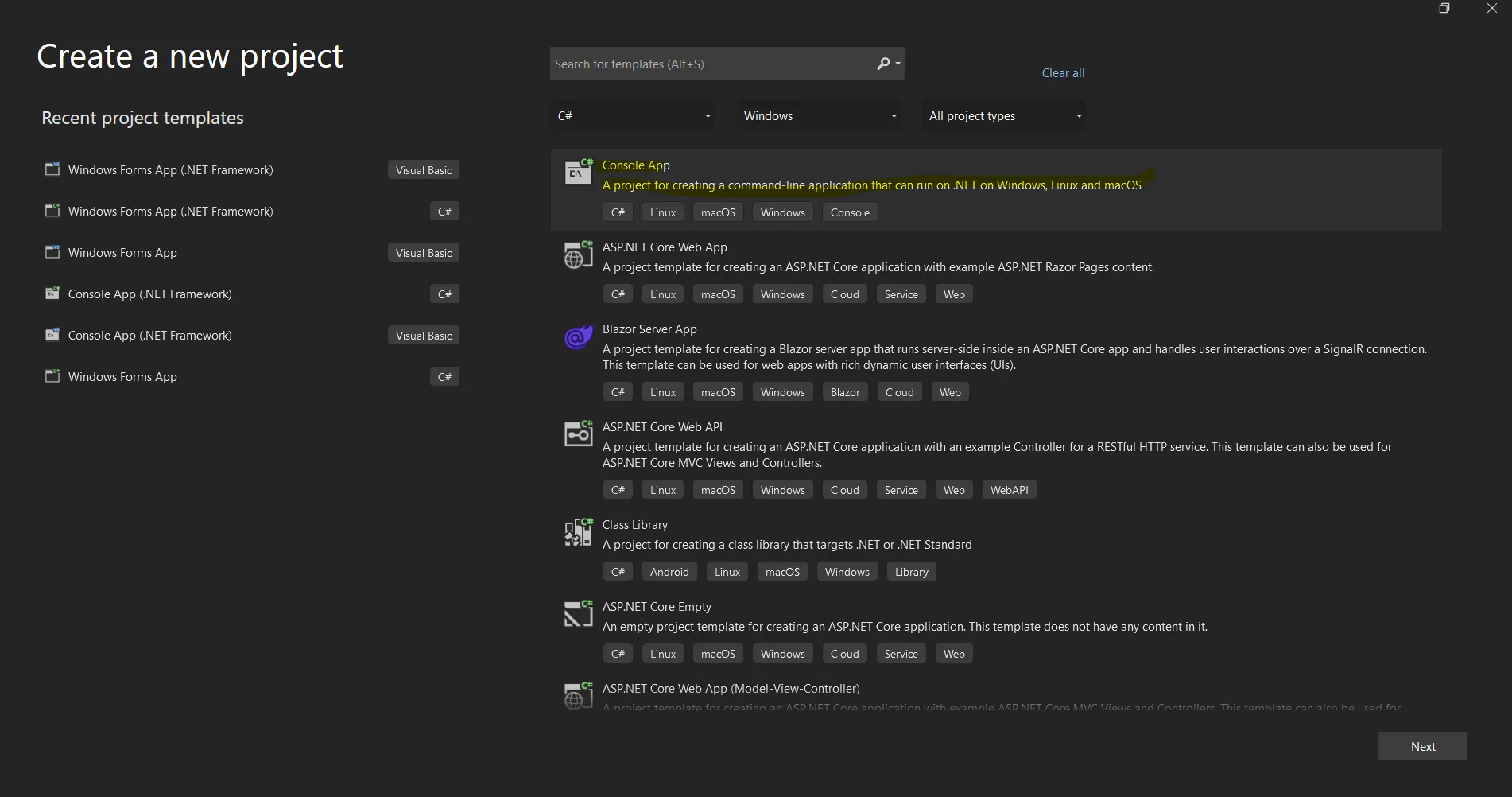
Créer un nouveau projet dans Visual Studio
Saisissez le nom du projet et sélectionnez le chemin d'accès au fichier dans la zone de texte appropriée. Cliquez ensuite sur le bouton Create et sélectionnez le Framework .NET requis, comme dans la capture d'écran ci-dessous.

Configurer un nouveau projet dans Visual Studio
Le projet Visual Studio va maintenant générer la structure de l'application sélectionnée et, si vous avez choisi l'application Console, Windows et Web, il ouvrira le fichier program.cs dans lequel vous pourrez entrer le code et construire/exécuter l'application.
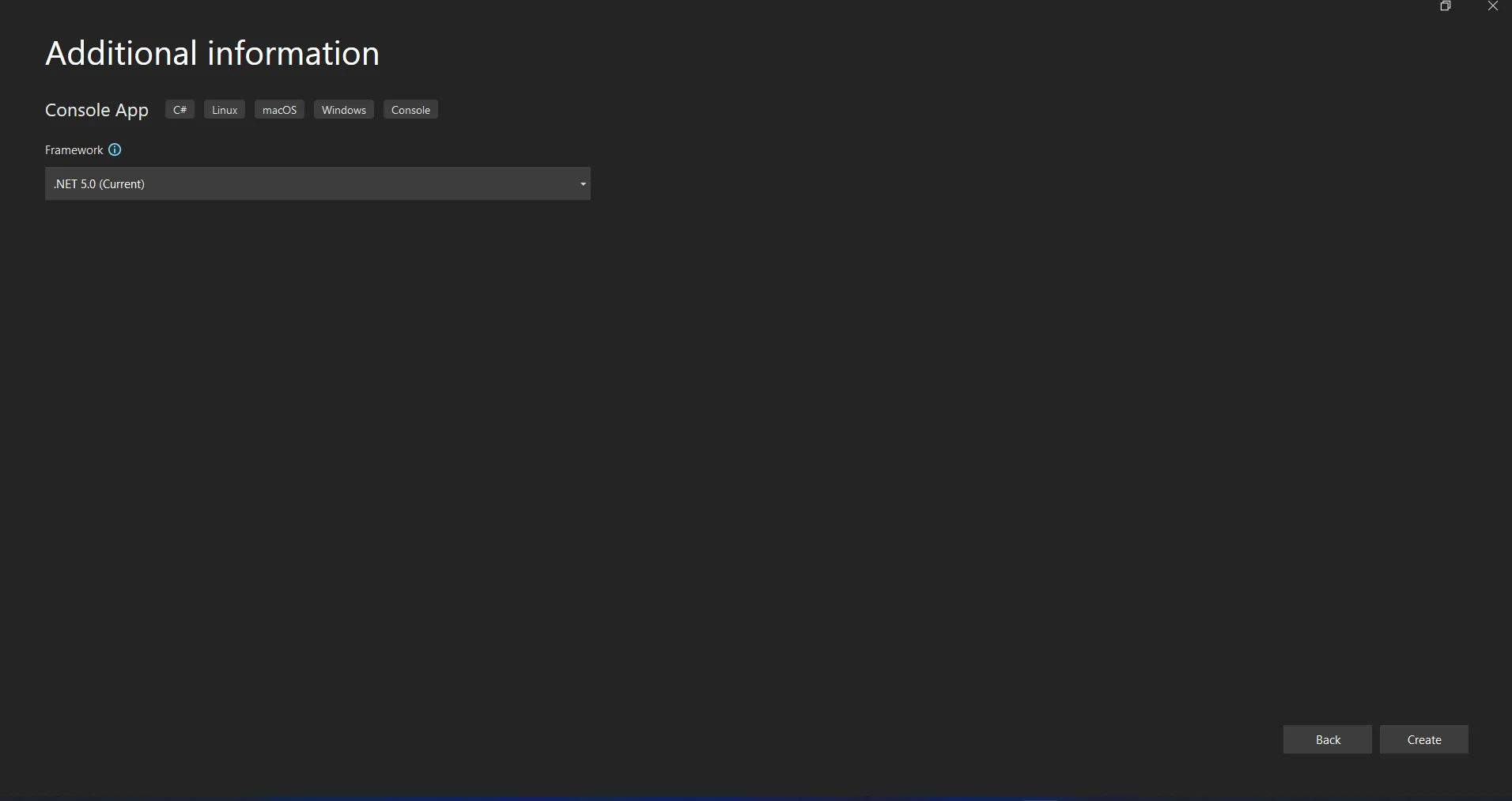
Sélectionner .NET Core
Ensuite, nous pouvons ajouter la bibliothèque pour tester le code.
La bibliothèque IronPDF peut être téléchargée et installée de quatre façons.
Il s'agit de
Le logiciel Visual Studio propose l'option NuGet Package Manager pour installer le paquet directement dans la solution. La capture d'écran ci-dessous montre comment ouvrir le gestionnaire de paquets NuGet.
Fichier programme.cs de Visual Studio
Il fournit un champ de recherche pour afficher la liste des paquets du site web de NuGet. Dans le gestionnaire de paquets, nous devons rechercher le mot-clé "IronPDF", comme dans la capture d'écran ci-dessous.

NuGet Package Manager
Dans l'image ci-dessus, nous pouvons voir la liste des éléments de recherche liés. Nous devons sélectionner l'option requise pour installer le paquet dans la solution.
Dans Visual Studio, cliquez sur Outils > NuGet Package Manager > Console du gestionnaire de paquets
Saisissez la ligne suivante dans l'onglet de la console du gestionnaire de paquets :
Install-Package IronPdf
Le paquet sera alors téléchargé/installé dans le projet en cours et prêt à être utilisé.
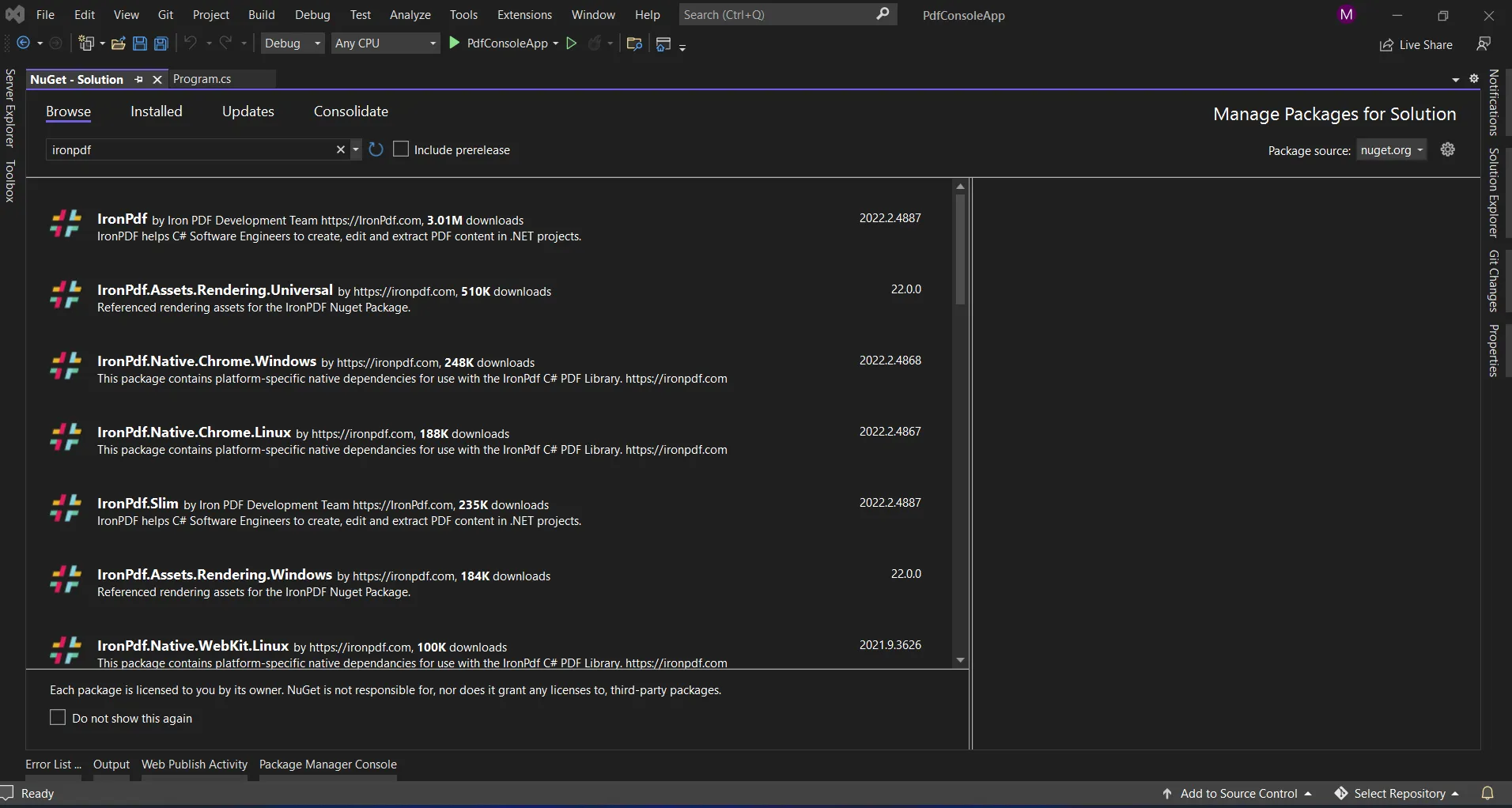
La bibliothèque IronPDF dans le gestionnaire de paquets NuGet
La troisième méthode consiste à télécharger lePaquet NuGet IronPDF directement à partir de leur site web.
Visiterle site officiel d'IronPDF pour télécharger le dernier paquet directement depuis leur site web. Une fois téléchargé, suivez les étapes ci-dessous pour ajouter le paquet au projet.
Le programme IronPDF nous permet d'effectuer l'extraction de texte du fichier PDF et de convertir les pages PDF en objets PDF. Voici un exemple d'utilisation d'IronPDF pour lire un PDF existant.
La première approche consiste à extraire le texte d'un PDF et l'exemple de code est présenté ci-dessous.
using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();Imports IronPdf
Private pdfDocument = PdfDocument.FromFile("result.pdf")
Private AllText As String = pdfDocument.ExtractAllText()LesFromFile la méthode statique est utilisée pour charger le document PDF à partir d'un fichier existant et le transformer enPDFDocument comme le montre le code ci-dessus. Cet objet permet de lire le texte et les images accessibles sur les pages du PDF. L'objet possède une méthode appeléeExtraireToutTexte qui extrait tout le texte de l'ensemble du document PDF, puis conserve le texte extrait dans une chaîne de caractères que nous pouvons utiliser pour le traiter.
Voici l'exemple de code pour la deuxième méthode que nous pouvons utiliser pour extraire le texte d'un fichier PDF, page par page.
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}Using pdf As PdfDocument = PdfDocument.FromFile("result.pdf")
For index = 0 To pdf.PageCount - 1
Dim Text As String = pdf.ExtractTextFromPage(index)
Next index
End UsingDans le code ci-dessus, nous voyons qu'il va d'abord charger l'ensemble du document PDF et le convertir en un objet PDF. Ensuite, nous obtenons le nombre de pages de l'ensemble du document PDF à l'aide d'une méthode intégrée appeléePageCountle nombre total de pages disponibles dans le document PDF chargé est alors affiché. L'utilisation de la "boucle pour" et de laExtraitTexteDePage permet de passer le numéro de page en paramètre pour extraire le texte du document chargé. Le texte exact sera alors enregistré dans la variable "string". De même, il extraira le texte du PDF page par page à l'aide de la boucle "for" ou "for each".
IronPDF est une bibliothèque PDF polyvalente et puissante conçue pour rendre le travail avec les PDF dans les applications .NET fluide. Ses fonctionnalités robustes permettent aux développeurs de créer, manipuler et extraire du contenu des PDFs sans dépendre de tiers comme Adobe Reader. L'une des capacités remarquables d'IronPDF est sa capacité à extraire du texte des documents PDF. Cette fonctionnalité est inestimable pour automatiser des tâches telles que l'analyse des données, l'indexation des documents, la migration de contenu et l'activation des fonctionnalités d'accessibilité. En permettant aux développeurs de récupérer et de traiter du texte par programmation, IronPDF simplifie les flux de travail et ouvre de nouvelles possibilités pour la gestion du contenu PDF.
Avec une intégration simple et un support multiplateforme, IronPDF est un excellent choix pour les développeurs cherchant à gérer efficacement les documents PDF. En outre, IronPDF offre un service deessai gratuit, vous permettant d'explorer toute sa gamme de fonctionnalités sans risque avant de vous engager. Pour connaître les détails des prix et en savoir plus sur les options de licence, visitez notre sitepage de tarification.
Kye Stuart allie passion pour le codage et compétences en écriture chez Iron Software. Formé au Yoobee College en déploiement logiciel, il transforme désormais des concepts techniques complexes en contenu éducatif clair. Kye valorise l'apprentissage tout au long de la vie et accueille les nouveaux défis technologiques.
En dehors du travail, il apprécie les jeux PC, le streaming sur Twitch, et les activités de plein air comme le jardinage et les promenades avec son chien, Jaiya. L'approche directe de Kye en fait un élément clé de la mission d'Iron Software pour démystifier la technologie pour les développeurs du monde entier.
Clé d'essai de 30 jours instantanément.
Clé d'essai de 15 jours instantanément.
Votre clé d'essai devrait se trouver dans l'email.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
 Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaireInstall-Package IronPdf

Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.
Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau