Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Dans le paysage dynamique de la gestion des documents numériques, la capacité d'extraire sans effort des données de fichiers PDF est une tâche fondamentale qui sous-tend une multitude d'applications. Le processus d'extraction du texte est vital pour des objectifs tels que l'analyse complète des données, l'indexation du contenu, l'utilisation commerciale et la manipulation du texte. Parmi la panoplie d'outils disponibles, iTextSharp, une bibliothèque C# très appréciée, apparaît comme une solution exceptionnelle pour l'extraction de texte à partir de fichiers PDF.
Dans cet article complet, nous allons nous plonger dans les riches capacités d'iTextSharp, en explorant comment cette bibliothèque d'analyseur syntaxique puissante et polyvalente permet aux développeurs d'extraire efficacement le contenu textuel des documents PDF à l'aide du langage de programmation C#. Nous dévoilerons les méthodes essentielles, les exemples de techniques et les meilleures pratiques, afin d'équiper les développeurs des connaissances nécessaires pour exploiter efficacement iTextSharp pour l'extraction de texte. Nous allons également discuter et comparer la meilleure et la plus puissante bibliothèque PDF IronPDF dans ce billet.
Téléchargez la bibliothèque C# permettant d'extraire le texte d'un PDF.
Chargez un PDF existant en instanciant l'objet PdfReader.
Extraire du texte de l'objet PdfDocument en utilisant la méthode GetTextFromPage.
Instanciez la boucle foreach pour parcourir les lignes.
WriteLine.Présentation d'IronPDF, une bibliothèque de premier plan et riche en fonctionnalités dans le domaine du développement .NET, révolutionne la génération et la manipulation de PDF. Doté d'une suite complète d'outils, IronPDF facilite l'intégration transparente dans les applications C#, permettant la création, la modification et le rendu de documents PDF sans effort. Avec son API intuitive et ses fonctionnalités robustes, cette bibliothèque polyvalente ouvre un monde de possibilités pour générer des PDF de haute qualité à partir de HTML, d'images et de contenu. Dans cet article, nous allons explorer les capacités de IronPDF, en examinant ses fonctionnalités clés et en démontrant comment il peut être utilisé pour gérer efficacement les tâches liées aux PDF dans le C#.
iTextSharp, une bibliothèque réputée et puissante dans le domaine de la manipulation des PDF à l'aide de C#, a révolutionné la manière dont les développeurs traitent les documents PDF. Il s'agit d'un outil polyvalent et robuste qui facilite la création, la modification et l'extraction du contenu des fichiers PDF. iTextSharp permet aux développeurs de générer des PDF sophistiqués, d'extraire des images, de manipuler des documents existants et d'extraire des données, ce qui en fait une solution de choix pour un large éventail d'applications. Dans cet article, nous allons nous pencher sur les capacités et les caractéristiques d'iTextSharp, en explorant comment il peut être utilisé efficacement pour gérer et manipuler les PDF dans l'environnement de programmation C#.
L'installation d'IronPDF est un processus simple, voici les étapes pour installer et intégrer IronPDF dans votre projet C#.
Ouvrez Visual Studio et créez un nouveau projet ou ouvrez un projet existant.
Allez dans Outils et sélectionnez NuGet Package Manager dans le menu déroulant.
Dans le nouveau menu latéral, sélectionnez NuGet Package Manager for Solution.
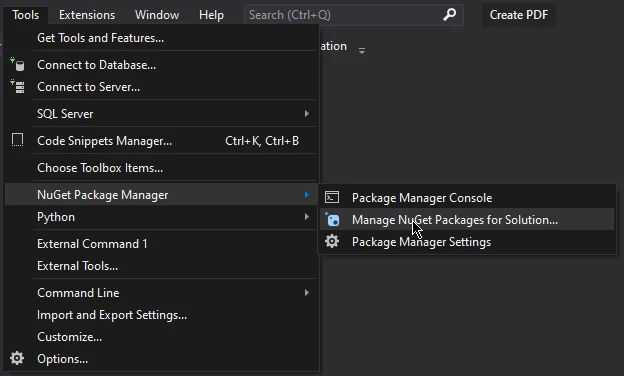
Dans la fenêtre "NuGet Package Manager", sélectionnez l'onglet "Browse".
Dans la barre de recherche, tapez "IronPDF" et appuyez sur Entrée.
La liste des instances IronPDF apparaît, sélectionnez la dernière version et appuyez sur Installer.
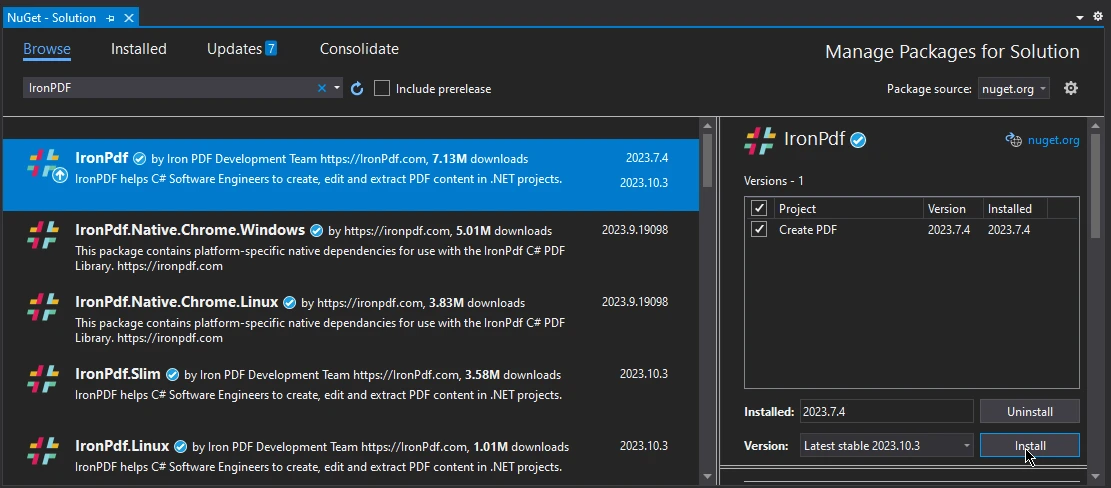
C'est ainsi qu'IronPDF est installé et prêt à être utilisé dans votre projet C#.
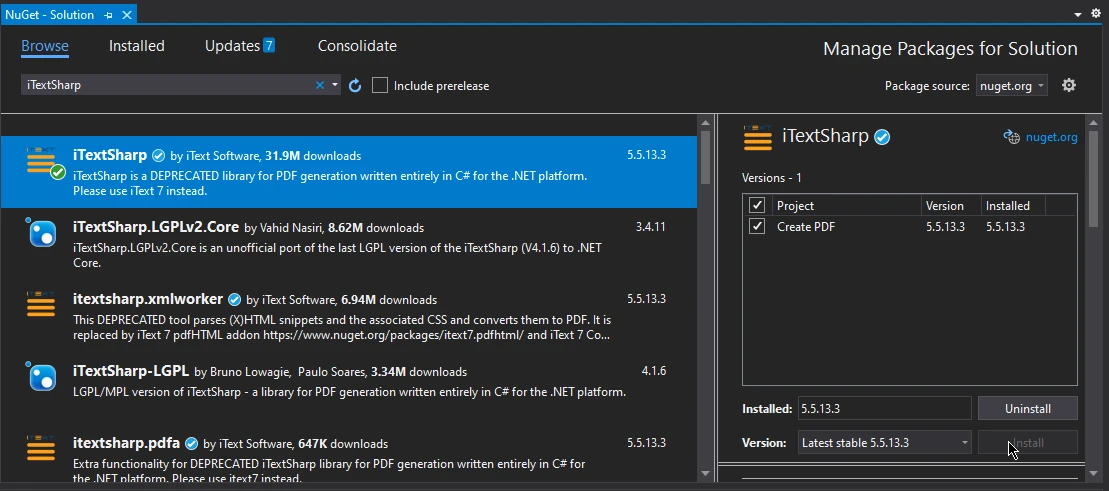
L'installation de la bibliothèque PDF d'iTextSharp est identique à celle d'IronPDF. Répétez toutes les étapes expliquées ci-dessus, recherchez simplement "iTextSharp" au lieu d'IronPDF dans les fenêtres de navigation, sélectionnez dans la liste des paquets, et cliquez sur installer pour intégrer la bibliothèque PDF iTextSharp dans votre projet.
IronPDF offre la possibilité d'extraire du texte à partir de fichiers PDF afin d'extraire automatiquement le texte en fonction de pages spécifiques ou d'extraire du texte à partir de tous les PDF. Dans l'exemple de code ci-dessous, nous verrons comment extraire du texte d'une page spécifique d'un exemple de document PDF.
using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);Imports IronPdf
Imports System
Private PdfDocument As using
Private Text As String = PDF.ExtractTextFromPage(1)
Console.Write(Text)Le code ci-dessus utilise la bibliothèque IronPDF en C# pour extraire du texte d'un fichier PDF et l'afficher dans la console. Tout d'abord, les espaces de noms nécessaires sont importés, notamment IronPDF et System. Le code charge ensuite un document PDF intitulé "Watermarked.pdf" dans un objet PdfDocument en utilisant la méthode FromFile. Ensuite, il extrait le texte de la deuxième page du PDF en utilisant ExtractTextFromPage et le stocke dans une variable chaîne nommée Text. Enfin, le texte extrait est affiché dans la console en utilisant Console.Write.

Vous pouvez également extraire du texte de fichiers PDF à l'aide d'iTextSharp. Voici un exemple d'utilisation de la bibliothèque iTextSharp.
using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Text
Imports iTextSharp.text.pdf
Imports iTextSharp.text.pdf.parser
Namespace PDFApp2
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim filePath As String = "C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf"
Dim outPath As String = "C:\Users\buttw\OneDrive\Desktop\name.txt"
Dim pagesToScan As Integer = 2
Dim strText As String = String.Empty
Try
Dim reader As New PdfReader(filePath)
For page As Integer = 1 To pagesToScan
Dim its As ITextExtractionStrategy = New iTextSharp.text.pdf.parser.LocationTextExtractionStrategy()
strText = PdfTextExtractor.GetTextFromPage(reader, page, its)
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)))
Dim lines() As String = strText.Split(ControlChars.Lf)
For Each line As String In lines
Using file As New System.IO.StreamWriter(outPath, True)
file.WriteLine(line)
End Using
Next line
Next page
reader.Close()
Catch ex As Exception
Console.Write(ex)
End Try
End Sub
End Class
End NamespaceLe code fourni est un programme C# qui utilise la bibliothèque iTextSharp pour extraire du texte de pages spécifiques d'un document PDF et l'enregistrer dans un fichier texte. Tout d'abord, les espaces de noms nécessaires sont importés, y compris System.Text, iTextSharp.text.pdf et iTextSharp.text.pdf.parser. Le programme spécifie le nom du fichier, le chemin du fichier PDF d'entrée, le chemin du fichier texte de sortie et le nombre de pages à numériser. Il utilise ensuite le PdfReader d'iTextSharp pour lire le fichier PDF. Pour chaque page spécifiée, il utilise la nouvelle LocationTextExtractionStrategy d'iTextSharp pour extraire le texte, convertissant l'encodage en UTF-8. Le texte extrait est divisé en lignes, et le nouveau texte StringBuilder du code PDF fonctionne dans le bon sens. Toutes les exceptions rencontrées au cours du processus sont capturées et affichées dans la console. Le programme se termine en fermant le PdfReader.

iTextSharp, une bibliothèque C# puissante et polyvalente, révolutionne la manipulation des PDF en permettant la création, la modification et l'extraction de contenu en toute transparence. Ses fonctionnalités robustes en font une solution de choix pour les développeurs, leur permettant de générer des PDF sophistiqués et de gérer efficacement le contenu textuel des PDF. En outre, IronPDF, une autre bibliothèque de premier plan dans le domaine .NET, offre une suite complète d'outils pour la génération de PDF et la manipulation d'images, améliorant ainsi la capacité des développeurs à créer, modifier et restituer sans effort des PDF de haute qualité à partir de diverses sources. Lorsqu'on compare ces deux bibliothèques PDF, IronPDF prend l'avantage en raison de son API bien documentée et facile à utiliser, qui exécute également toute l'extraction de texte en seulement quelques lignes de code, tandis qu'avec iTextSharp, vous devez écrire un code long et complexe et avoir une connaissance approfondie de la bibliothèque et de C#.
Pour en savoir plus sur les Fonctionnalités de IronPDF et ses caractéristiques, visitez la page officielle. Le tutoriel complet pour extraire du texte en utilisant IronPDF est disponible à cette IronPDF Text Extraction Tutorial. Pour un tutoriel complet sur IronPDF et iTextSharp, veuillez visiter la Comparaison IronPDF vs iTextSharp.
Install-Package IronPdf

Aucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit





![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.
Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau