Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Parallel.ForEaches un método en C# que te permite realizar iteraciones paralelas sobre una colección o fuente de datos. En lugar de procesar cada elemento de la colección de manera secuencial, un bucle paralelo permite la ejecución concurrente, lo que puede mejorar significativamente el rendimiento al reducir el tiempo total de ejecución. El procesamiento paralelo funciona dividiendo el trabajo entre múltiples procesadores centrales, permitiendo que las tareas se ejecuten simultáneamente. Esto es particularmente útil al procesar tareas que son independientes entre sí.
A diferencia de un bucle foreach normal, que procesa los elementos de forma secuencial, el enfoque paralelo puede manejar conjuntos de datos grandes mucho más rápido al utilizar múltiples hilos en paralelo.
IronPDFes una poderosa biblioteca para manejar PDF en .NET, capaz de convertir HTML a PDF, extracción de texto de PDF, fusión y división de documentosy mucho más. Al manejar grandes volúmenes de tareas PDF, el uso del procesamiento paralelo con Parallel.ForEach puede reducir significativamente el tiempo de ejecución. Ya sea que esté generando cientos de PDFs o extrayendo datos de múltiples archivos simultáneamente, aprovechar el paralelismo de datos con IronPDF garantiza que las tareas se completen más rápido y de manera más eficiente.
Esta guía está destinada a desarrolladores .NET que desean optimizar sus tareas de procesamiento de PDF utilizando IronPDF y Parallel.ForEach. Se recomienda tener conocimientos básicos de C# y estar familiarizado con la biblioteca IronPDF. Al final de esta guía, podrá implementar el procesamiento en paralelo para manejar múltiples tareas de PDF de manera simultánea, mejorando tanto el rendimiento como la escalabilidad.
Para utilizarIronPDFen tu proyecto, necesitas instalar la biblioteca a través de NuGet.
Para instalar IronPDF, siga estos pasos:
Abra su proyecto en Visual Studio.
Ve a Herramientas → Administrador de paquetes NuGet → Administrar paquetes NuGet para la solución.
Alternativamente, puedes instalarlo a través de la consola del Administrador de Paquetes NuGet:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfUna vez que IronPDF está instalado, estás listo para comenzar a usarlo para tareas de generación y manipulación de PDF.
Parallel.ForEach es parte del espacio de nombres System.Threading.Tasks y proporciona una forma sencilla y efectiva de ejecutar iteraciones simultáneamente. La sintaxis de Parallel.ForEach es la siguiente:
Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, Sub(item)
' Code to process each item
End Sub)Cada elemento de la colección se procesa en paralelo y el sistema decide cómo distribuir la carga de trabajo entre los hilos disponibles. También puedes especificar opciones para controlar el grado de paralelismo, como el número máximo de subprocesos utilizados.
En comparación, un bucle foreach tradicional procesa cada elemento uno tras otro, mientras que el bucle paralelo puede procesar múltiples elementos simultáneamente, mejorando el rendimiento al manejar colecciones grandes.
Primero, asegúrese de que IronPDF esté instalado como se describe en la sección de Introducción. Después de eso, puedes comenzar a escribir tu lógica de procesamiento paralelo de PDF.
string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});Dim htmlPages() As String = { "page1.html", "page2.html", "page3.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
End Sub)Este código demuestra cómo convertir múltiples páginas HTML a PDF en paralelo.
Al manejar tareas paralelas, el manejo de errores es crucial. Utilice bloques try-catch dentro del bucle Parallel.ForEach para manejar cualquier excepción.
Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, Sub(pdfFile)
Try
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractAllText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
Catch ex As Exception
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}")
End Try
End Sub)Otro caso de uso para el procesamiento en paralelo es la extracción de texto de un lote de PDFs. Cuando se trata de múltiples archivos PDF, realizar la extracción de texto de manera concurrente puede ahorrar mucho tiempo. El siguiente ejemplo demuestra cómo se puede hacer esto.
using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}Imports IronPdf
Imports System.Linq
Imports System.Threading.Tasks
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfFiles() As String = { "doc1.pdf", "doc2.pdf", "doc3.pdf" }
Parallel.ForEach(pdfFiles, Sub(pdfFile)
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
End Sub)
End Sub
End Class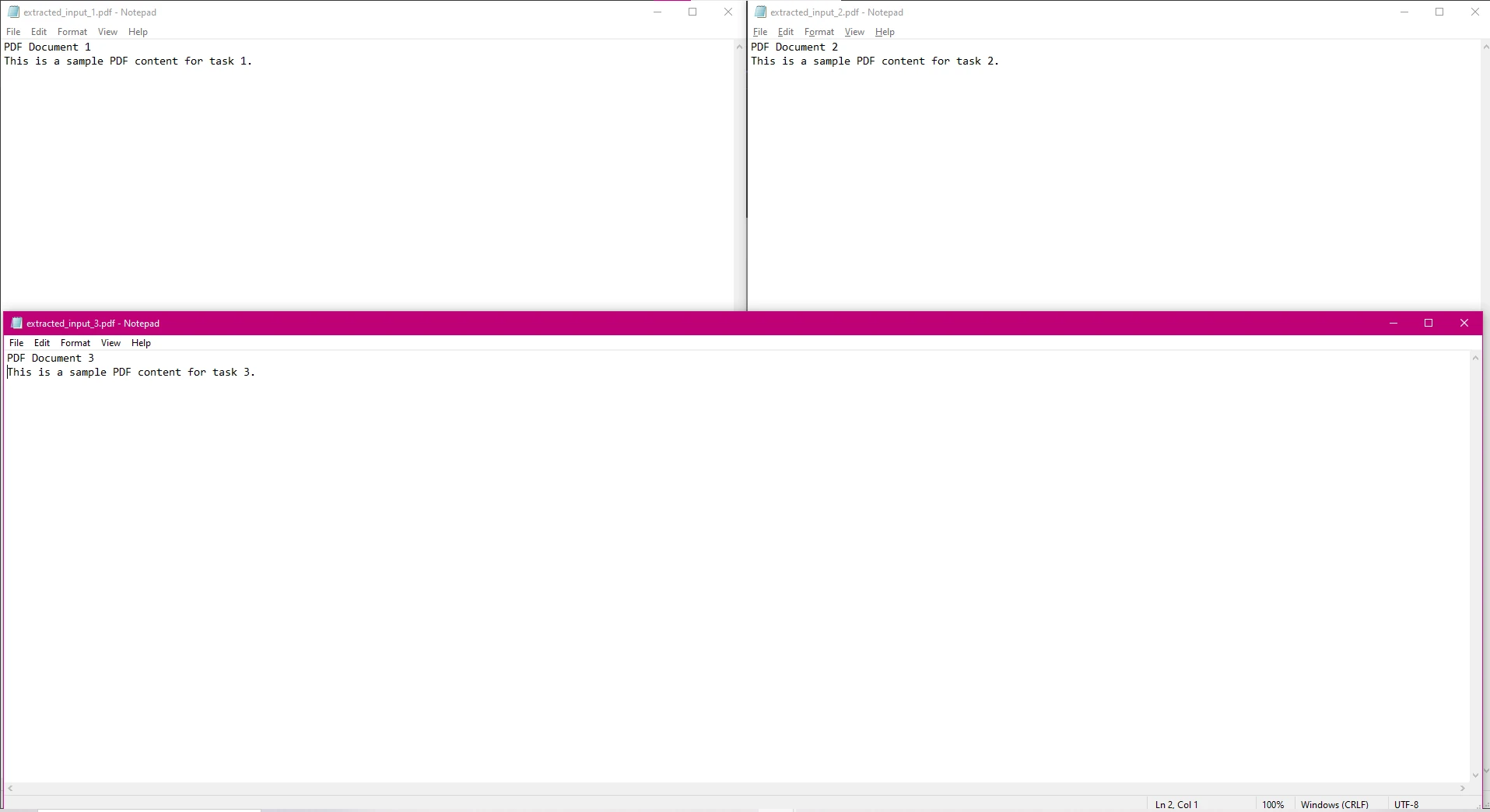
En este código, cada archivo PDF se procesa en paralelo para extraer texto, y el texto extraído se guarda en archivos de texto separados.
En este ejemplo, generaremos múltiples PDFs a partir de una lista de archivos HTML en paralelo, lo cual podría ser un escenario típico cuando necesitas convertir varias páginas HTML dinámicas en documentos PDF.
using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});Imports IronPdf
Private htmlFiles() As String = { "example.html", "example_1.html", "example_2.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
Try
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlFileAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
Console.WriteLine($"PDF created for {htmlFile}")
Catch ex As Exception
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}")
End Try
End Sub)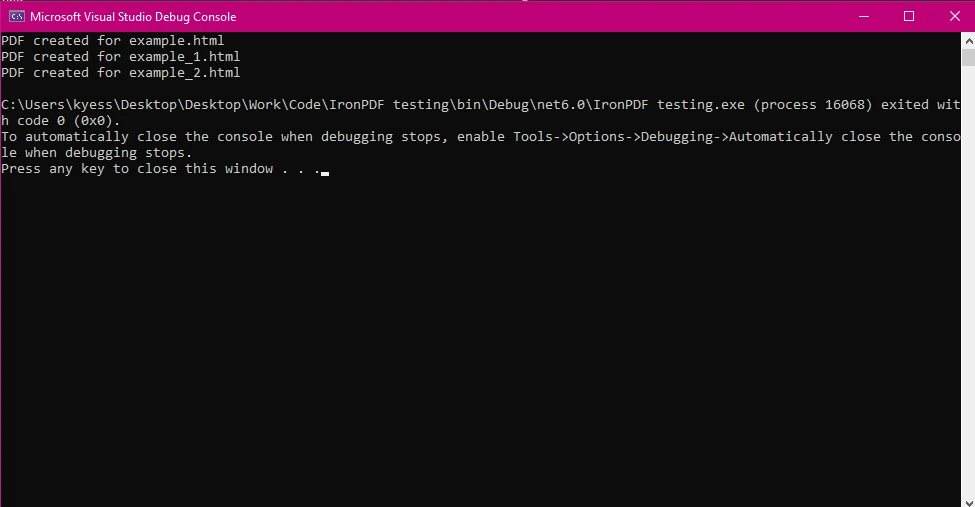
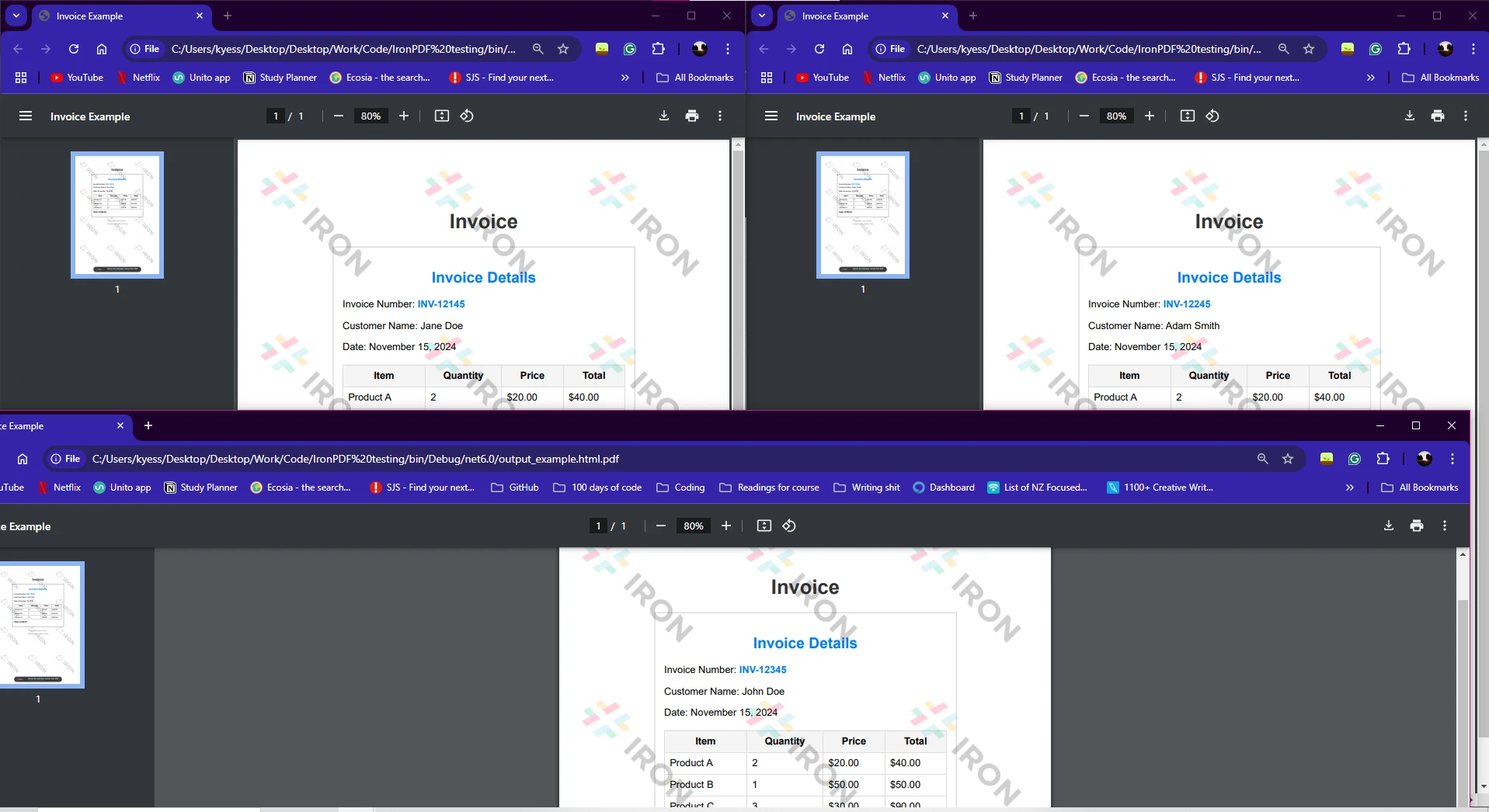
Archivos HTML: El arreglo htmlFiles contiene rutas a múltiples archivos HTML que deseas convertir en PDFs.
Parallel.ForEach(archivosHtml, archivoHtml => {...}) procesa cada archivo HTML simultáneamente, lo que acelera la operación al manejar múltiples archivos.
Guardar el PDF: Después de generar el PDF, se guarda utilizando el método pdf.SaveAs, añadiendo el nombre del archivo de salida al nombre del archivo HTML original.
IronPDF es seguro para la ejecución de múltiples hilos en la mayoría de las operaciones. Sin embargo, algunas operaciones como escribir en el mismo archivo en paralelo pueden causar problemas. Siempre asegúrese de que cada tarea paralela opere en un archivo de salida o recurso separado.
Para optimizar el rendimiento, considere controlar el grado de paralelismo. Para conjuntos de datos grandes, es posible que desee limitar el número de hilos concurrentes para prevenir la sobrecarga del sistema.
var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};Dim options = New ExecutionDataflowBlockOptions With {.MaxDegreeOfParallelism = 4}Al procesar una gran cantidad de PDFs, tenga en cuenta el uso de memoria. Intente liberar recursos como objetos PdfDocument tan pronto como ya no los necesite.
Un método de extensión es un tipo especial de método estático que te permite agregar nueva funcionalidad a un tipo existente sin modificar su código fuente. Esto puede ser útil al trabajar con bibliotecas como IronPDF, donde podrías querer agregar métodos de procesamiento personalizados o extender su funcionalidad para facilitar el trabajo con archivos PDF, especialmente en escenarios de procesamiento en paralelo.
Al utilizar métodos de extensión, puedes crear código conciso y reutilizable que simplifica la lógica en bucles paralelos. Este enfoque no solo reduce la duplicación, sino que también te ayuda a mantener un código limpio, especialmente al manejar flujos de trabajo PDF complejos y el paralelismo de datos.
Usar bucles paralelos como Parallel.ForEach con IronPDFproporciona mejoras significativas en el rendimiento al procesar grandes volúmenes de PDFs. Ya sea que estés convirtiendo HTML a PDFs, extrayendo texto o manipulando documentos, el paralelismo de datos permite una ejecución más rápida al ejecutar tareas concurrentemente. El enfoque paralelo garantiza que las operaciones se puedan ejecutar en múltiples procesadores de núcleo, lo que reduce el tiempo total de ejecución y mejora el rendimiento para las tareas de procesamiento por lotes.
Aunque el procesamiento en paralelo acelera las tareas, se debe tener cuidado con la seguridad de los hilos y la gestión de recursos. IronPDF es seguro para hilos en la mayoría de las operaciones, pero es importante manejar potenciales conflictos al acceder a recursos compartidos. Considere el manejo de errores y la gestión de memoria para garantizar la estabilidad, especialmente a medida que su aplicación escala.
Si estás listo para profundizar más en IronPDF y explorar funciones avanzadas, eldocumentación oficial, lo que le permite probar la biblioteca en sus propios proyectos antes de comprometerse a una compra.
Install-Package IronPdf

No se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.
Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina