Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de Python


XGBoost significa eXtreme Gradient Boosting, un algoritmo de aprendizaje automático poderoso y preciso. Se ha aplicado principalmente en análisis de regresión, clasificación y problemas de clasificación. Incluye características como la regulación que ayudan a evitar el sobreajuste,paralelismoy procesamiento de datos faltantes.
IronPDF es una biblioteca de Python para crear, modificar y leer archivos PDF. Facilita la conversión de HTML, imágenes o texto en PDFs, y también puede agregar encabezados, pies de página y marcas de agua. Aunque está principalmente relacionado con su uso en Python, es notable que la herramienta NET se puede implementar en este lenguaje de programación con la ayuda de herramientas de interoperabilidad como Python.
La combinación de XGBoost e IronPDF ofrece aplicaciones más amplias. A través de IronPDF, el resultado de la previsión se puede combinar con la creación de documentos PDF interactivos. Esta combinación es especialmente útil para generar documentos y cifras corporativas precisas y los resultados obtenidos de los modelos predictivos aplicados.
XGBoost es una poderosa biblioteca de aprendizaje automático para Python basada en el aprendizaje en conjunto, que es altamente eficiente y flexible. XGBoost es una implementación de un algoritmo de mejora de gradiente por Tianqi Chen que incluye optimizaciones adicionales. La efectividad ha sido probada en muchos dominios de aplicación con tareas correspondientes que pueden ser resueltas por este método, tales como clasificación, regresión, tareas de ranking, etc. XGBoost tiene varias características únicas: La ausencia de valores faltantes no es un problema para él; Existe una oportunidad de utilizar normas L1 y L2 para luchar contra el sobreajuste;
El entrenamiento se realiza en paralelo, lo que acelera significativamente el proceso de entrenamiento. La poda de árboles también se realiza en orden de profundidad en XGBoost, lo que ayuda a gestionar la capacidad del modelo. Una de sus características es la validación cruzada de hiperparámetros y funciones integradas para evaluar el rendimiento del modelo. La biblioteca interactúa bien con otras utilidades de ciencia de datos integradas en un entorno Python, como NumPy, SciPy y sci-kit-learn, lo que hace posible incorporarla en un entorno confirmado. Aun así, debido a su rapidez, simplicidad y alto rendimiento, XGBoost se ha convertido en la herramienta esencial en el 'arsenal' de muchos analistas de datos, especialistas en aprendizaje automático y aspirantes a científicos de datos de redes neuronales.
XGBoost es famoso por sus numerosas características que lo hacen ventajoso en varias tareas de aprendizaje automático y algoritmos de aprendizaje automático, así como por hacerlo más accesible de implementar. A continuación se presentan las características principales de XGBoost en Python. A continuación, se presentan las características clave de XGBoost en Python:
Regularización:
Aplica técnicas de regularización L1 y L2 para reducir el sobreajuste y aumentar el rendimiento del modelo.
Procesamiento Paralelo:
El modelo de preentrenamiento utiliza todos los núcleos de la CPU durante el entrenamiento, mejorando así significativamente el entrenamiento de modelos.
Manejo de datos faltantes:
Un algoritmo que, cuando el modelo está entrenado, decide automáticamente la mejor manera de trabajar con valores faltantes.
Poda de árboles:
En la poda de árboles, el recorrido en profundidad en los árboles se logra utilizando el parámetro "max_depth", lo que reduce el sobreajuste.
Validación cruzada integrada:
Incluye métodos de validación cruzada integrados para la evaluación de modelos y optimización de hiperparámetros. Al admitir y realizar la validación cruzada de forma nativa, la implementación es menos complicada.
Escalabilidad:
Está optimizado para la escalabilidad; por lo tanto, puede analizar grandes volúmenes de datos y manejar adecuadamente los datos del espacio de características.
Soporte para múltiples idiomas:
XGBoost fue desarrollado inicialmente en Python; Sin embargo, para mejorar su alcance, también admite R, Julia y Java.
Computación Distribuida:
El paquete está diseñado para ser distribuido, lo que significa que se puede ejecutar en múltiples computadoras para procesar grandes cantidades de datos.
Funciones Objetivo y de Evaluación Personalizadas:
Permite a los usuarios configurar funciones objetivas y mediciones de rendimiento según sus requisitos específicos. Además, admite tanto la clasificación binaria como la de múltiples clases.
Importancia de la característica:
Ayuda a identificar el valor de varias características, puede asistir en la selección de características para un conjunto de datos dado y proporciona interpretaciones de múltiples modelos.
Consciente de dispersiones
Funciona bien con formatos de datos dispersos, lo cual es muy útil cuando se trabaja con datos que contienen muchos valores NULL o ceros.
Integración con otras bibliotecas:
Complementa la popularidad rápidamente ganada de las bibliotecas de ciencia de datos como NumPy, SciPy y sci-kit-learn, que son fáciles de integrar en los flujos de trabajo de la ciencia de datos.
En Python, hay múltiples procesos involucrados en la creación y configuración de un modelo XGBoost: el proceso de recopilación y preprocesamiento de datos, creación del modelo, gestión del modelo y evaluación del modelo. A continuación, se presenta una guía detallada que te ayudará a comenzar:
Instalar XGBoost
Primero, comprueba si el paquete Xgboost está en tu sistema. Puedes instalarlo en tu computadora con pip:
pip install xgboostImportar bibliotecas
import xgboost as xgb
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorPreparar los datos
En este ejemplo, vamos a usar el conjunto de datos de viviendas de Boston:
# Load the Boston housing dataset
boston = load_boston()
#load default value from the package
X = boston.data
y = boston.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Crear DMatrix
XGBoost utiliza una estructura de datos auto-definida llamada DMatrix para el entrenamiento.
# Create DMatrix for training and testing sets
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)Establecer parámetros
Configure los parámetros del modelo. Un ejemplo de configuración es el siguiente:
# Set parameters
params = {
'objective': 'reg:squarederror', # Objective function
'max_depth': 4, # Maximum depth of a tree
'eta': 0.1, # Learning rate
'subsample': 0.8, # Subsample ratio of the training instances
'colsample_bytree': 0.8, # Subsample ratio of columns when constructing each tree
'seed': 42 # Random seed for reproducibility
}Entrenar el modelo
Utilice el método train para entrenar un modelo XGBoost.
# Number of boosting rounds
num_round = 100
# Train the model
bst = xgb.train(params, dtrain, num_round)Hacer predicciones
Ahora, utiliza este modelo entrenado y realiza predicciones en el conjunto de prueba.
# Make predictions
preds = bst.predict(dtest)Evaluar el modelo
Verifica el rendimiento del modelo de aprendizaje automático utilizando una medida métrica adecuada, por ejemplo, el error cuadrático medio.
# Calculate mean squared error
mse = mean_squared_error(y_test, preds)
print(f"Mean Squared Error: {mse}")Guardar y Cargar el Modelo
Puede guardar el modelo entrenado en un archivo y cargarlo más tarde si es necesario:
# Save the model
bst.save_model('xgboost_model.json')
# Load the model performance
bst_loaded = xgb.Booster()
bst_loaded.load_model('xgboost_model.json')A continuación se muestra el archivo JSON generado.

A continuación se muestra la instalación base de ambas bibliotecas, con un ejemplo de cómo comenzar a usar XGBoost para el análisis de datos y IronPDF para generar informes PDF.
Utilice el potente paquete de Python IronPDF para generar, manipular y leer PDFs. Esto permite a los programadores realizar múltiples operaciones basadas en programación con PDFs, como trabajar con PDFs preexistentes y convertir HTML en archivos PDF. IronPDF es una solución eficiente para aplicaciones que requieren la generación dinámica y el procesamiento de PDF, ya que proporciona una forma adaptable y amigable de generar documentos PDF de alta calidad.
IronPDF puede crear documentos PDF a partir de cualquier contenido HTML, nuevo o existente. Permite la creación de publicaciones artísticas y hermosas en PDF a partir de contenido web que capturan el poder del HTML5, CSS3 y JavaScript modernos en todas sus formas.
Puede agregar texto, imágenes, tablas y otros contenidos en documentos PDF generados programáticamente nuevos. Usando IronPDF, los documentos PDF existentes pueden abrirse y editarse para una modificación posterior. En un PDF, puedes editar/agregar contenido y eliminar contenido específico en el documento según sea necesario.
Utiliza CSS para estilizar el contenido en PDFs. Soporta diseños complejos, fuentes, colores y todos esos componentes de diseño. Además, las formas de renderizar material HTML que pueden utilizarse con JavaScript permiten la creación de contenido dinámico en PDFs.
IronPDF se puede instalar a través de Pip. Utilice el siguiente comando para instalarlo:
pip install ironpdfImporte todas las bibliotecas relevantes y cargue su conjunto de datos. En nuestro caso, utilizaremos el conjunto de datos de viviendas de Boston:
import xgboost as xgb
import numpy as np
from ironpdf import * from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
boston = load_boston()
X = boston.data
y = boston.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Train model
num_round = 100
bst = xgb.train(params, dtrain, num_round)
# Make predictions
preds = bst.predict(dtest)
# Create a PDF document
iron_pdf = ChromePdfRenderer()
# Create HTML content
html_content = f"""
<html>
<head>
<title>XGBoost Model Report</title>
</head>
<body>
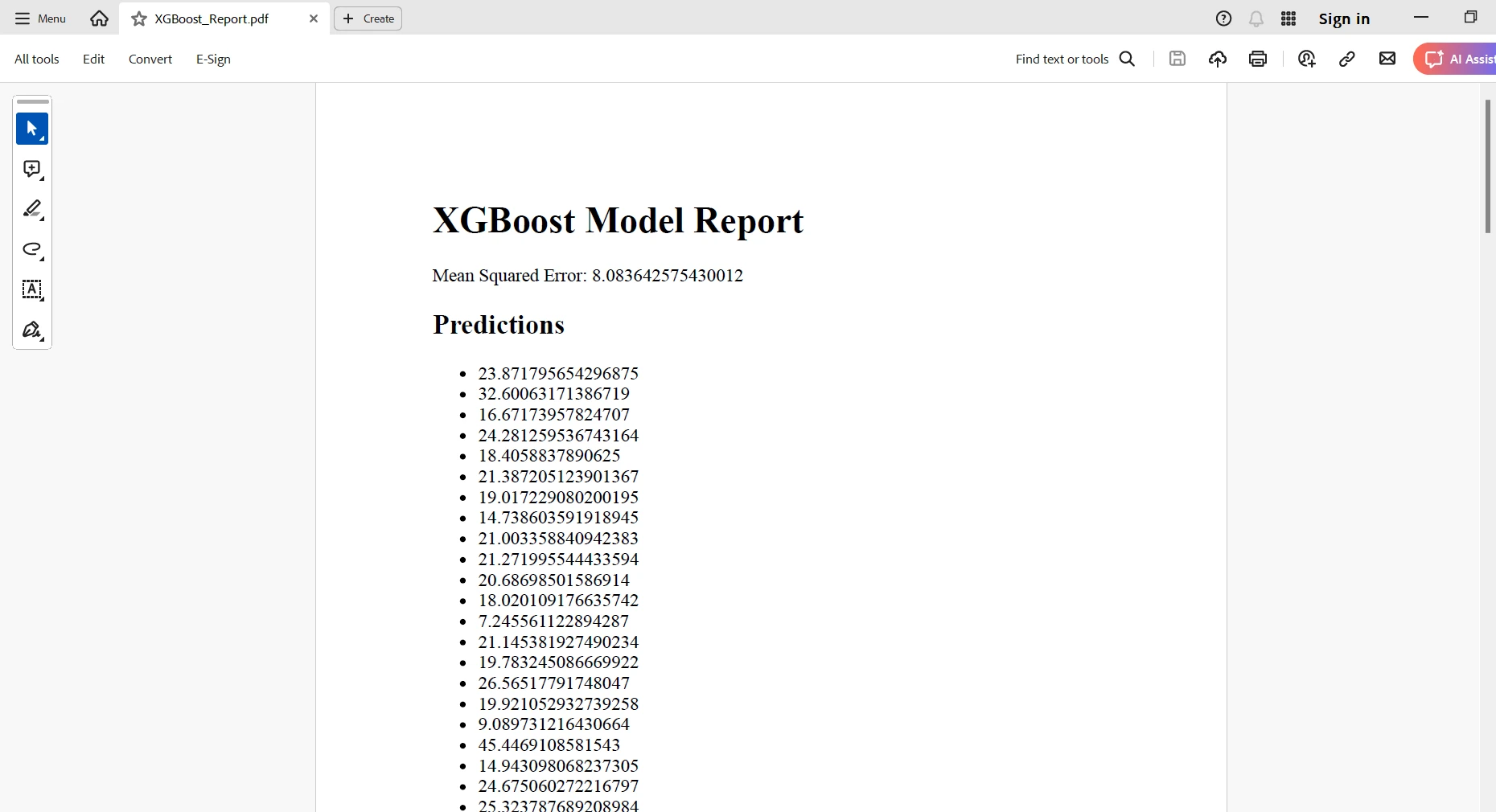
<h1>XGBoost Model Report</h1>
<p>Mean Squared Error: {mse}</p>
<h2>Predictions</h2>
<ul>
{''.join([f'<li>{pred}</li>' for pred in preds])}
</ul>
</body>
</html>
"""
pdf=iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("XGBoost_Report.pdf")
print("PDF document generated successfully.")Ahora, crearás objetos de la clase DMatrix para manejar tus datos de manera eficiente, luego configurarás los parámetros del modelo relacionados con la función objetivo y los hiperparámetros. Después de entrenar el modelo XGBoost, predice en el conjunto de prueba; puedes usar el Error Cuadrático Medio o métricas similares para evaluar el rendimiento. A continuación, utiliza IronPDF para crear un PDF con todos los resultados.
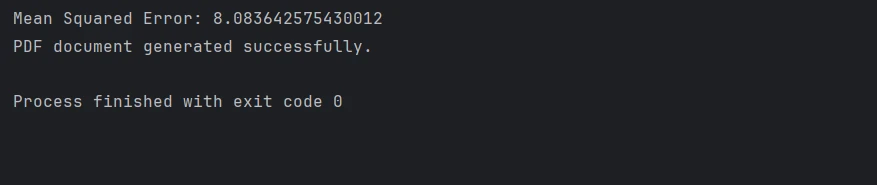
Creas una representación HTML con todos tus resultados; luego, usará la clase RenderHtmlAsPdf de IronPDF para convertir este contenido HTML en unDocumento PDF. Finalmente, puedes guardar este informe PDF generado en la ubicación deseada. En otras palabras, esta integración te permitirá automatizar la creación de informes muy elaborados y profesionales en los que se encapsulan las conclusiones derivadas de sus modelos de Machine Learning.
En resumen, XGBoost e IronPDF están integrados para un análisis de datos avanzado y la generación de informes profesionales. La eficiencia y escalabilidad de XGBoost proporcionan la mejor solución en streaming a través de tareas complejas de aprendizaje automático con capacidades predictivas robustas y excelentes herramientas para la optimización de modelos. Puedes usar Python para vincular estos pesos pesados juntos en Python con IronPDF sin problemas, convirtiendo los ricos insights obtenidos de XGBoost en informes PDF altamente detallados.
Estas integraciones permitirán considerablemente la producción de documentos atractivos y ricos en información con respecto a los resultados, haciéndolos comunicables a las partes interesadas o adecuados para un análisis posterior. El análisis de negocios, la investigación académica o cualquier proyecto basado en datos no habrían sido posibles sin una sinergia integrada entre XGBoost e IronPDF para procesar datos de manera eficiente y comunicar los hallazgos con facilidad.
IntegrarIronPDF yIronSoftwareproductos para asegurar que sus clientes y usuarios finales obtengan soluciones de software premium y ricas en funciones. Esto también ayudará a optimizar tus proyectos y procesos.
Documentación completa, comunidad activa y actualizaciones frecuentes, todo va de la mano con la funcionalidad de IronPDF. Iron Software es el nombre de un socio confiable para proyectos modernos de desarrollo de software. IronPDF está disponible para una prueba gratuita para todos los desarrolladores. Pueden probar todas sus funciones. Las tarifas de licencia de $749 están disponibles para obtener el máximo valor de este producto.

pip install nombre-producto-versión del producto-py37-none-win_amd64.whiNo se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito

Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.

Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina