Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Encontrar texto dentro de un PDF puede ser una tarea desafiante, especialmente cuando se trabaja con archivos estáticos que no son fácilmente editables obuscable. Ya sea que estés automatizando flujos de trabajo de documentos, construyendo funcionalidades de búsqueda, necesitando resaltar texto que coincide con tus criterios de búsqueda o extrayendo datos, la extracción de texto es una característica crítica para los desarrolladores.
IronPDF, una potente biblioteca .NET, simplifica este proceso, permitiendo a los desarrolladores buscar yextraer textode PDFs. En este artículo, exploraremos cómo usar IronPDF para encontrar texto en un PDF utilizando C#, completo con ejemplos de código y aplicaciones prácticas.
"Encontrar texto" se refiere al proceso de buscar texto o patrones específicos dentro de un documento, archivo u otras estructuras de datos. En el contexto de archivos PDF, implica identificar y localizar instancias de palabras, frases o patrones específicos dentro del contenido de texto de un documento PDF. Esta funcionalidad es esencial para numerosas aplicaciones en diversas industrias, especialmente cuando se trata de datos no estructurados o semiestructurados almacenados en formato PDF.
Los archivos PDF están diseñados para presentar contenido en un formato coherente e independiente del dispositivo. Sin embargo, la forma en que se almacena el texto en los PDF puede variar ampliamente. El texto podría almacenarse como:
Diseños Complejos: Texto almacenado en fragmentos o con codificación inusual, lo que dificulta extraerlo y buscarlo con precisión.
Esta variabilidad significa que la búsqueda de texto efectiva en PDFs a menudo requiere bibliotecas especializadas, como IronPDF, que pueden manejar tipos de contenido diversos sin problemas.
La capacidad de encontrar texto en PDFs tiene una amplia gama de aplicaciones, incluyendo:
Automatización de flujos de trabajo: Automatización de tareas como el procesamiento de facturas, contratos o informes mediante la identificación de términos o valores clave en documentos PDF.
Extracción de Datos: Extracción de información para su uso en otros sistemas o para análisis.
Verificación de contenido: Asegurarse de que los términos o frases requeridos estén presentes en los documentos, como declaraciones de cumplimiento o cláusulas legales.
Encontrar texto en archivos PDF no siempre es sencillo debido a los siguientes desafíos:
IronPDFestá diseñado para hacer que la manipulación de PDF sea lo más fluida posible para los desarrolladores que trabajan en el ecosistema .NET. Ofrece un conjunto de funciones diseñadas para simplificar los procesos de extracción y manipulación de texto.
Facilidad de uso:
IronPDF cuenta con unAPI intuitiva, permitiendo a los desarrolladores comenzar rápidamente sin una curva de aprendizaje pronunciada. Ya sea que esté realizando una extracción de texto básica oConversión de HTML a PDF, o operaciones avanzadas, sus métodos son sencillos de usar.
Alta precisión:
A diferencia de algunas bibliotecas PDF que tienen dificultades con los PDFs que contienen diseños complejos o fuentes incrustadas, IronPDF extrae texto con precisión de manera confiable.
**Soporte multiplataforma
IronPDF es compatible tanto con .NET Framework como con .NET Core, lo que garantiza que los desarrolladores puedan utilizarlo en aplicaciones web modernas, aplicaciones de escritorio e incluso en sistemas heredados.
Soporte para consultas avanzadas:
La biblioteca admite técnicas de búsqueda avanzadas como expresiones regulares y extracción dirigida, lo que la hace adecuada para casos de uso complejos como la minería de datos o la indexación de documentos.
IronPDF está disponible a través de NuGet, lo que facilita su incorporación a tus proyectos .NET. Aquí tienes cómo empezar.
Ainstalar IronPDFutiliza el Administrador de paquetes NuGet en Visual Studio o ejecuta el siguiente comando en la Consola del Administrador de paquetes:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfEsto descargará e instalará la biblioteca junto con sus dependencias.
Una vez que la biblioteca esté instalada, debes incluirla en tu proyecto haciendo referencia al espacio de nombres de IronPDF. Agrega la siguiente línea al inicio de tu archivo de código:
using IronPdf;using IronPdf;Imports IronPdfIronPDF simplifica el proceso de encontrar texto dentro de un documento PDF. A continuación, se presenta una demostración paso a paso de cómo lograr esto.
El primer paso es cargar el archivo PDF con el que deseas trabajar. Esto se hace utilizando la clase PdfDocument como se ve en el siguiente código:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")La clase PdfDocument representa el archivo PDF en memoria, lo que te permite realizar varias operaciones como extraer texto o modificar contenido. Una vez que se ha cargado el PDF, podemos buscar texto en todo el documento PDF o en una página específica dentro del archivo.
Después de cargar el PDF, usa ExtractAllText()método para extraer el contenido de texto de todo el documento. A continuación, puedes buscar términos específicos utilizando técnicas estándar de manipulación de cadenas:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End ClassPDF de entrada
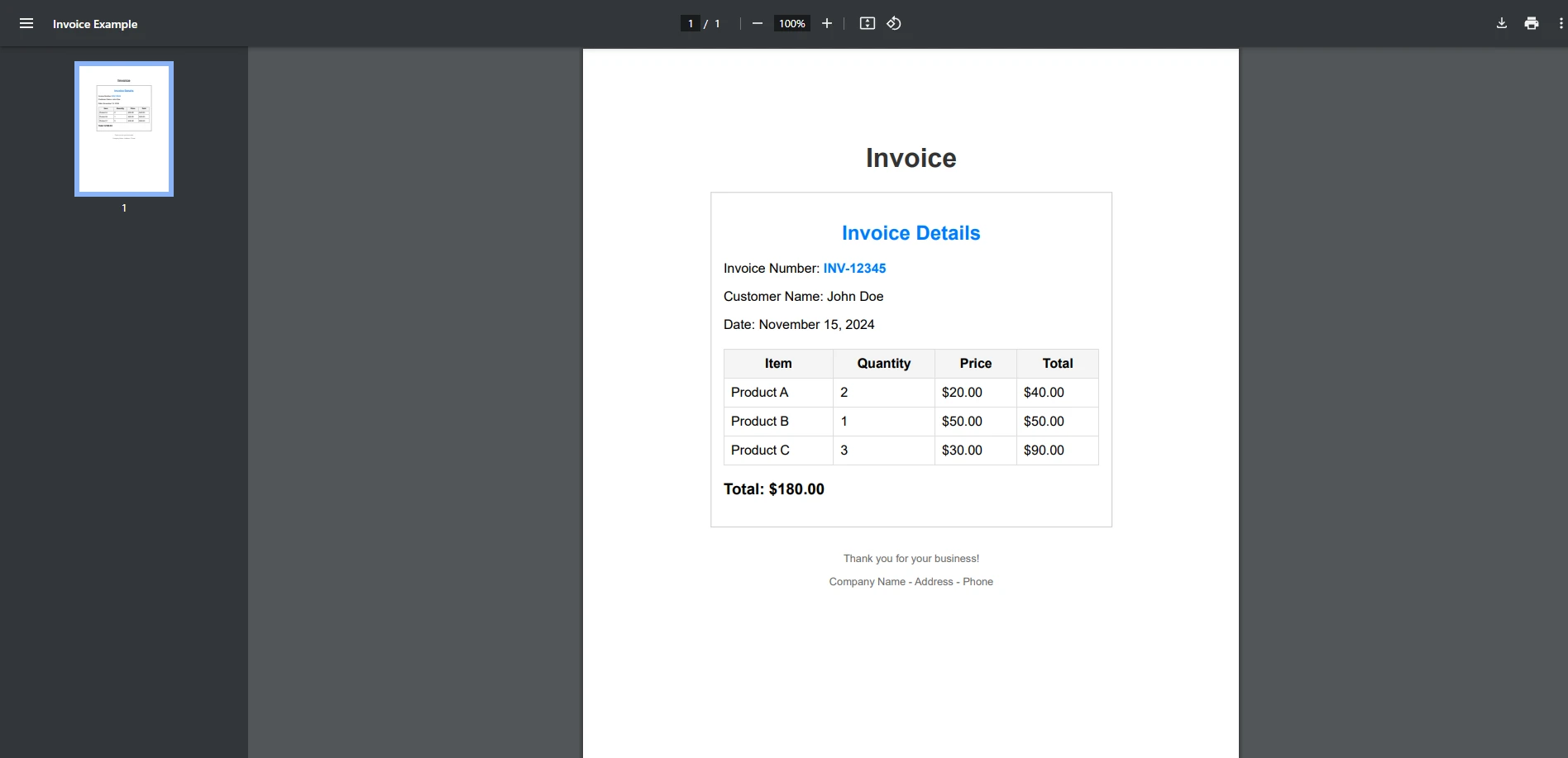
Salida de Consola
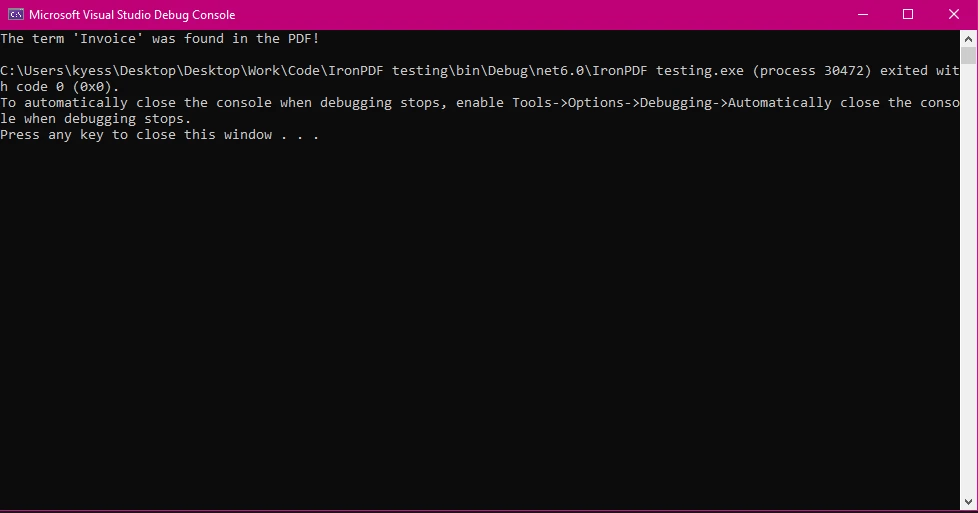
Este ejemplo demuestra un caso simple donde verificas si un término existe en el PDF. StringComparison.OrdinalIgnoreCase asegura que el texto buscado no distinga entre mayúsculas y minúsculas.
IronPDF ofrece varias funciones avanzadas que amplían sus capacidades de búsqueda de texto.
Las expresiones regulares son una herramienta poderosa para encontrar patrones dentro del texto. Por ejemplo, es posible que desee localizar todas las direcciones de correo electrónico en un PDF:
using System.Text.RegularExpressions;
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions;
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next matchPDF de entrada
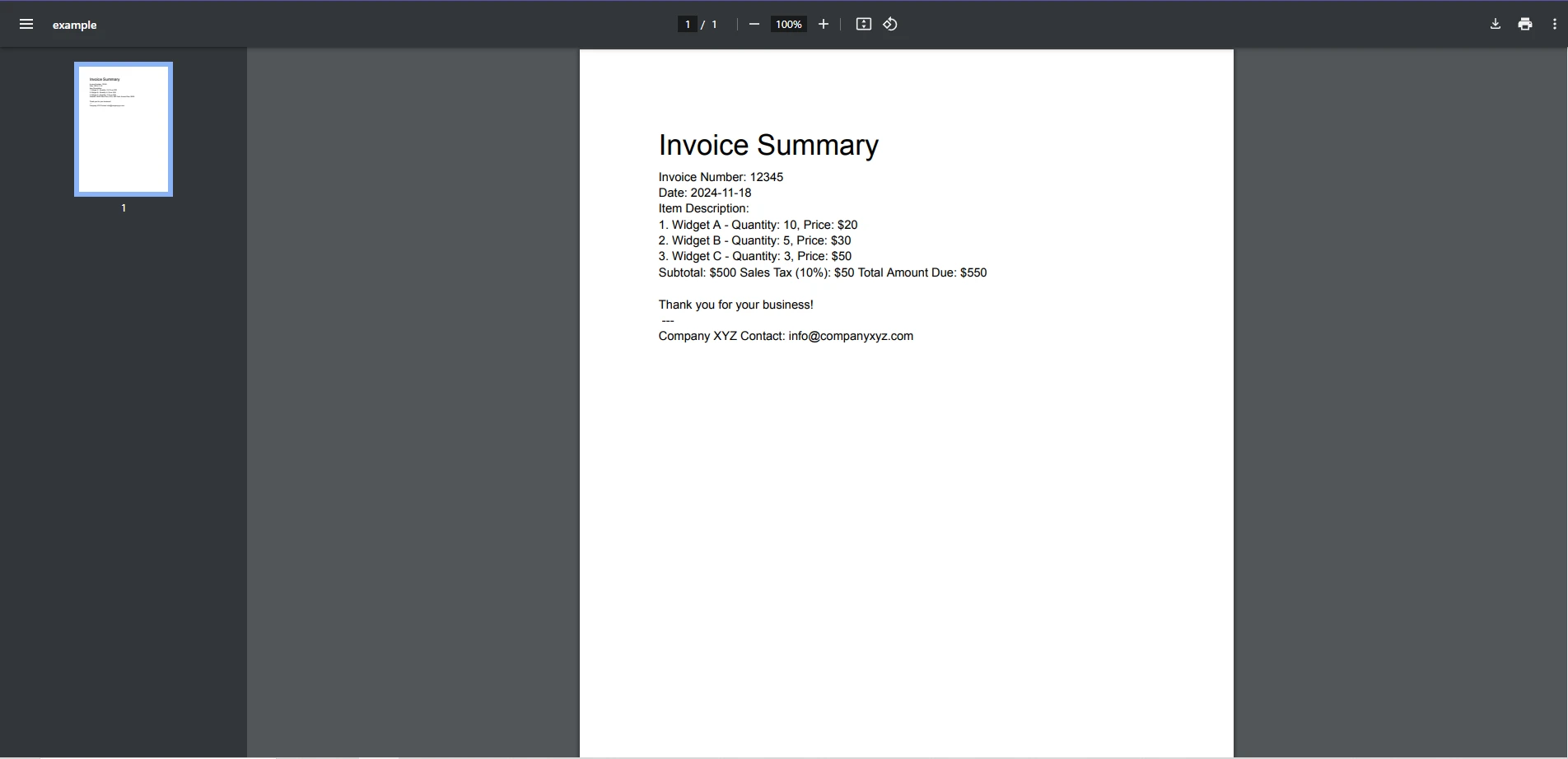
Salida de Consola
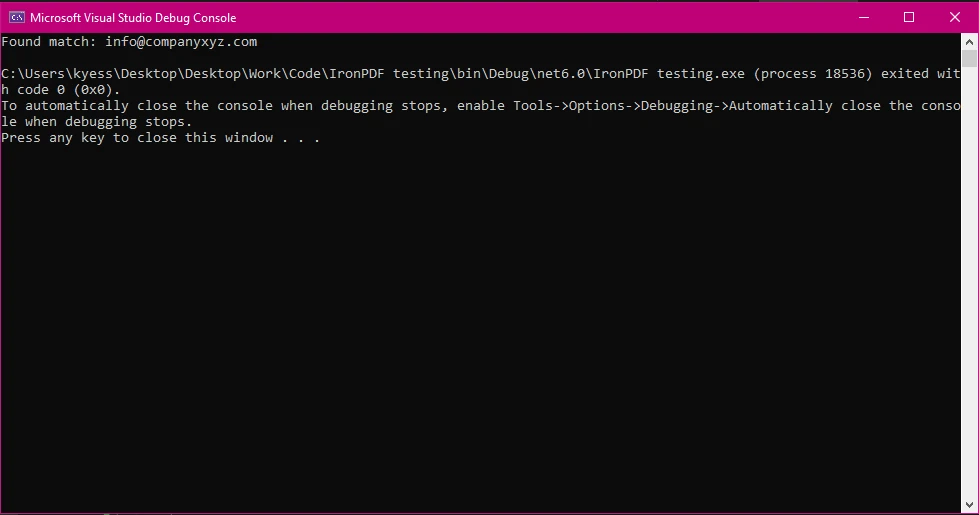
Este ejemplo utiliza un patrón de expresiones regulares para identificar e imprimir todas las direcciones de correo electrónico encontradas en el documento.
A veces, es posible que solo necesites buscar dentro de una página específica de un PDF. IronPDF te permite dirigirte a páginas individuales utilizando la propiedad PdfDocument.Pages:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
var pageText = pdf.Pages[0].Text.ToString(); // Extract text from the first page
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
var pageText = pdf.Pages[0].Text.ToString(); // Extract text from the first page
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
Dim pageText = pdf.Pages(0).Text.ToString() ' Extract text from the first page
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End ClassPDF de entrada
Salida de Consola
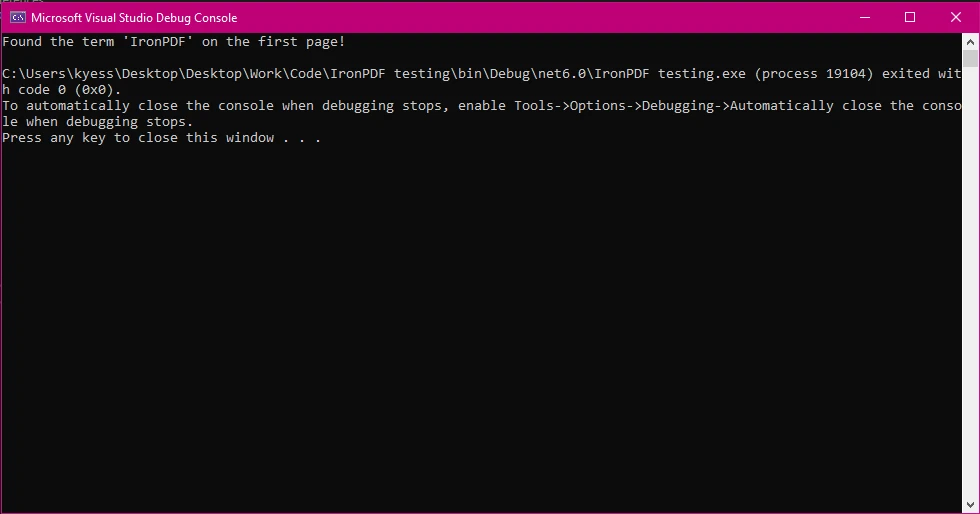
Este enfoque es útil para optimizar el rendimiento al trabajar con archivos PDF grandes.
Los profesionales legales pueden usar IronPDF para automatizar la búsqueda de términos clave o cláusulas dentro de contratos extensos. Por ejemplo, localice rápidamente "Cláusula de Terminación" o "Confidencialidad" en documentos.
En los flujos de trabajo de finanzas o contabilidad, IronPDF puede ayudar a localizar números de facturas, fechas o montos totales en archivos PDF masivos, agilizando las operaciones y reduciendo el esfuerzo manual.
IronPDF se puede integrar en flujos de datos para extraer y analizar información de informes o registros almacenados en formato PDF. Esto es particularmente útil para las industrias que manejan grandes volúmenes de datos no estructurados.
IronPDFes más que solo una biblioteca para trabajar con PDFs; es un conjunto de herramientas completo que permite a los desarrolladores de .NET manejar operaciones complejas de PDF con facilidad. Desde extraer texto y encontrar términos específicos hasta realizar coincidencias de patrones avanzadas con expresiones regulares, IronPDF simplifica tareas que de otro modo podrían requerir un esfuerzo manual significativo o múltiples bibliotecas.
La capacidad de extraer y buscar texto en PDFs desbloquea casos de uso poderosos en diversas industrias. Los profesionales legales pueden automatizar la búsqueda de cláusulas críticas en contratos, los contadores pueden agilizar el procesamiento de facturas, y los desarrolladores de cualquier campo pueden crear flujos de trabajo de documentos eficientes. Al ofrecer una extracción de texto precisa, compatibilidad con .NET Core y Framework, y capacidades avanzadas, IronPDF garantiza que sus necesidades de PDF se satisfagan sin complicaciones.
No permitas que el procesamiento de PDF ralentice tu desarrollo. Comience a usar IronPDF hoy para simplificar la extracción de texto y aumentar la productividad. Aquí tienes cómo comenzar:
Comience a Construir: Implemente una funcionalidad PDF poderosa en sus aplicaciones .NET con un esfuerzo mínimo.
Dé el primer paso hacia la optimización de sus flujos de trabajo de documentos con IronPDF. Desbloquea todo su potencial, mejora tu proceso de desarrollo y entrega soluciones potentes impulsadas por PDF más rápido que nunca.
Install-Package IronPdf

No se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.
Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina