Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de Python


Trabajar con archivos PDF en Python es una habilidad imprescindible para los desarrolladores que construyen aplicaciones CLI.(s)y sistemas de procesamiento de datos. Ya sea que necesite extraer texto de documentos, recuperar texto y tablas de diseños complejos o agregar datos personalizados a los existentes.PDFs, elegir la biblioteca de Python adecuada es crucial.
La biblioteca de archivos PDF de Python ayuda a los desarrolladores a convertir cadenas HTML a PDF, procesar o agregar datos personalizados y realizar operaciones avanzadas como la extracción de tablas y texto con diversos grados de precisión. Esta guía completa explora cinco opciones populares de bibliotecas, incluyendoIronPDF, cada uno con capacidades y casos de uso distintos, para ayudarte a seleccionar la solución más adecuada para tus necesidades de manipulación de PDF.
IronPDF se presenta como una poderosa solución de procesamiento de PDF para desarrolladores de Python. Desarrollado sobre el robusto motor Chromium, se destaca en la conversiónHTML a PDFcon una precisión excepcional y preservación del formato. Puede convertir cadenas y archivos HTML a PDF. Puede utilizarlo también para extraer texto de los archivos PDF. La biblioteca fue diseñada específicamente para desarrolladores que necesitan capacidades de manipulación de PDF de nivel profesional en entornos de producción.
Ofrece una integración perfecta con las aplicaciones de Python existentes y admite operaciones tanto sincrónicas como asincrónicas. Lo que distingue a IronPDF es su capacidad para manejar diseños complejos, contenido dinámico y tecnologías web modernas como CSS3 y JavaScript. La biblioteca incluye soporte integrado para encabezados, pies de página, paginación y marcas de agua. Es ideal para generar documentos comerciales, informes, facturas y muchas otras operaciones relacionadas con PDF.
ReportLabse ha establecido como el estándar de facto para la generación de PDF en Python durante las dos últimas décadas. Es el motor detrás de la funcionalidad de exportación de PDF de Wikipedia y es utilizado por numerosas empresas de Fortune 500. La biblioteca ofrece dos versiones distintas: una edición comercial(ReportLab PLUS)y un conjunto de herramientas de código abierto.
En su esencia, ReportLab ofrece un motor de diseño de página robusto y una potente API de lienzo gráfico. La biblioteca se destaca en la generación programática de documentos complejos, especialmente aquellos que requieren un control preciso sobre el diseño y la maquetación. Incluye funciones como elementos fluidos.(elementos que pueden fluir a través de páginas)Tablas, gráficos, y gráficos vectoriales. La arquitectura de ReportLab está diseñada para manejar tanto documentos pequeños como el procesamiento por lotes a gran escala de miles de documentos personalizados.
PyPDF2(y su bifurcaciónPyPDF4)es una biblioteca PDF pura de Python en el ecosistema de Python. Originalmente desarrollado como un fork de pypdf, ha evolucionado hasta convertirse en una solución estable y confiable para operaciones básicas de PDF. La biblioteca está escrita completamente en Python. Está diseñado con un enfoque en la manipulación de PDF en lugar de su creación. Es efectivo para tareas como fusionar, dividir y transformar documentos PDF existentes.
Incluye un soporte robusto para PDFs cifrados y puede manejar tanto la lectura como la escritura de los metadatos de PDF. La arquitectura de PyPDF2 es modular y permite a los desarrolladores trabajar con componentes PDF en varios niveles de abstracción. Puede instalarlo con este comando:
pip install pypdf
PyFPDFes una versión en Python de la popular biblioteca PHP PDF del mismo nombre. Proporciona un enfoque directo para la generación de PDF, centrándose en la simplicidad y facilidad de uso. La biblioteca fue diseñada con la filosofía de hacer que la creación de PDF sea tan simple como escribir archivos de texto plano. Gestiona todas las operaciones de PDF de bajo nivel mientras proporciona una interfaz de alto nivel para tareas comunes. PyFPDF incluye compatibilidad incorporada para múltiples fuentes, incluidas TrueType y Type1, y puede incrustar fuentes directamente en los documentos PDF. La biblioteca también ofrece soporte básico para HTML a través de su clase HTMLMixin.
PyMuPDF, también conocido como Fitz, es un enlace de alto rendimiento de Python para la biblioteca MuPDF. Destaca por su versatilidad en el manejo de múltiples formatos de documentos, no solo PDFs, incluyendo XPS, EPUB y varios formatos de imagen. PyMuPDF ofrece capacidades integrales de manipulación de documentos, incluyendo extracción avanzada de texto con información de posicionamiento precisa, extracción e inserción de imágenes, y manejo de anotaciones. La arquitectura de la biblioteca está diseñada para ofrecer tanto funciones de conveniencia de alto nivel como acceso de bajo nivel a las estructuras de PDF cuando sea necesario.
| Característica | IronPDF | ReportLab | PyPDF2 | FPDF | PyMuPDF |
| Creación de PDF | ✓ | ✓ | Limitado | ✓ | ✓ |
| Extracción de texto | Avanzado | Básico | Básico | No | Avanzado |
| Relleno de formularios | ✓ | ✓ | Limitado | No | ✓ |
| Compatibilidad con HTML | Avanzado | Básico | No | Limitado | Básico |
| Manejo de Imágenes | ✓ | ✓ | Limitado | ✓ | ✓ |
| Dependencias | .NET | Minimalista | Ninguno | Ninguno | Bibliotecas C |
| Licencia | Comercial | Dual | MIT | LGPL | GPL/Comercial |
Después de analizar estas bibliotecas de PDF para Python, IronPDF surge como una solución integral para las necesidades profesionales de desarrollo de PDF. Si bien cada biblioteca tiene sus fortalezas, la combinación de características, rendimiento y capacidades de nivel empresarial de IronPDF lo hace adecuado para entornos de producción. El motor basado en Chromium de la biblioteca garantiza una precisión superior en la conversión de HTML a PDF, mientras que su amplia API ofrece a los desarrolladores herramientas para manipulaciones complejas de PDF.
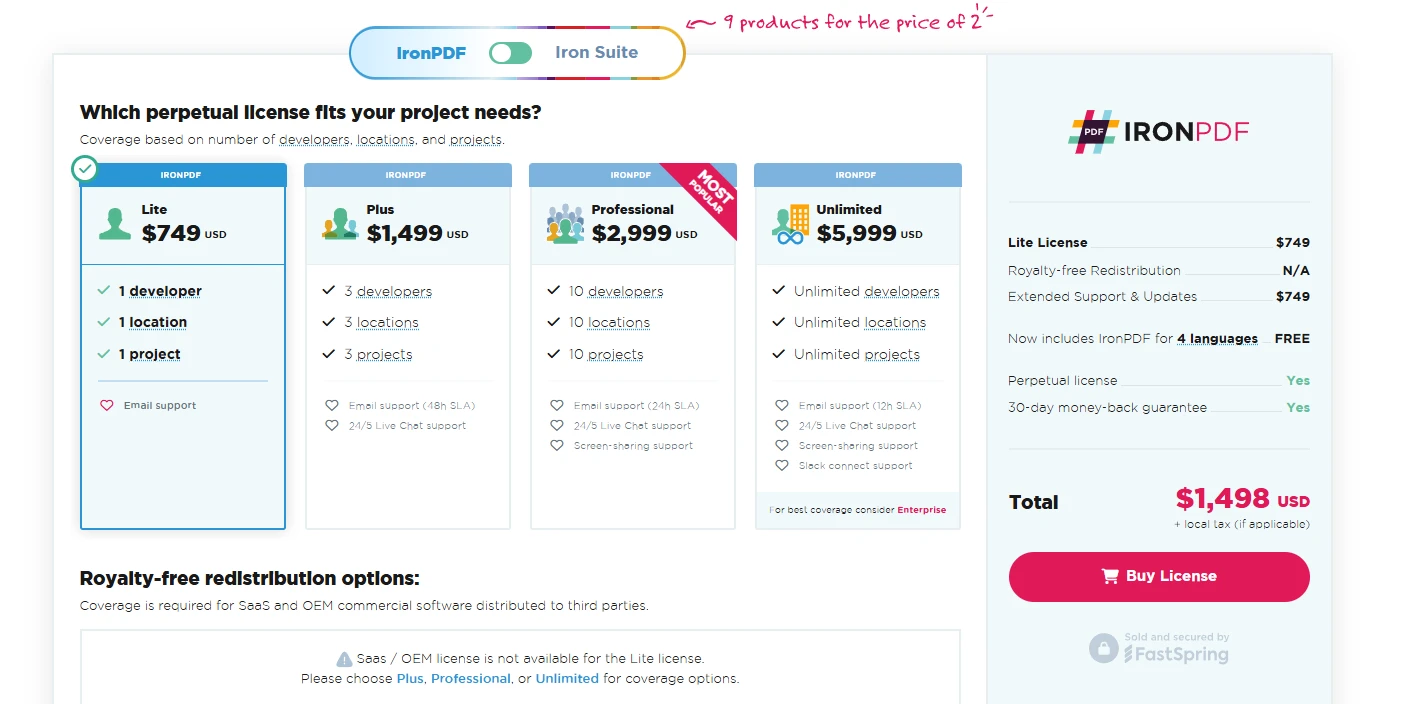
Para las empresas que requieren capacidades confiables de procesamiento de PDF, el sólido conjunto de características de IronPDF y su soporte profesional justifican su inversión comercial. IronPDF ofrece unprueba gratuita. La licencia comercial comienza en $749 por desarrollador, lo cual incluye soporte integral y actualizaciones regulares. IronPDF proporciona la fiabilidad, las características y el soporte necesarios para ofrecer soluciones de calidad profesional. Aunque existen alternativas gratuitas, el conjunto completo de funciones y las capacidades listas para la empresa de IronPDF lo convierten en una mejor elección.
Considere estos factores clave al elegir:
Consideraciones de mantenimiento a largo plazo
Ya sea que esté construyendo un sistema de gestión de documentos, generando informes o procesando formularios, IronPDF proporciona las herramientas y la estabilidad necesarias para una implementación exitosa.

pip install nombre-producto-versión del producto-py37-none-win_amd64.whiNo se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito

Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.

Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina