Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


La possibilité de convertir des fichiers ou du contenu HTML en pages PDF est une fonction précieuse dans de nombreuses applications. En C#, il est assez fastidieux de construire une application à partir de zéro pour générer des fichiers au format HTML vers PDF. Dans cet article, nous allons donc voir comment convertir du HTML en PDF en C# à l'aide de la bibliothèque wkhtmltopdf.
wkhtmltopdf est un outil open-source en ligne de commande qui transforme de manière transparente des pages de texte HTML en documents PDF de haute qualité. En exploitant ses fonctionnalités dans des programmes C#, nous pouvons facilement convertir le contenu d'une chaîne HTML au format PDF. Découvrons étape par étape le processus de conversion d'une page HTML en PDF en C# à l'aide de la bibliothèque wkhtmltopdf.
Pour créer un convertisseur de fichiers HTML en fichiers PDF en C#, nous devons vérifier que les éléments suivants sont en place :
Un compilateur C++ tel que GCC ou Clang installé sur votre système.
wkhtmltopdf library installée. Vous pouvez télécharger la dernière version à partir du site officielwkhtmltopdf site web et installez-le conformément aux instructions de votre système d'exploitation.
Pour créer un projet de conversion PDF en C++ dans Code::Blocks, procédez comme suit :
Ouvrez l'IDE Code::Blocks.
Allez dans le menu "Fichier" et sélectionnez "Nouveau" puis "Projet" pour ouvrir l'assistant Nouveau projet.
Dans l'assistant Nouveau projet, sélectionnez "Application console".
Sélectionnez le langage C#.
Définissez le titre du projet et l'endroit où vous souhaitez l'enregistrer. Cliquez sur "Suivant" pour continuer.
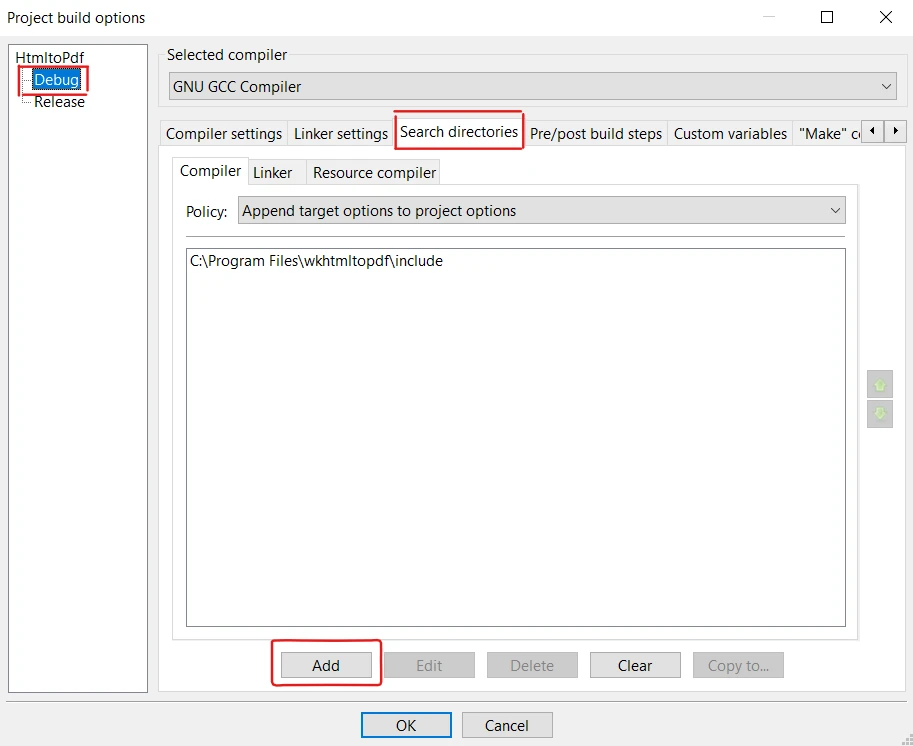
Pour que Code::Blocks puisse trouver les fichiers d'en-tête nécessaires, nous devons configurer les répertoires de recherche.
Cliquez sur le menu "Projet" dans la barre de menu et sélectionnez "Options de construction". Veillez à sélectionner "Debug".
Dans la boîte de dialogue "Build options", sélectionnez l'onglet "Search directories".
Sous l'onglet "Compilateur", cliquez sur le bouton "Ajouter".
Naviguez jusqu'au répertoire où se trouvent les fichiers d'en-tête wkhtmltox(par exemple, C:\NProgram Files\NWkhtmltopdf\Ninclude)et le sélectionner.
Enfin, cliquez sur "OK" pour fermer la boîte de dialogue.
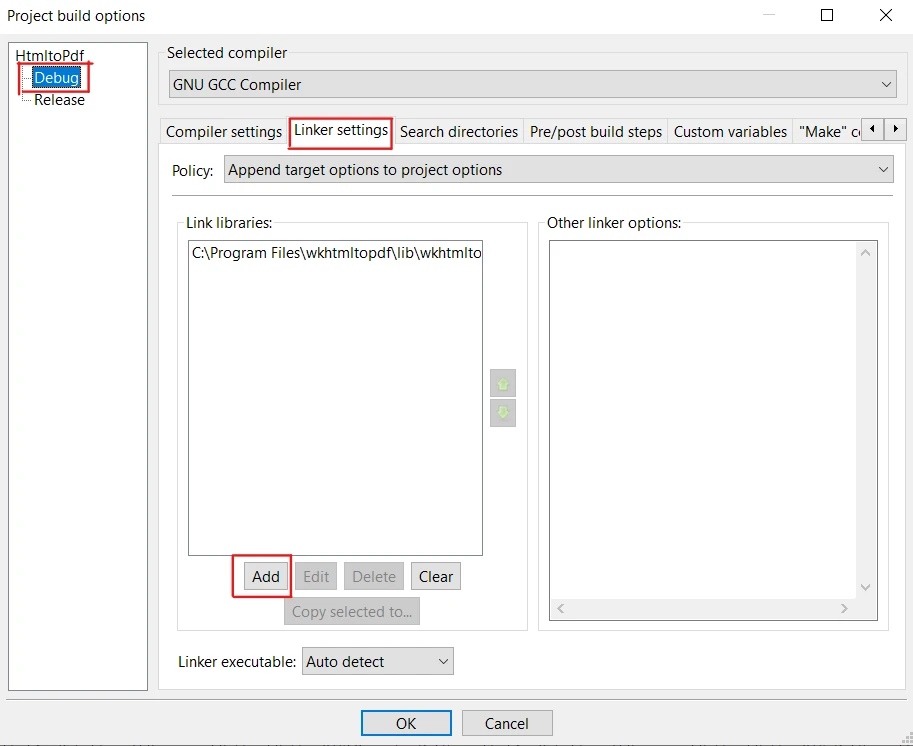
Pour établir un lien avec la bibliothèque wkhtmltox, procédez comme suit :
Cliquez à nouveau sur le menu "Projet" dans la barre de menu et sélectionnez "Options de construction". Veillez à sélectionner "Debug".
Dans la boîte de dialogue "Build options", sélectionnez l'onglet "Linker settings".
Sous l'onglet "Bibliothèques de liens", cliquez sur le bouton "Ajouter".
Naviguez jusqu'au répertoire où se trouvent les fichiers de la bibliothèque wkhtmltox(par exemple, C:\NProgram Files\NWkhtmltopdf\lib (fichiers de programmes))et sélectionnez le fichier de bibliothèque approprié.
Cliquez sur "Ouvrir" pour ajouter la bibliothèque à votre projet.
Enfin, cliquez sur "OK" pour fermer la boîte de dialogue.
Pour commencer, incluez les fichiers d'en-tête nécessaires pour utiliser les fonctionnalités de la bibliothèque wkhtmltopdf dans votre programme C++. Incluez les fichiers d'en-tête suivants au début du fichier de code source main.cpp, comme indiqué dans l'exemple suivant :
#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>
#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>
#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>Pour convertir HTML en PDF, nous devons initialiser le convertisseur wkhtmltopdf. Le code est le suivant :
wkhtmltopdf_init(false);
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings();
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings();
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs);
wkhtmltopdf_init(false);
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings();
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings();
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs);
wkhtmltopdf_init(False)
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings()
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings()
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs)Fournissons maintenant le contenu HTML qui doit être converti en PDF. Vous pouvez soit charger un fichier HTML, soit fournir directement la chaîne de caractères.
string htmlString = "<html><body><h1>Hello, World!</h1></body></html>"; wkhtmltopdf_add_object(converter, os, htmlString.c_str());
string htmlString = "<html><body><h1>Hello, World!</h1></body></html>"; wkhtmltopdf_add_object(converter, os, htmlString.c_str());
Dim htmlString As String = "<html><body><h1>Hello, World!</h1></body></html>"
wkhtmltopdf_add_object(converter, os, htmlString.c_str())Le convertisseur et le contenu HTML étant prêts, nous pouvons procéder à la conversion du HTML en fichier PDF. Utilisez l'extrait de code suivant :
wkhtmltopdf_convert(converter);
wkhtmltopdf_convert(converter);
wkhtmltopdf_convert(converter)La fonction wkhtmltopdf_get_output permet d'obtenir les données PDF existantes sous forme de flux de mémoire tampon. Il renvoie également la longueur du PDF. L'exemple suivant permet d'effectuer cette tâche :
const unsigned char* pdfData;
const int pdfLength = wkhtmltopdf_get_output(converter, &pdfData);
const unsigned char* pdfData;
const int pdfLength = wkhtmltopdf_get_output(converter, &pdfData);
const unsigned Char* pdfData
Const pdfLength As Integer = wkhtmltopdf_get_output(converter, &pdfData)Une fois la conversion terminée, nous devons enregistrer le fichier PDF généré sur le disque. Indiquez le chemin d'accès au fichier dans lequel vous souhaitez enregistrer le PDF. Ensuite, à l'aide d'un flux de fichiers de sortie, ouvrez le fichier en mode binaire et écrivez-y les pdfData. Enfin, fermez le fichier. Voici un exemple de code :
const char* outputPath = "file.pdf";
ofstream outputFile(outputPath, ios::binary);
outputFile.write(reinterpret_cast<const char*>(pdfData), pdfLength);
outputFile.close();
const char* outputPath = "file.pdf";
ofstream outputFile(outputPath, ios::binary);
outputFile.write(reinterpret_cast<const char*>(pdfData), pdfLength);
outputFile.close();
const Char* outputPath = "file.pdf"
ofstream outputFile(outputPath, ios:=:=binary)
outputFile.write(reinterpret_cast<const Char*>(pdfData), pdfLength)
outputFile.close()Après avoir converti HTML en PDF, il est essentiel de nettoyer les ressources allouées par wkhtmltopdf. Utilisez l'extrait de code suivant :
wkhtmltopdf_destroy_converter(converter);
wkhtmltopdf_destroy_object_settings(os);
wkhtmltopdf_destroy_global_settings(gs);
wkhtmltopdf_deinit();
cout << "PDF saved successfully." << endl;
wkhtmltopdf_destroy_converter(converter);
wkhtmltopdf_destroy_object_settings(os);
wkhtmltopdf_destroy_global_settings(gs);
wkhtmltopdf_deinit();
cout << "PDF saved successfully." << endl;
wkhtmltopdf_destroy_converter(converter)
wkhtmltopdf_destroy_object_settings(os)
wkhtmltopdf_destroy_global_settings(gs)
wkhtmltopdf_deinit()
cout << "PDF saved successfully." << endlMaintenant, construisez le projet et exécutez le code en utilisant la touche F9. Le résultat est généré et enregistré dans le dossier du projet. Le PDF résultant est le suivant :
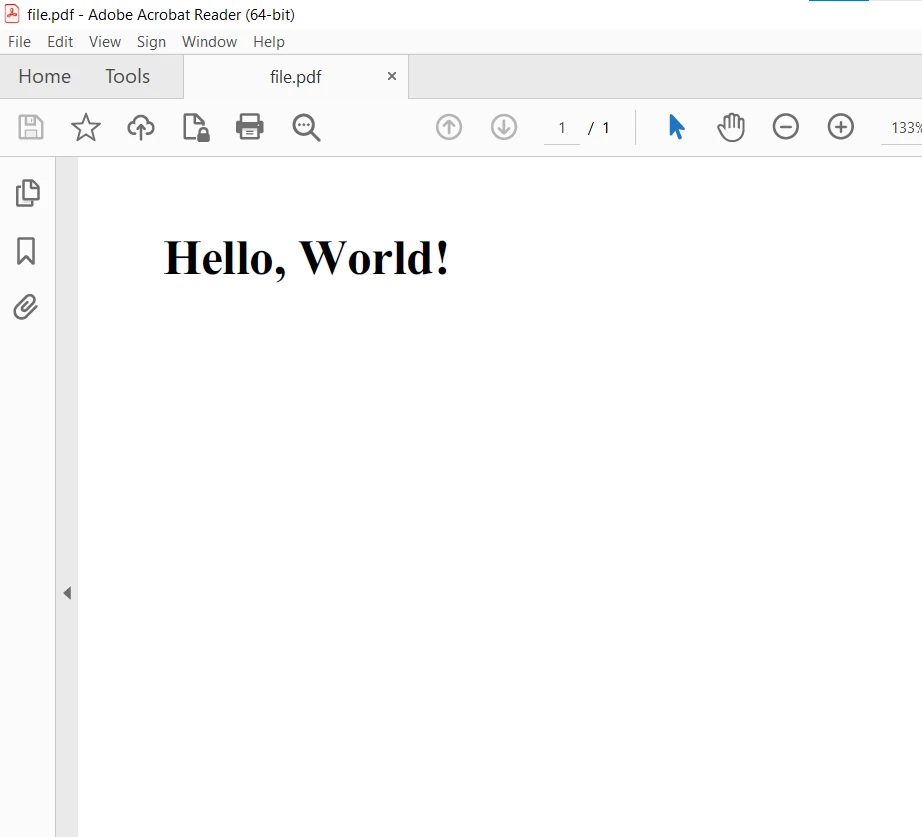
Bibliothèque de conversion HTML-PDF d'IronPDF est une bibliothèque .NET et .NET Core C# robuste qui permet aux développeurs de générer des documents PDF à partir de contenu HTML sans effort. Il fournit une API simple et intuitive qui simplifie le processus de conversion des pages web HTML en PDF, ce qui en fait un choix populaire pour diverses applications et cas d'utilisation.
L'un des principaux avantages d'IronPDF est sa polyvalence. Il permet non seulement de convertir des documents HTML simples, mais aussi des pages web complexes avec des styles CSS, des interactions JavaScript et même du contenu dynamique. De plus, vous pouvez développer différents convertisseurs PDF avec un accès rapide à ses méthodes de conversion.
Voici l'exemple de code à convertirChaîne HTML vers PDF à l'aide d'IronPDF en C# :
using IronPdf;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create PDF content from an HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
using IronPdf;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create PDF content from an HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
Imports IronPdf
' Instantiate Renderer
Private renderer = New ChromePdfRenderer()
' Create PDF content from an HTML string using C#
Private pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>")
' Export to a file or Stream
pdf.SaveAs("output.pdf")La sortie PDF :

Pour plus de détails sur la manière de convertir différents fichiers HTML, URL de pages Web et images en PDF, veuillez consulter le site suivantExemples de code HTML vers PDF.
Avec IronPDF, la génération de fichiers PDF à partir de contenu HTML devient une tâche simple dans les langages du Framework .NET. Son API intuitive et ses nombreuses fonctionnalités en font un outil précieux pour les développeurs qui ont besoin de convertir des données sur la santéHTML vers PDF dans leurs projets C#. Qu'il s'agisse de générer des rapports, des factures ou tout autre document nécessitant une conversion précise de HTML en PDF, IronPDF est une solution fiable et efficace.
IronPDF est gratuit à des fins de développement, mais pour une utilisation commerciale, il doit faire l'objet d'une licence. Il fournit également uneEssai gratuit de toutes les fonctionnalités d'IronPDF pour un usage commercial afin de tester l'ensemble de ses fonctionnalités. Vous pouvez télécharger le logiciel à partir deTélécharger IronPDF.
Install-Package IronPdf

Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.
Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau