Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Este tutorial presenta cómo extraer mediante programación textos e imágenes de archivos PDF con el soporte de primera clase de IronPDF.
FromFile para analizar un archivo PDF en VB.NETExtractAllTextExtractTextFromPages para extraer texto de ciertas páginasExtractRawImagesFromPageEficaz conversión de PDF. Casi todo lo que puede hacer una máquina, también lo puede hacer IronPDF. Gracias a esta biblioteca PDF, los desarrolladores pueden crear, leer contenido de texto, escribir, cargar y manipular PDF rápidamente.
IronPDF convierte HTML en un registro PDF con la ayuda de la utilización del motor de Chrome. Junto con Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms y WPF. IronPDF también es compatible con aplicaciones Xamarin, Blazor, Unity y HoloLense. IronPDF es compatible con aplicaciones tanto de Microsoft .NET como de .NET Core (tanto los paquetes web ASP.NET como los paquetes convencionales de Windows). IronPDF puede utilizarse para crear PDF estéticamente atractivos.
IronPDF puede crear un PDF utilizando HTML5, JavaScript, CSS e imágenes. IronPDF también dispone de un potente conversor de HTML a PDF que se integra con PDF. IronPDF cuenta con un potente mecanismo de conversión de PDF que utiliza el motor de renderizado Chromium. Además, no está conectado a ninguna fuente externa.
Puede crear un archivo PDF a partir de un archivo CSS.
Para más detalles, visita esta página de información de licencias de IronPDF para obtener una clave limitada gratuita y la versión profesional.

IronPDF- Formato de fuente
IronPDF también puede leer y extraer texto de archivos PDF con la ayuda de las bibliotecas IronPDF. A continuación se muestra un patrón de código IronPDF que puede utilizarse para examinar archivos PDF presentes.
El siguiente ejemplo de código demuestra el primer método para adquirir todo el contenido del PDF como una cadena con sólo unas pocas líneas.
Imports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractAllText()
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractAllText()
Console.WriteLine(AllText)
End Sub
End ModuleEl código de muestra anterior demuestra cómo utilizar el método FromFile para leer un PDF de un archivo existente y convertirlo en un objeto de documento PDF. El objeto proporciona un método llamado ExtractAllText que extraerá texto plano del PDF y lo convertirá en una cadena.
El siguiente código de ejemplo muestra cómo extraer datos de un archivo PDF utilizando el número de página.
Imports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPage(0)
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPage(0)
Console.WriteLine(AllText)
End Sub
End ModuleEl código anterior muestra cómo leer un PDF de un archivo existente y convertirlo en un objeto de documento PDF utilizando la función FromFile. A través de este objeto se puede acceder a textos e imágenes en el PDF. El objeto ofrece un método llamado ExtractTextFromPage que permite enviar un número de página como parámetro para obtener una cadena que contiene cada palabra que estaba en la página del PDF.
El siguiente código muestra cómo extraer los datos entre varias páginas.
Imports IronPdf
Module Program
Sub Main(args As String())
Dim Pages As List(Of Integer) = New List(Of Integer)
Pages.Add(3)
Pages.Add(5)
Pages.Add(7)
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPages(Pages)
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim Pages As List(Of Integer) = New List(Of Integer)
Pages.Add(3)
Pages.Add(5)
Pages.Add(7)
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPages(Pages)
Console.WriteLine(AllText)
End Sub
End ModuleEl código anterior demuestra cómo usar el método FromFile para leer un PDF desde un archivo existente y convertirlo en un objeto de documento PDF. Este objeto permite examinar el texto y las imágenes en PDF. El objeto tiene un método llamado ExtractTextFromPages que se puede utilizar para obtener una cadena que incluye todo el contenido de texto en una página dada del documento pasando una lista de números de página como parámetro. Abajo a la izquierda está el PDF de origen y a la derecha los datos extraídos.
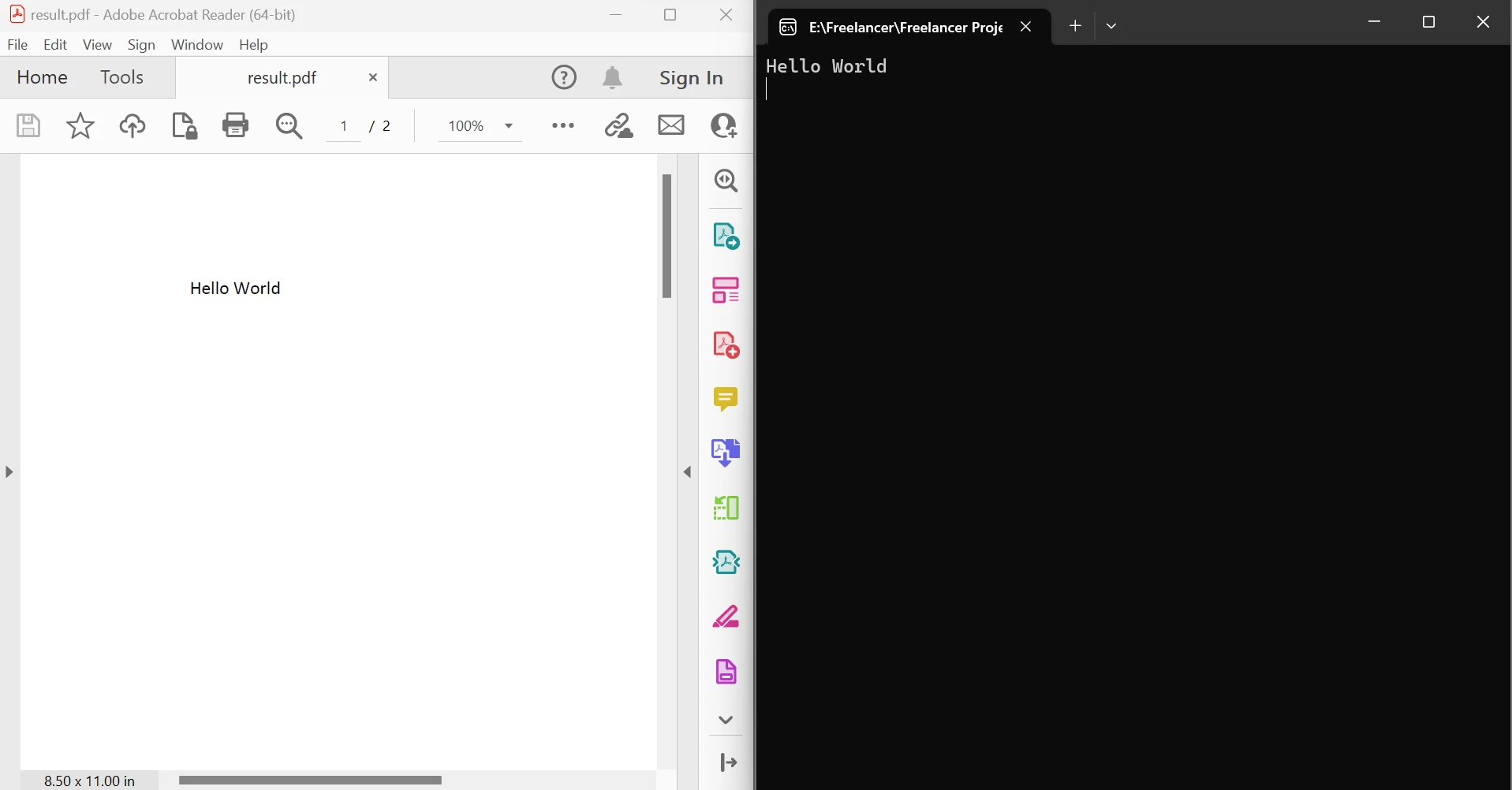
Extraer texto entre las páginas de salida
IronPDF proporciona una lista de métodos para extraer imágenes como:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtraerImágenesDePáginasExtractRawImagesFromPageCada método permite extraer imágenes de una página o de varias páginas del documento.
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
For Each As Byte() In images
Dim ms As New IO.MemoryStream(CType(, Byte()))
Dim image = New Bitmap(ms)
image.Save("output//test.jpg")
NextDim pdfdoc = PdfDocument.FromFile("result.pdf")
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
For Each As Byte() In images
Dim ms As New IO.MemoryStream(CType(, Byte()))
Dim image = New Bitmap(ms)
image.Save("output//test.jpg")
NextEl código anterior muestra cómo leer un documento de un archivo existente y convertirlo en un objeto de documento PDF utilizando la función FromFile. Al pasar una lista de números de página al método ExtractRawImagesFromPage del objeto, se puede obtener una lista de bytes que contiene cada imagen que estaba presente en una página determinada del documento. Usar un bucle foreach para manejar cada byte y convertirlo en un flujo de memoria. A continuación, en un mapa de bits, lo que ayuda a guardar la imagen. La siguiente imagen muestra la salida del código anterior.

Extraer imágenes del PDF de salida
Para conocer más sobre el tutorial de código de la API de IronPDF, consulte la documentación de IronPDF. También puedes visitar otros tutoriales para aprender cómo analizar texto de PDF usando C#.
La licencia de desarrollo de la biblioteca IronPDF es gratuita. Si se utiliza IronPDF en un entorno de producción, pueden adquirirse distintas licencias en función de las necesidades del desarrollador. El plan Lite comienza en $749 y no tiene costos continuos. También se ofrecen alternativas de redistribución SaaS y OEM. Todas las licencias incluyen actualizaciones, un año de soporte del producto y una licencia permanente. También son útiles para la fabricación, la puesta en escena y el desarrollo. Se trata de una compra única. Existen otras licencias gratuitas de duración limitada. Visite la información completa sobre las licencias de IronPDF para leer los detalles completos de precios y licencias para IronPDF. IronPDF también ofrece licencias gratuitas para la protección anticopia.
Install-Package IronPdf

No se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.
Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina