Pruebas en un entorno real
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
La biblioteca PDF de C#
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


En el dinámico panorama de la gestión de documentos digitales, la capacidad de extraer datos de archivos PDF sin esfuerzo es una tarea fundamental que sustenta multitud de aplicaciones. El proceso de extracción de texto es vital para fines como el análisis exhaustivo de datos, la indexación de contenidos, el uso comercial y la manipulación de textos. Entre el abanico de herramientas disponibles, iTextSharp, una biblioteca de C# de gran prestigio, emerge como una solución excepcional para la extracción de texto de archivos PDF.
En este completo artículo, nos adentraremos en las ricas capacidades de uso de iTextSharp, explorando cómo esta potente y versátil biblioteca analizadora permite a los desarrolladores extraer de forma eficaz contenido textual de documentos PDF utilizando el lenguaje de programación C#. Desentrañaremos los métodos esenciales, las técnicas de ejemplo y las mejores prácticas, equipando a los desarrolladores con los conocimientos necesarios para aprovechar iTextSharp de forma eficaz para la extracción de texto. También discutiremos y compararemos la mejor y más potente librería PDF IronPDF en este post.
Descargue la biblioteca C# para extraer el texto de un PDF.
Cargue un PDF existente instanciando el objeto PdfReader.
Extrae texto del objeto PdfDocument utilizando el método GetTextFromPage.
Instanciar el bucle foreach para iterar a través de las líneas.
WriteLine.Visión general de IronPDF, una biblioteca prominente y rica en funciones en el ámbito del desarrollo .NET, revoluciona la generación y manipulación de PDFs. IronPDF, que ofrece a los desarrolladores un completo conjunto de herramientas, facilita una integración perfecta en las aplicaciones C#, lo que permite crear, modificar y renderizar documentos PDF sin esfuerzo. Con su intuitiva API y su sólida funcionalidad, esta versátil biblioteca abre un mundo de posibilidades para generar PDF de alta calidad a partir de HTML, imágenes y contenidos. En este artículo, exploraremos las capacidades de IronPDF, profundizando en sus características clave y demostrando cómo se puede utilizar para manejar eficientemente tareas relacionadas con PDF dentro de C#.
iTextSharp, una conocida y potente biblioteca en el ámbito de la manipulación de PDF mediante C#, ha revolucionado la forma en que los desarrolladores manejan los documentos PDF. Se erige como una herramienta versátil y robusta que facilita la creación, modificación y extracción de contenido de archivos PDF. iTextSharp permite a los desarrolladores generar PDF sofisticados, extraer imágenes, manipular documentos existentes y extraer datos, lo que lo convierte en una solución de referencia para una amplia gama de aplicaciones. En este artículo, profundizaremos en las capacidades y características de iTextSharp, explorando cómo puede utilizarse eficazmente para gestionar y manipular archivos PDF dentro del entorno de programación C#.
La instalación de IronPDF es un proceso sencillo, aquí están los pasos para instalar e integrar IronPDF en su proyecto C#.
Abra Visual Studio y cree un nuevo proyecto o abra un proyecto existente.
Vaya a Herramientas y seleccione Gestor de paquetes NuGet en el menú desplegable.
En el nuevo menú lateral, seleccione NuGet Package Manager for Solution.
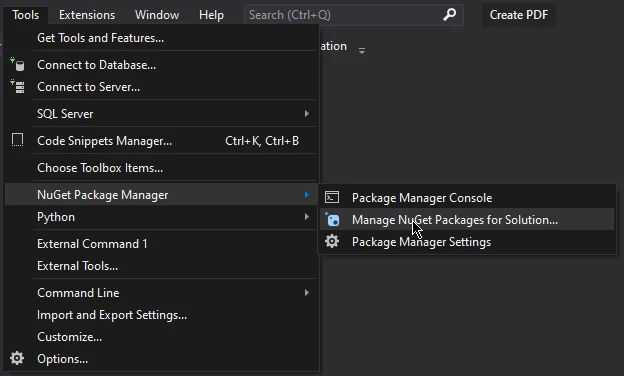
En la ventana "Gestor de paquetes NuGet", seleccione la pestaña "Examinar".
En la barra de búsqueda, escriba "IronPDF" y pulse Intro.
Aparecerá la lista de instancias de IronPDF, seleccione la última versión y pulse Instalar.
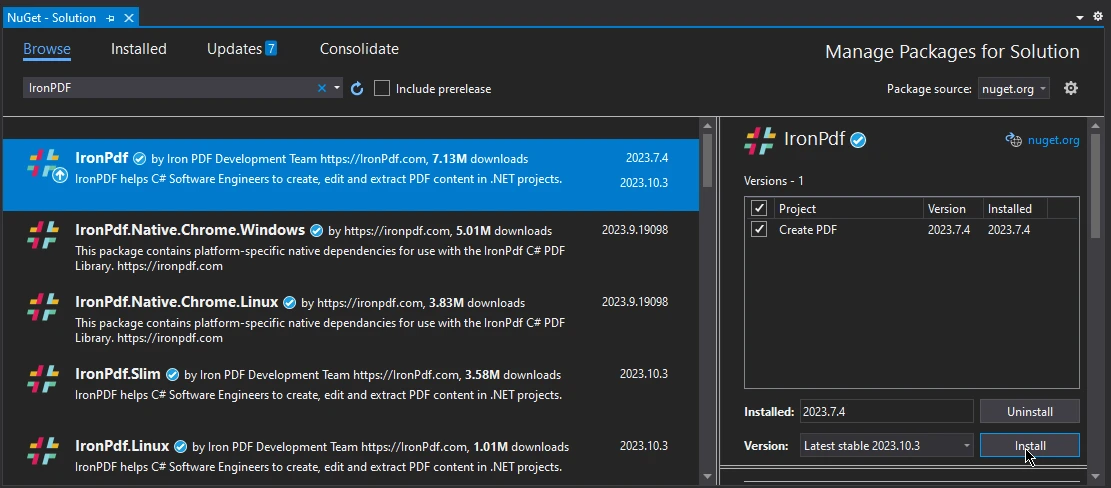
IronPDF está instalado y listo para ser utilizado en su proyecto C#.
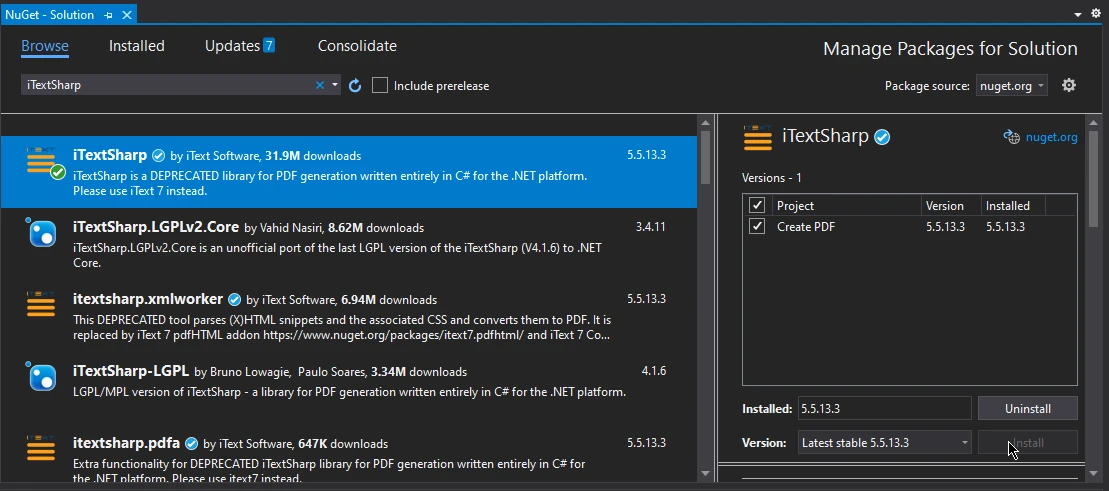
Instalar la biblioteca PDF iTextSharp es lo mismo que instalar IronPDF. Repita todos los pasos explicados anteriormente, sólo tiene que buscar "iTextSharp" en lugar de IronPDF en las ventanas de exploración, seleccionar de la lista de paquetes y hacer clic en instalar para integrar la biblioteca PDF iTextSharp en su proyecto.
IronPDF ofrece la función de extraer texto de archivos PDF para extraer automáticamente el texto basado en páginas específicas o extraer texto de todos los PDF. En el siguiente ejemplo de código, veremos cómo extraer texto de una página específica de un documento PDF de muestra.
using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);Imports IronPdf
Imports System
Private PdfDocument As using
Private Text As String = PDF.ExtractTextFromPage(1)
Console.Write(Text)El código anterior utiliza la biblioteca IronPDF en C# para extraer texto de un archivo PDF y mostrarlo en la consola. En primer lugar, se importan los espacios de nombres necesarios, incluidos IronPDF y System. El código luego carga un documento PDF titulado "Watermarked.pdf" en un objeto PdfDocument usando el método FromFile. Posteriormente, extrae texto de la segunda página del PDF usando ExtractTextFromPage y lo almacena en una variable de cadena llamada Text. Finalmente, el texto extraído se muestra en la consola utilizando Console.Write.

También puede extraer texto de archivos PDF utilizando iTextSharp, aquí hay un ejemplo de la biblioteca iTextSharp en juego.
using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Text
Imports iTextSharp.text.pdf
Imports iTextSharp.text.pdf.parser
Namespace PDFApp2
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim filePath As String = "C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf"
Dim outPath As String = "C:\Users\buttw\OneDrive\Desktop\name.txt"
Dim pagesToScan As Integer = 2
Dim strText As String = String.Empty
Try
Dim reader As New PdfReader(filePath)
For page As Integer = 1 To pagesToScan
Dim its As ITextExtractionStrategy = New iTextSharp.text.pdf.parser.LocationTextExtractionStrategy()
strText = PdfTextExtractor.GetTextFromPage(reader, page, its)
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)))
Dim lines() As String = strText.Split(ControlChars.Lf)
For Each line As String In lines
Using file As New System.IO.StreamWriter(outPath, True)
file.WriteLine(line)
End Using
Next line
Next page
reader.Close()
Catch ex As Exception
Console.Write(ex)
End Try
End Sub
End Class
End NamespaceEl código proporcionado es un programa en C# que utiliza la biblioteca iTextSharp para extraer texto de páginas específicas de un documento PDF y guardarlo en un archivo de texto. En primer lugar, se importan los espacios de nombres necesarios, incluyendo System.Text, iTextSharp.text.pdf e iTextSharp.text.pdf.parser. El programa especifica el nombre del archivo, la ruta del archivo PDF de entrada, la ruta del archivo de texto de salida y el número de páginas a escanear. Luego utiliza PdfReader de iTextSharp para leer el archivo PDF. Para cada página especificada, usa la nueva LocationTextExtractionStrategy de iTextSharp para extraer el texto, convirtiendo la codificación a UTF-8. El texto extraído se divide en líneas, y el nuevo texto de StringBuilder del código PDF funciona en la dirección correcta. Cualquier excepción encontrada durante el proceso es capturada y mostrada en la consola. El programa concluye cerrando el PdfReader.
Extraer texto de PDF en C# usando iTextSharp VS IronPDF Figura 5 - Extraer texto usando iTextSharp
iTextSharp, una potente y versátil biblioteca de C#, revoluciona la manipulación de PDF, permitiendo la creación, modificación y extracción de contenidos sin interrupciones. Sus sólidas funciones lo convierten en una solución imprescindible para los desarrolladores, ya que les permite generar PDF sofisticados y gestionar eficazmente el contenido textual de los archivos PDF. Además, IronPDF, otra biblioteca destacada en el ámbito .NET, ofrece un completo conjunto de herramientas para la generación de PDF y la manipulación de imágenes, mejorando la capacidad de los desarrolladores para crear, modificar y renderizar sin esfuerzo PDF de alta calidad a partir de diversas fuentes. Al comparar estas dos bibliotecas PDF, IronPDF lleva la delantera debido a su API bien documentada y fácil de usar, que también realiza toda la extracción de texto en solo unas pocas líneas de código, mientras que al usar iTextSharp tienes que escribir un código extenso y complejo y necesitas un conocimiento profundo de la biblioteca y C#.
Para saber más sobre las características de IronPDF y sus funciones, visita la página web oficial. El tutorial completo para extraer texto usando IronPDF se puede encontrar en este Tutorial de Extracción de Texto de IronPDF. Para un tutorial completo sobre IronPDF e iTextSharp, por favor visita la Comparación entre IronPDF e iTextSharp.
Install-Package IronPdf

No se necesita tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba se ha enviado
El formulario de prueba se ha enviado
exitosamente.
Si no es así, por favor contacte
support@ironsoftware.com
No se necesita tarjeta de crédito
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto





![]() No se necesita tarjeta de crédito ni crear una cuenta
No se necesita tarjeta de crédito ni crear una cuenta
Su clave de prueba debería estar en el correo electrónico.
Si no es así, por favor contacte con
support@ironsoftware.com
Empezar GRATIS
No se necesita tarjeta de crédito
Pruebe en producción sin marcas de agua.
Funciona donde lo necesite.
Obtén 30 días de producto totalmente funcional.
Ténlo en funcionamiento en minutos.
Acceso completo a nuestro equipo de asistencia técnica durante la prueba del producto
Licencias desde $749. ¿Tiene alguna pregunta? Póngase en contacto.
Reserve una demostración personal de 30 minutos.
Sin contrato, sin detalles de tarjeta, sin compromisos.


10 productos API de .NET para tus documentos de oficina