Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Para este tutorial, vamos a ver cómoextraer textodesde PDF(Formato de documento portátil)documentos en C# utilizando dos bibliotecas PDF diferentes.
En la era web moderna de hoy, hay varias bibliotecas disponibles que son capaces de extraer texto e imágenes de archivos PDF para analizarlos y leerlos. Hoy vamos a utilizar dos potentes bibliotecas PDF,IronPDF yQuestPDF, para extraer texto de un archivo PDF. Al comparar cómo estas dos bibliotecas manejan una tarea simple de extracción de texto, podemos determinar cuál puede estar mejor adaptada para manejar tareas avanzadas de PDF. Antes de entrar en la sección de comparación, tomémonos un momento para ver una breve introducción de cada biblioteca.
QuestPDF es una biblioteca de generación de PDF de última generación y de código abierto, diseñada específicamente para desarrolladores .NET. Utiliza una API declarativa moderna que permite a los usuarios definir y generar diseños de PDF complejos con gran flexibilidad y precisión. Si bien el enfoque principal de QuestPDF es la generación de documentos en lugar de la extracción de texto, ofrece un enfoque limpio e intuitivo para construir documentos desde cero y manipular diferentes elementos dentro del documento. Esto lo hace especialmente adecuado para aplicaciones que requieren contenido PDF personalizado y dinámico.
IronPDF es una versátil biblioteca de procesamiento de PDF diseñada para facilitar y hacer más eficiente el trabajo con archivos PDF en C#. A diferencia de QuestPDF, IronPDF está específicamente diseñado tanto para la generación como para la manipulación de PDF. Funciones que ofrece incluyen PDFcodificación, soporte extensivo para la edición yanotaciónPDFs existentes, convertir varios documentos a formato PDF, añadir enencabezados y pies de página (que se puede usar para mostrar números de página), edición de metadatos de documentos, compatibilidad con multithreading y asíncrona, y herramientas avanzadas de conversión de PDF.
Además de su rica variedad de características, IronPDF ofrece soporte completo multiplataforma, brindando compatibilidad con .NET 5/6/7, .NET Core y .NET Framework. También es totalmente compatible con Windows, macOS, Linux y plataformas en la nube como Azure y AWS, lo que lo convierte en una excelente opción para aplicaciones .NET multiplataforma.
Para el ejemplo de hoy, extraeremos texto de nuestro documento PDF de factura de ejemplo utilizando ambas bibliotecas.
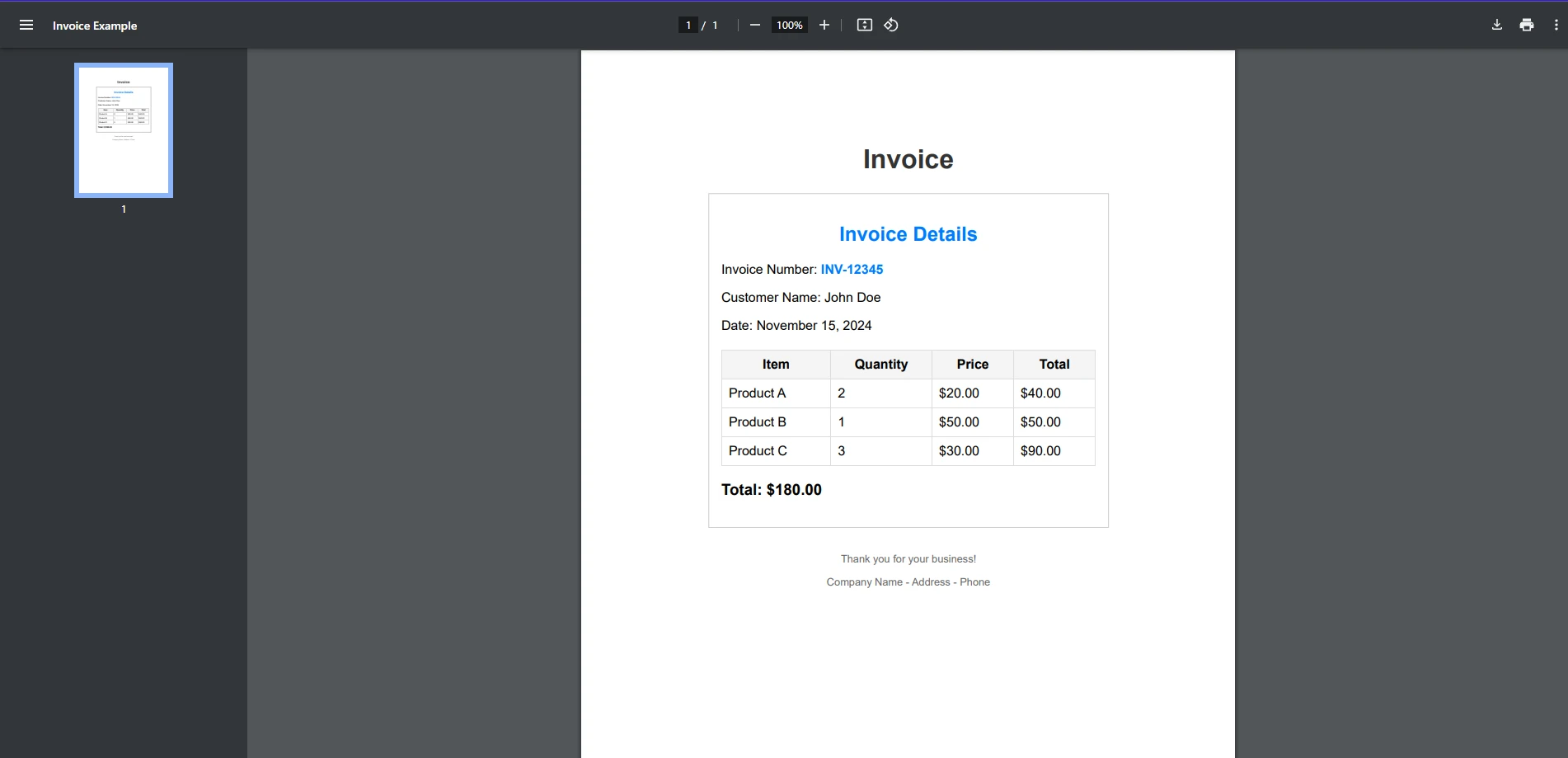
Primero, veremos si QuestPDF puede manejar esta tarea.
Desafortunadamente, aunque QuestPDF sobresale en la creación de PDF y en el rendimiento de ciertas tareas de PDF, la extracción de texto no está entre las funciones que actualmente ofrece. Aunque QuestPDF no está diseñado intrínsecamente para extraer texto de archivos PDF existentes, sí proporciona herramientas básicas para trabajar con PDFs, las cuales pueden extenderse para la extracción de texto con lógica adicional o integraciones de terceros. Por ejemplo, QuestPDF podría usarse para generar documentos PDF con contenido estructurado, y podrías implementar una solución personalizada para extraer contenido basado en la estructura del documento utilizando una biblioteca de terceros.
Extracción de textoes solo una de las tareas en las que IronPDF destaca al trabajar con archivos PDF. En solo unas pocas líneas de código, somos capaces de extraer texto de un documento PDF completo. Esto se puede ver en el siguiente fragmento de código:
using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}Imports IronPdf
Public Class Program
Public Shared Sub main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Console.WriteLine(text)
End Sub
End Class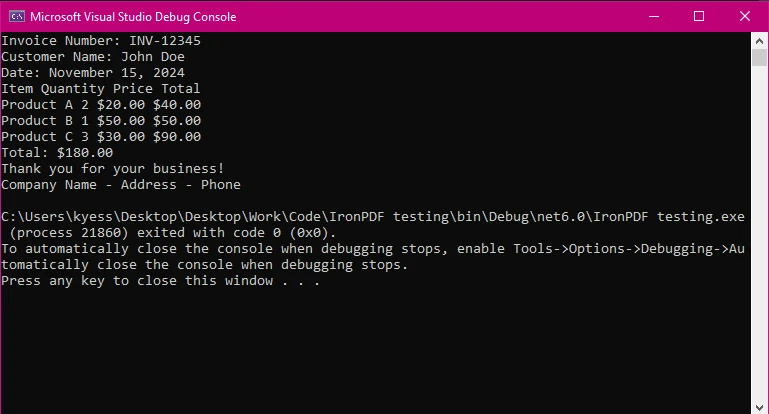
IronPDF ofrece una API simple para extraer texto, lo que lo hace ideal para desarrolladores enfocados en la eficiencia. En solo tres líneas, pudimos extraer el contenido de texto dentro de nuestro documento PDF y mostrarlo para que se lea. Desde aquí, podrías fácilmente guardar el texto extraído para su uso o manipulación posterior.
QuestPDF, por otro lado, no podría manejar una tarea como la extracción de texto, debido a un número más limitado de características en comparación con bibliotecas como IronPDF. Aunque puede manejar otras tareas como la generación de PDF y la manipulación básica, necesitaría implementar bibliotecas externas para extraer texto.
Cuando se trata deextracción de texto. QuestPDF es gratuito a través del uso de su licencia comunitaria para proyectos privados, pero también tiene la opción delicencias comerciales.
Ambas bibliotecas son precisas y fiables, pero la elección depende en última instancia de los requisitos de tu proyecto.
Para una comparación más detallada de estas bibliotecas, consulta el blog completo enIronPDF vs QuestPDF.
Install-Package IronPdf

No se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.
Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina