Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Parallel.ForEachest une méthode en C# qui vous permet d'effectuer des itérations parallèles sur une collection ou une source de données. Au lieu de traiter chaque élément de la collection de manière séquentielle, une boucle parallèle permet une exécution simultanée, ce qui peut améliorer considérablement les performances en réduisant le temps d'exécution global. Le traitement parallèle fonctionne en répartissant le travail sur plusieurs processeurs, permettant ainsi aux tâches de s'exécuter simultanément. Ceci est particulièrement utile lorsque vous traitez des tâches indépendantes les unes des autres.
Contrairement à une boucle foreach normale, qui traite les éléments séquentiellement, l'approche parallèle peut gérer des ensembles de données volumineux beaucoup plus rapidement en utilisant plusieurs threads en parallèle.
IronPDFest une bibliothèque puissante pour gérer les PDF dans .NET, capable de convertir HTML en PDF, extraction de texte à partir de PDF, fusion et division de documentset bien d'autres choses encore. Lorsque vous traitez de grands volumes de tâches PDF, l'utilisation du traitement parallèle avec Parallel.ForEach peut réduire significativement le temps d'exécution. Que vous génériez des centaines de PDFs ou que vous extrayiez des données de plusieurs fichiers à la fois, tirer parti du parallélisme de données avec IronPDF garantit que les tâches sont complétées plus rapidement et plus efficacement.
Ce guide est destiné aux développeurs .NET qui souhaitent optimiser leurs tâches de traitement PDF en utilisant IronPDF et Parallel.ForEach. Il est recommandé d'avoir une connaissance de base du C# et une familiarité avec la bibliothèque IronPDF. À la fin de ce guide, vous serez en mesure de mettre en œuvre le traitement parallèle pour gérer plusieurs tâches PDF simultanément, améliorant ainsi à la fois la performance et l'évolutivité.
Pour utiliserIronPDFdans votre projet, vous devez installer la bibliothèque via NuGet.
Pour installer IronPDF, suivez ces étapes :
Ouvrez votre projet dans Visual Studio.
Allez dans Outils → Gestionnaire de paquetages NuGet → Gérer les paquetages NuGet pour la solution.
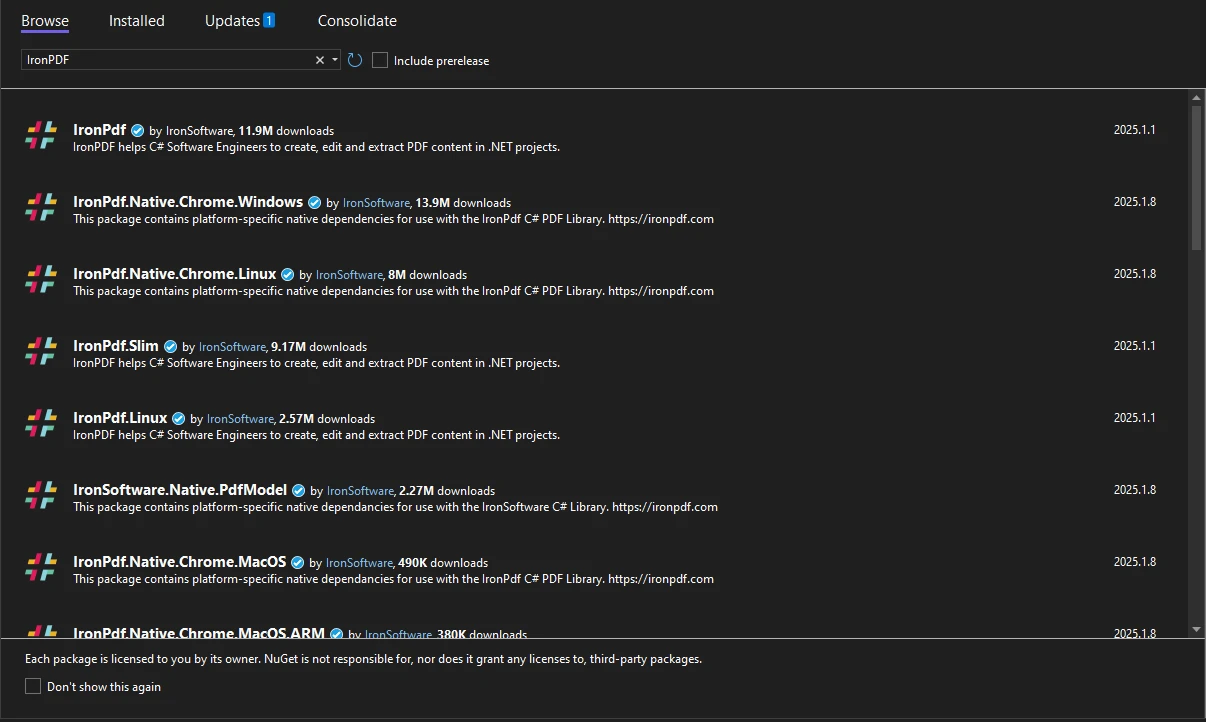
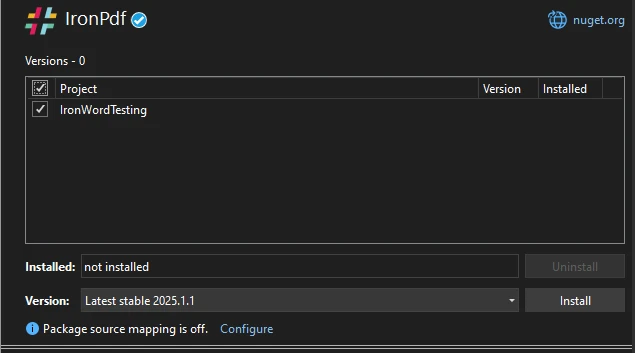
Alternativement, vous pouvez l'installer via la console du gestionnaire de packages NuGet :
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfUne fois IronPDF installé, vous êtes prêt à commencer à l'utiliser pour des tâches de génération et de manipulation de PDF.
Parallel.ForEach fait partie de l'espace de noms System.Threading.Tasks et offre un moyen simple et efficace d'exécuter des itérations en parallèle. La syntaxe pour Parallel.ForEach est la suivante :
Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, Sub(item)
' Code to process each item
End Sub)Chaque élément de la collection est traité en parallèle, et le système décide comment répartir la charge de travail sur les threads disponibles. Vous pouvez également spécifier des options pour contrôler le degré de parallélisme, comme le nombre maximal de threads utilisés.
En comparaison, une boucle foreach traditionnelle traite chaque élément l'un après l'autre, tandis qu'une boucle parallèle peut traiter plusieurs éléments simultanément, améliorant ainsi les performances lors de la gestion de grandes collections.
Tout d'abord, assurez-vous qu'IronPDF est installé comme décrit dans la section Prise en main. Après cela, vous pouvez commencer à écrire votre logique de traitement PDF parallèle.
string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});Dim htmlPages() As String = { "page1.html", "page2.html", "page3.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
End Sub)Ce code démontre comment convertir plusieurs pages HTML en PDFs en parallèle.
Lorsqu'il s'agit de tâches parallèles, la gestion des erreurs est cruciale. Utilisez des blocs try-catch à l'intérieur de la boucle Parallel.ForEach pour gérer les exceptions.
Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, Sub(pdfFile)
Try
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractAllText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
Catch ex As Exception
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}")
End Try
End Sub)Un autre cas d'utilisation du traitement parallèle est l'extraction de texte à partir d'un lot de PDF. Lorsqu'il s'agit de plusieurs fichiers PDF, effectuer l'extraction de texte de manière simultanée peut faire gagner beaucoup de temps. L'exemple suivant démontre comment cela peut être fait.
using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}Imports IronPdf
Imports System.Linq
Imports System.Threading.Tasks
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfFiles() As String = { "doc1.pdf", "doc2.pdf", "doc3.pdf" }
Parallel.ForEach(pdfFiles, Sub(pdfFile)
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
End Sub)
End Sub
End Class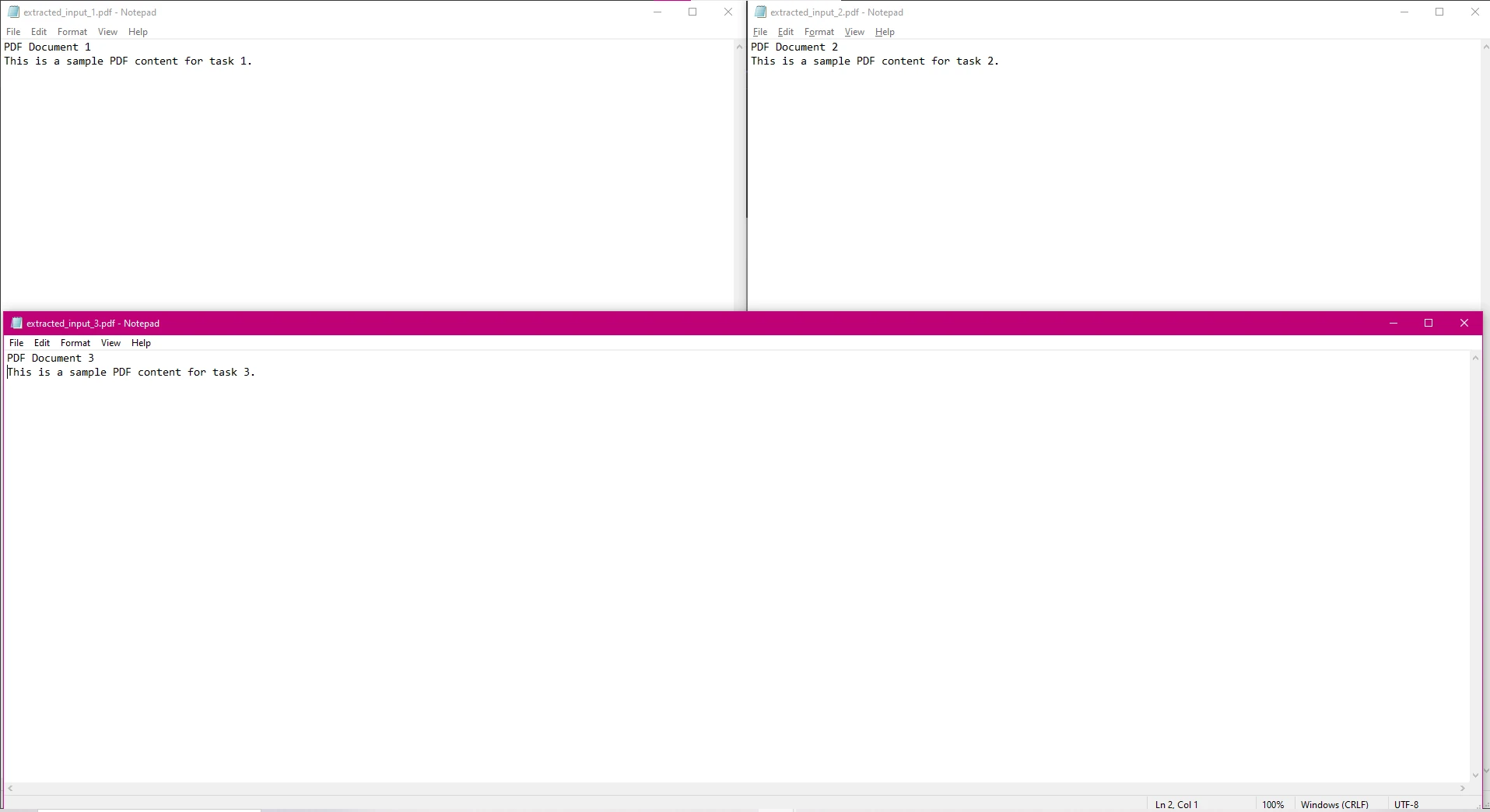
Dans ce code, chaque fichier PDF est traité en parallèle pour extraire le texte, et le texte extrait est enregistré dans des fichiers texte séparés.
Dans cet exemple, nous allons générer plusieurs PDF à partir d'une liste de fichiers HTML en parallèle, ce qui pourrait être un scénario typique lorsque vous avez besoin de convertir plusieurs pages HTML dynamiques en documents PDF.
using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});Imports IronPdf
Private htmlFiles() As String = { "example.html", "example_1.html", "example_2.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
Try
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlFileAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
Console.WriteLine($"PDF created for {htmlFile}")
Catch ex As Exception
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}")
End Try
End Sub)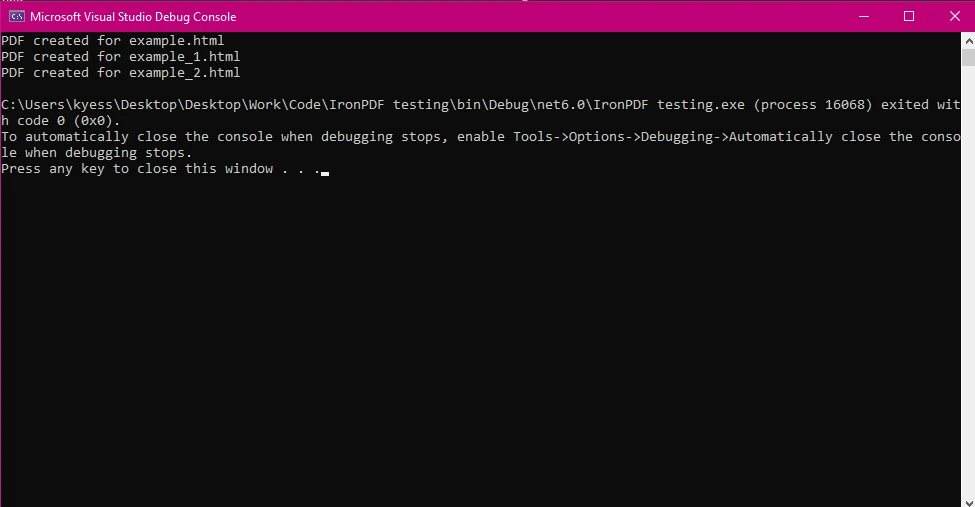
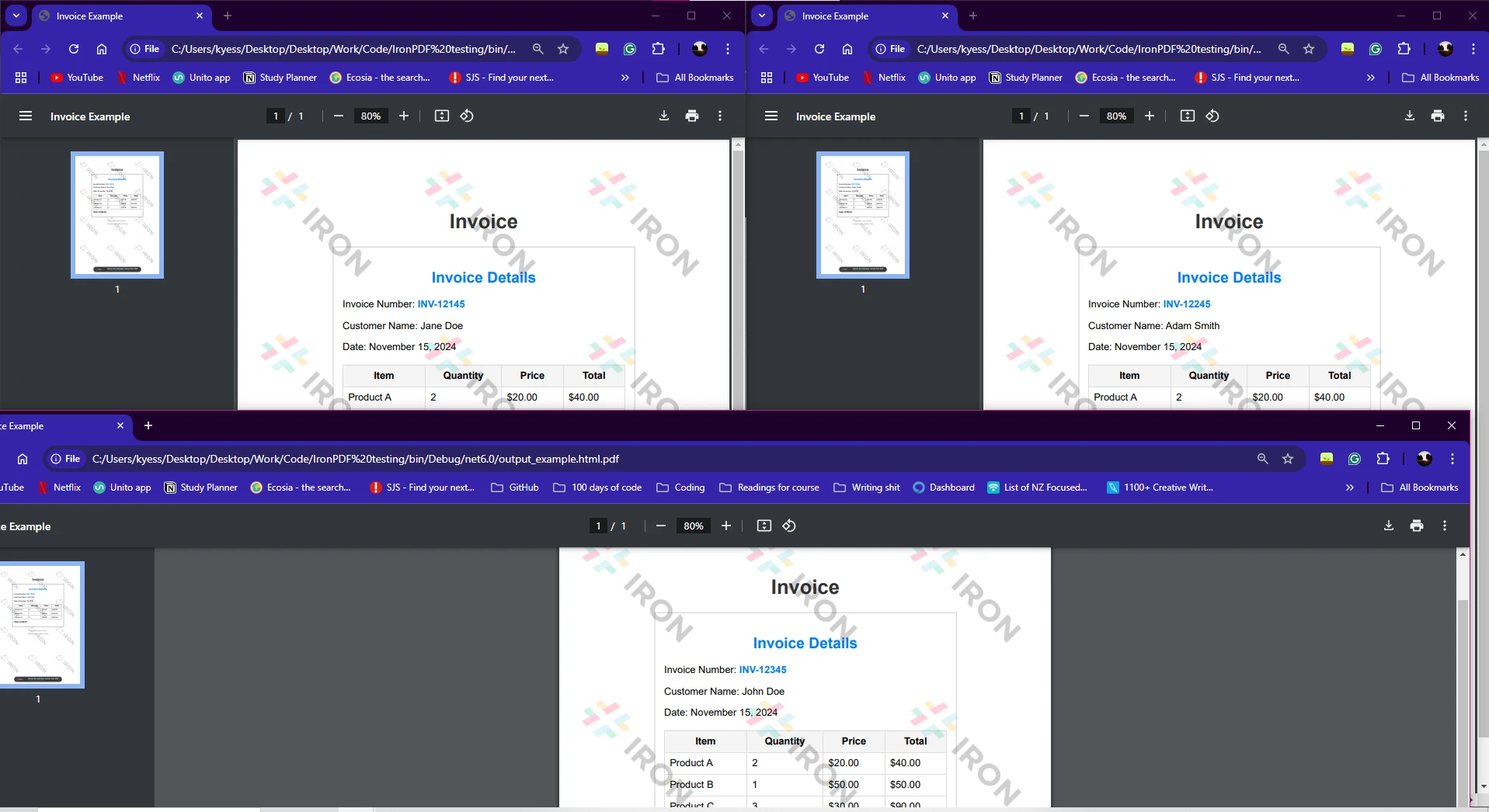
Fichiers HTML : Le tableau htmlFiles contient des chemins vers plusieurs fichiers HTML que vous souhaitez convertir en PDF.
Parallel.ForEach(fichiersHtml, fichierHtml =>{...}) traite chaque fichier HTML simultanément, ce qui accélère l'opération lorsqu'il s'agit de plusieurs fichiers.
Enregistrement du PDF : Après la génération du PDF, il est enregistré en utilisant la méthode pdf.SaveAs, en ajoutant le nom du fichier de sortie avec le nom du fichier HTML original.
IronPDF est sûr pour la plupart des opérations en termes de threads. Cependant, certaines opérations comme l'écriture sur le même fichier en parallèle peuvent poser des problèmes. Assurez-vous toujours que chaque tâche parallèle fonctionne sur un fichier de sortie ou une ressource séparée.
Pour optimiser les performances, envisagez de contrôler le degré de parallélisme. Pour les grandes ensembles de données, vous pouvez vouloir limiter le nombre de threads simultanés pour éviter une surcharge du système.
var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};Dim options = New ExecutionDataflowBlockOptions With {.MaxDegreeOfParallelism = 4}Lorsque vous traitez un grand nombre de PDF, soyez attentif à l'utilisation de la mémoire. Essayez de libérer les ressources comme les objets PdfDocument dès qu'elles ne sont plus nécessaires.
Une méthode d'extension est un type spécial de méthode statique qui vous permet d'ajouter de nouvelles fonctionnalités à un type existant sans modifier son code source. Cela peut être utile lorsque vous travaillez avec des bibliothèques comme IronPDF, où vous pourriez vouloir ajouter des méthodes de traitement personnalisées ou étendre sa fonctionnalité pour rendre le travail avec des PDF plus pratique, en particulier dans des scénarios de traitement parallèle.
En utilisant des méthodes d'extension, vous pouvez créer du code concis et réutilisable qui simplifie la logique dans les boucles parallèles. Cette approche non seulement réduit la duplication, mais vous aide également à maintenir une base de code propre, en particulier lorsqu'il s'agit de flux de travail PDF complexes et de parallélisme des données.
Utilisation de boucles parallèles comme Parallel.ForEach avecIronPDFoffre des gains de performance significatifs lors du traitement de grands volumes de PDF. Que vous soyez en train de convertir du HTML en PDF, d'extraire du texte ou de manipuler des documents, le parallélisme des données permet une exécution plus rapide en exécutant des tâches simultanément. L'approche parallèle garantit que les opérations peuvent être exécutées sur plusieurs processeurs à cœur, ce qui réduit le temps d'exécution global et améliore les performances pour les tâches de traitement par lots.
Bien que le traitement parallèle accélère les tâches, soyez attentif à la sécurité des threads et à la gestion des ressources. IronPDF est sûr pour les opérations threading pour la plupart des cas, mais il est important de gérer les conflits potentiels lors de l'accès aux ressources partagées. Tenez compte de la gestion des erreurs et de la gestion de la mémoire pour garantir la stabilité, surtout à mesure que votre application évolue.
Si vous êtes prêt à plonger plus profondément dans IronPDF et à explorer des fonctionnalités avancées, ledocumentation officielle, vous permettant de tester la bibliothèque dans vos propres projets avant de vous engager à un achat.
Install-Package IronPdf

Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.
Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau