Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF(Formato de documento portátil)los archivos desempeñan un papel vital en innumerables industrias, permitiendo a las empresas compartir, almacenar y gestionar documentos de manera segura. Para los desarrolladores, trabajar con PDFs a menudo implica crear, leer, convertir y extraer contenido para satisfacer las necesidades de los clientes. Extraer texto de archivos PDF es esencial para tareas como el análisis de datos, la indexación de documentos, la migración de contenido o la habilitación de funciones de accesibilidad. Bibliotecas modernas comoIronPDFhacen que estas tareas sean más fáciles que nunca, ofreciendo potentes herramientas para manipular archivos PDF con un esfuerzo mínimo.
Esta guía se centra en uno de los requisitos más comunes: extraer texto de un PDF en C#. Le guiaremos a través de la configuración de un proyecto en Visual Studio, la instalación de IronPDF y su uso para realizar la extracción de texto con ejemplos de código concisos. En el camino, destacaremos las características robustas de IronPDF, incluidas su capacidad para crear, manipular y convertir archivos PDF usando .NET. Ya sea que estés creando aplicaciones con muchos documentos o simplemente necesites un manejo eficiente de PDF, este tutorial te pondrá en marcha.
IronPDF es un sólido conversor de PDF que puede realizar casi cualquier operación que pueda realizar un navegador. Crear, leer y manipular documentos PDF es sencillo con la biblioteca .NET para desarrolladores. IronPDF convierte documentos HTML a PDF utilizando el motor de Chrome. IronPDF es compatible con HTML, ASPX, Razor HTML y MVC View, entre otros componentes web. La aplicación Microsoft .NET es compatible con IronPDF(tanto aplicaciones web ASP.NET como aplicaciones Windows tradicionales). IronPDF también puede utilizarse para crear un documento PDF visualmente atractivo.
Podemos hacer un documento PDF a partir de HTML5, JavaScript, CSS e imágenes con IronPDF. Además, los archivos pueden tener cabeceras y pies de página. Gracias a IronPDF, podemos leer fácilmente un documento PDF. IronPDF también cuenta con un completo motor de conversión de PDF y un potente conversor de HTML a PDF que puede manejar documentos PDF.
Abra el software Visual Studio y vaya al menú Archivo. Seleccione "Nuevo proyecto" y, a continuación, "Aplicación de consola". En este artículo, vamos a utilizar una aplicación de consola para generar documentos PDF.
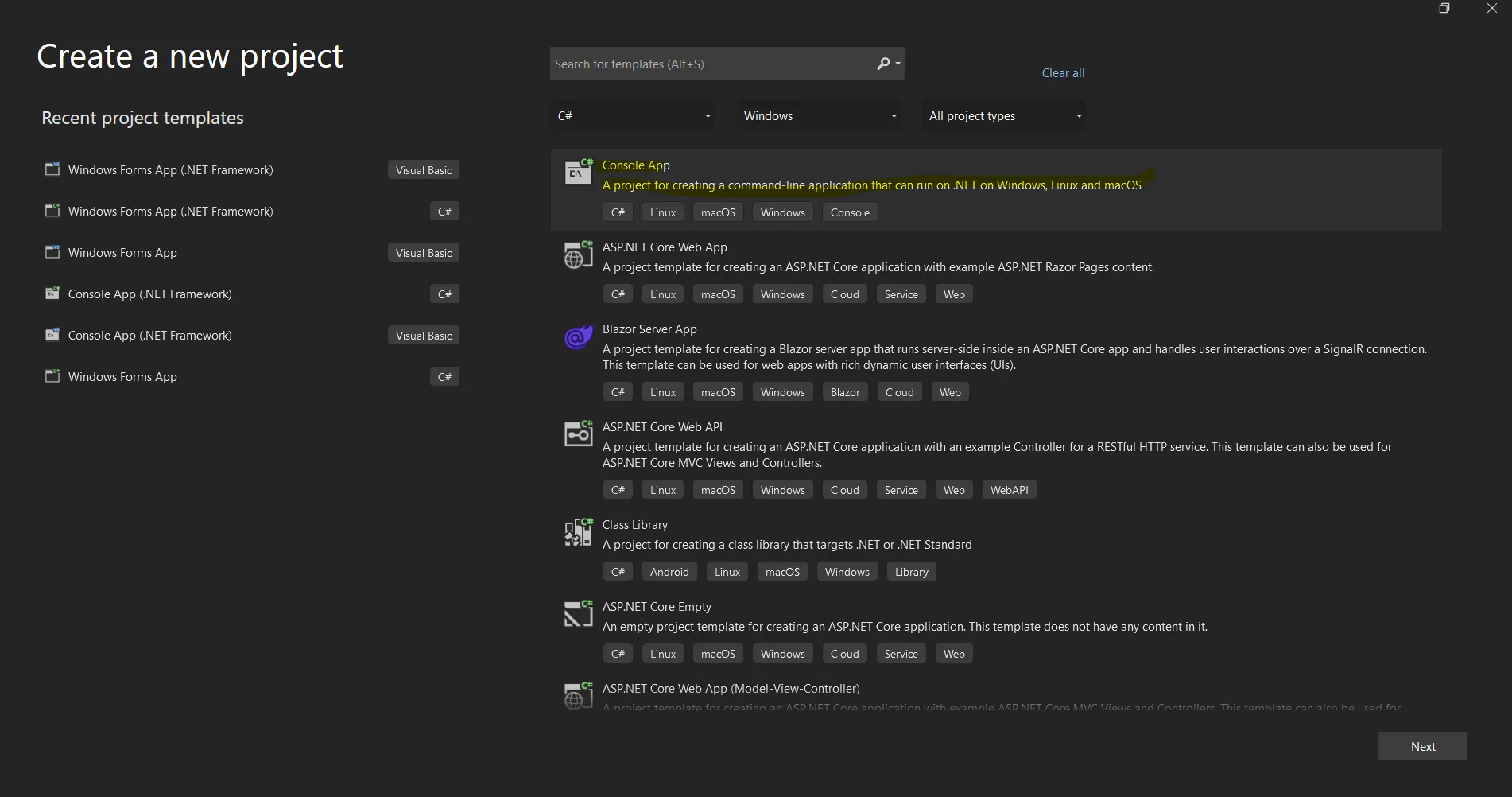
Crea un nuevo proyecto en Visual Studio.
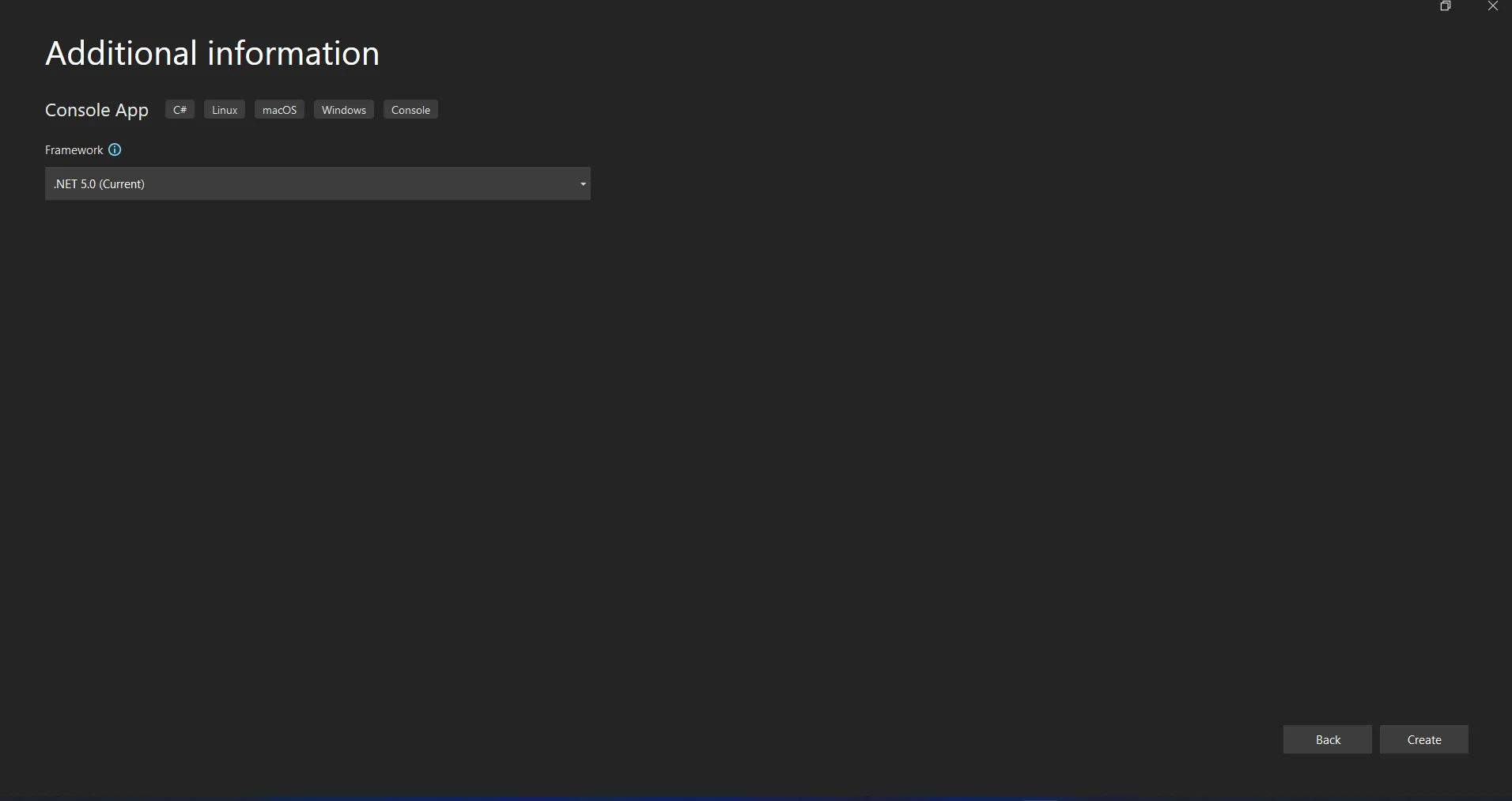
Introduzca el nombre del proyecto y seleccione la ruta del archivo en el cuadro de texto correspondiente. A continuación, haga clic en el botón Create y seleccione el .NET Framework necesario, como en la captura de pantalla siguiente.

Configurar nuevo proyecto en Visual Studio
El proyecto de Visual Studio generará ahora la estructura para la aplicación seleccionada, y si ha seleccionado la Consola, Windows y Aplicación Web, abrirá el archivo program.cs donde podrá introducir el código y construir/ejecutar la aplicación.
**Selección de .NET Core
A continuación, podemos añadir la biblioteca para probar el código.
La biblioteca IronPDF puede descargarse e instalarse de cuatro maneras.
Estos son:
El software Visual Studio proporciona la opción NuGet Package Manager para instalar el paquete directamente en la solución. La siguiente captura de pantalla muestra cómo abrir el Gestor de paquetes NuGet.
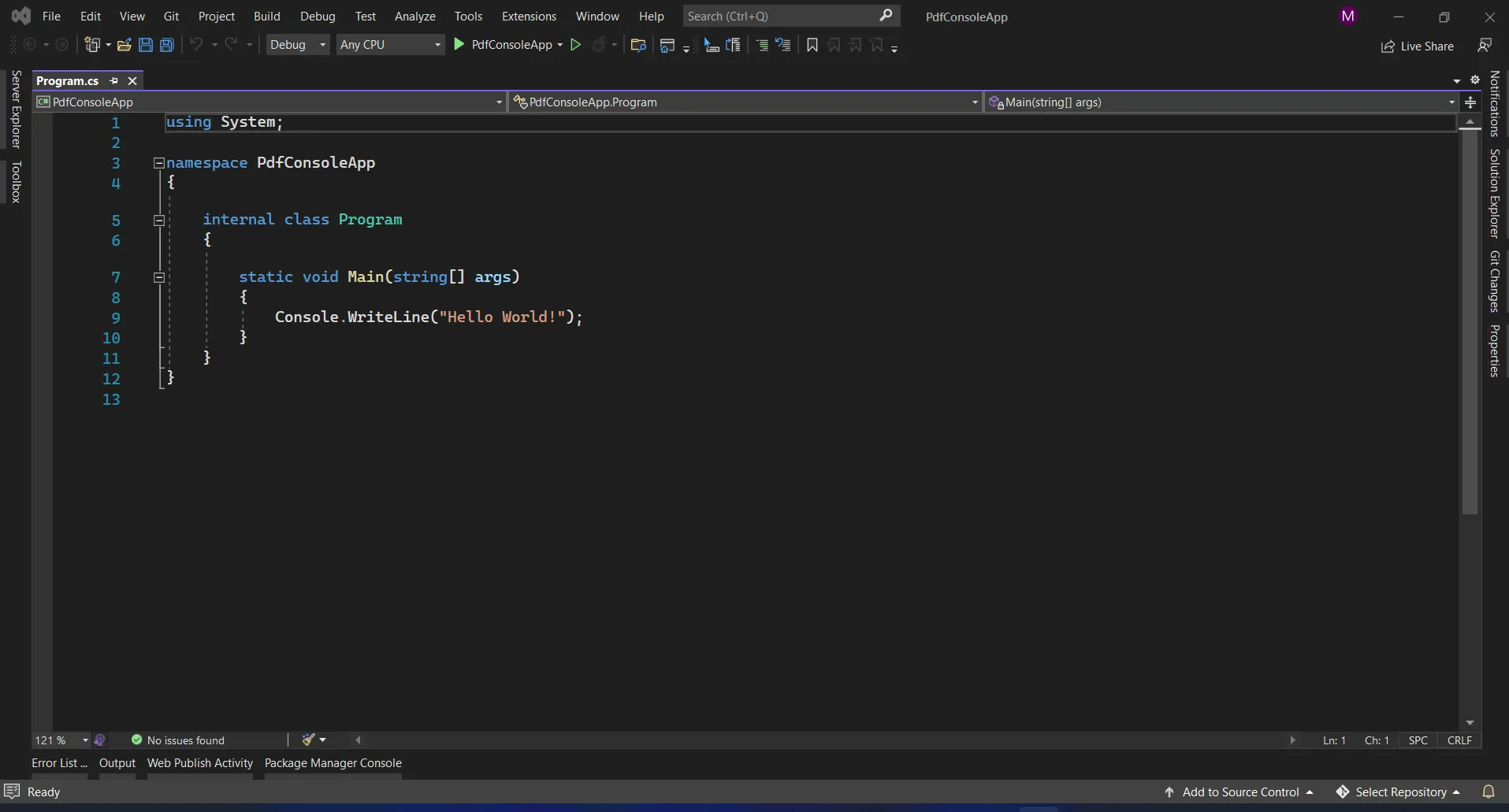
Archivo programa.cs de Visual Studio
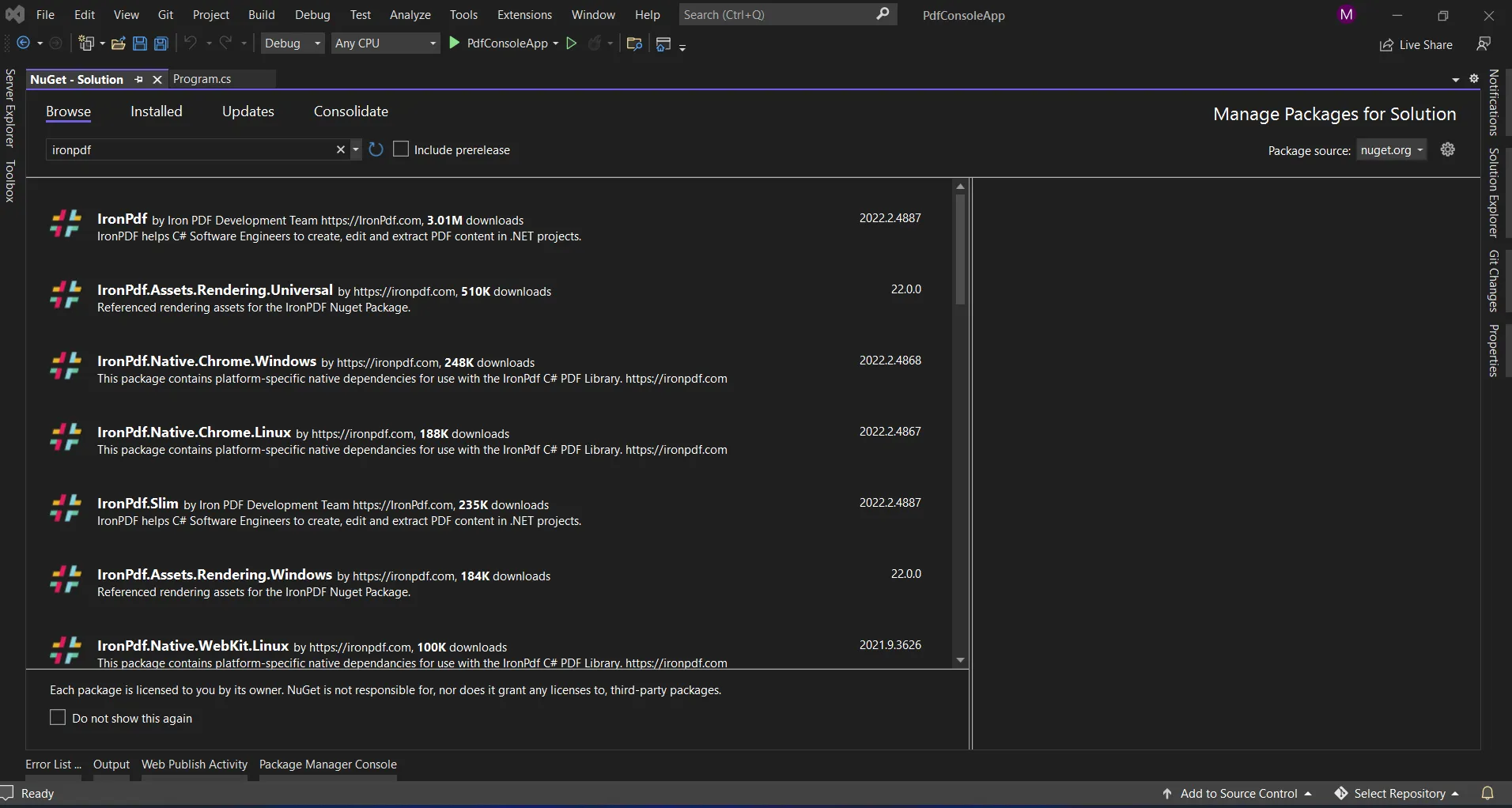
Proporciona el cuadro de búsqueda para mostrar la lista de paquetes del sitio web de NuGet. En el gestor de paquetes, tenemos que buscar la palabra clave "IronPdf", como en la siguiente captura de pantalla.

Gestor de paquetes NuGet
En la imagen anterior, podemos ver la lista de los elementos de búsqueda relacionados. Debemos seleccionar la opción necesaria para instalar el paquete en la solución.
En Visual Studio, vaya a Herramientas > Gestor de paquetes NuGet > Consola del gestor de paquetes
Introduzca la siguiente línea en la pestaña de la consola del gestor de paquetes:
Install-Package IronPdf
Ahora el paquete se descargará/instalará en el proyecto actual y estará listo para su uso.
Biblioteca IronPdf en el gestor de paquetes NuGet.
La tercera forma es descargar elPaquete NuGet IronPDF directamente desde su sitio web.
Visitesitio oficial de IronPDF para descargar el último paquete directamente de su sitio web. Una vez descargado, siga los pasos que se indican a continuación para añadir el paquete al proyecto.
El programa IronPDF nos permite realizar la extracción de texto del archivo PDF y convertir páginas PDF en objetos PDF. A continuación se muestra un ejemplo de cómo utilizar IronPDF para leer un PDF existente.
El primer método consiste en extraer texto de un PDF y el fragmento de código de ejemplo se muestra a continuación.
using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();Imports IronPdf
Private pdfDocument = PdfDocument.FromFile("result.pdf")
Private AllText As String = pdfDocument.ExtractAllText()EnDesdeArchivo se utiliza para cargar el documento PDF a partir de un archivo existente y transformarlo enDocumentoPDF como se muestra en el código anterior. Podemos leer el texto y las imágenes accesibles en las páginas PDF utilizando este objeto. El objeto tiene un método llamadoExtraerTodoTexto que extrae todo el texto de todo el documento PDF, a continuación, mantiene el texto extraído en la cadena podemos utilizar la cadena para procesar.
A continuación se muestra el ejemplo de código para el segundo método que podemos utilizar para extraer texto de un archivo PDF, página por página.
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}Using pdf As PdfDocument = PdfDocument.FromFile("result.pdf")
For index = 0 To pdf.PageCount - 1
Dim Text As String = pdf.ExtractTextFromPage(index)
Next index
End UsingEn el código anterior, vemos que primero cargará todo el documento PDF y lo convertirá en un objeto PDF. A continuación, obtenemos el recuento de páginas de todo el documento PDF mediante un método incorporado llamadoCuentaPáginasy obtendrá el número total de páginas disponibles en el documento PDF cargado. Utilizando el "bucle for" yExtraerTextoDePágina nos permite pasar el número de página como parámetro para extraer texto del documento cargado. A continuación, guardará el texto exacto en la variable de cadena. Asimismo, extraerá texto del PDF página por página con ayuda del bucle "for" o "for each".
IronPDF es una biblioteca PDF versátil y potente diseñada para facilitar el trabajo con PDFs en aplicaciones .NET. Sus características robustas permiten a los desarrolladores crear, manipular y extraer contenido de archivos PDF sin depender de dependencias de terceros como Adobe Reader. Una de las capacidades destacadas de IronPDF es su habilidad para extraer texto de documentos PDF. Esta función es invaluable para automatizar tareas como el análisis de datos, la indexación de documentos, la migración de contenido y la habilitación de funciones de accesibilidad. Al permitir que los desarrolladores recuperen y procesen texto de manera programática, IronPDF simplifica los flujos de trabajo y abre nuevas posibilidades para manejar contenido PDF.
Con una integración sencilla y soporte multiplataforma, IronPDF es una excelente opción para los desarrolladores que buscan gestionar documentos PDF de manera eficiente. Además, IronPDF ofrece unprueba gratuita, permitiéndole explorar su gama completa de características sin riesgo antes de comprometerse. Para obtener detalles sobre los precios y conocer más sobre las opciones de licencia, visite nuestro página de precios.
Kye Stuart fusiona la pasión por la codificación y la habilidad de escritura en Iron Software. Educado en Yoobee College en despliegue de software, ahora transforma conceptos técnicos complejos en contenido educativo claro. Kye valora el aprendizaje permanente y afronta nuevos desafíos tecnológicos.
Fuera del trabajo, disfruta de los juegos de PC, transmitir en Twitch y actividades al aire libre como la jardinería y pasear a su perro, Jaiya. El enfoque directo de Kye los convierte en una pieza clave para la misión de Iron Software de desmitificar la tecnología para desarrolladores a nivel mundial.
Clave de prueba de 30 días al instante.
Clave de prueba de 15 días al instante.
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
 No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuentaInstall-Package IronPdf

No se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.
Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina