Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


In diesem Artikel wird gezeigt, wie IronPDF for Python, eine der leistungsfähigsten PDF-Bibliotheken, verwendet wird, um jeden in einem PDF-Dokument vorhandenen Text zu extrahieren.
ExtractAllText-Methode, um Text aus der geöffneten Datei zu lesenInstallieren Sie die neueste Version von Python von der Python-Downloadseite
Öffnen Sie alle IDE-Tools für Python
.NET Core-Laufzeitumgebung installieren
Installieren Sie die IronPDF für Python Bibliothek oder laden Sie sie von der PyPI-Download-Seite herunter
Die IronPDF-Bibliothek lässt sich problemlos in Python integrieren, da diese Sprache im Vergleich zu anderen Sprachen sehr viel dynamischer ist und es Entwicklern ermöglicht, schnell und einfach grafische Benutzeroberflächen zu erstellen. Es verfügt über eine Fülle von vorinstallierten Werkzeugen, darunter PyQT, wxWidgets, kivy und zahlreiche zusätzliche Pakete und Bibliotheken, mit denen sich schnell und sicher eine vollständige grafische Benutzeroberfläche erstellen lässt.
IronPDF for Python ist eine äußerst effiziente Bibliothek, die besonders für die Webentwicklung nützlich ist. Die Verfügbarkeit so vieler Python-Paradigmen für die Webentwicklung, wie Django, Flask und Pyramid, ist teilweise dafür verantwortlich. Diese Frameworks wurden bereits von zahlreichen Websites und Online-Diensten verwendet, darunter Reddit, Mozilla und Spotify.
Fügen Sie die folgenden Import-Anweisungen am Anfang der Quelldateien ein, in denen IronPDF verwendet werden soll, um IronPDF zu importieren:
from ironpdf import *IronPDF for Python ist zwar kostenlos, versieht aber PDF-Dateien mit einem Wasserzeichen, das mit einem gekachelten Hintergrund versehen ist. Sie müssen der Bibliothek einen legitimen Lizenzschlüssel geben, um IronPDF für die Erstellung wasserzeichenfreier PDFs zu verwenden. Wie man die Bibliothek mit einem Lizenzschlüssel einrichtet, zeigt der folgende Codeschnipsel:
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"Vergewissern Sie sich, dass der Lizenzschlüssel konfiguriert ist, bevor Sie PDF-Dateien erstellen oder Änderungen an deren Inhalt vornehmen. Die LicenseKey-Methode sollte vor allen anderen Codezeilen aufgerufen werden. Um einen kostenlosen Testlizenzschlüssel zu erhalten, besuchen Sie die Lizenzierungsseite.
Eine Textdatei namens "Default" kann die von Custom.log erzeugten Protokollmeldungen im Verzeichnis des Python-Skripts speichern. Der folgende Codeausschnitt kann verwendet werden, um die Eigenschaft LogFilePath festzulegen und den Namen und den Speicherort der Protokolldatei anzupassen:
# Set a log path
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.AllDie IronPDF for Python-Bibliothek kann PDF-Seiten in PDF-Objekte umwandeln und ermöglicht die Textextraktion aus PDF-Dateien, auch aus gescannten PDF-Dateien. Hier ein Beispiel, das zeigt, wie man mit IronPDF ein vorhandenes PDF liest.
Bei der ersten Methode wird der gesamte in einer PDF-Datei vorhandene Text extrahiert; nachstehend finden Sie ein Beispiel für den Code.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)Wie im obigen Code veranschaulicht, ist die FromFile-Methode ein PDF-Reader-Objekt, das die vorhandene PDF-Datei lädt und in PDF-Dokumentobjekte umwandelt. Dieses Objekt kann verwendet werden, um den Text und die Bilder zu lesen, die auf den PDF-Seiten verfügbar sind. Das Objekt bietet eine Methode namens ExtractAllText, die jedes Stück Text aus der gesamten PDF-Datei extrahiert und den Text in einem String speichert, der verarbeitet werden kann. Und dann verwenden Sie die print-Funktion, um den Text anzuzeigen.
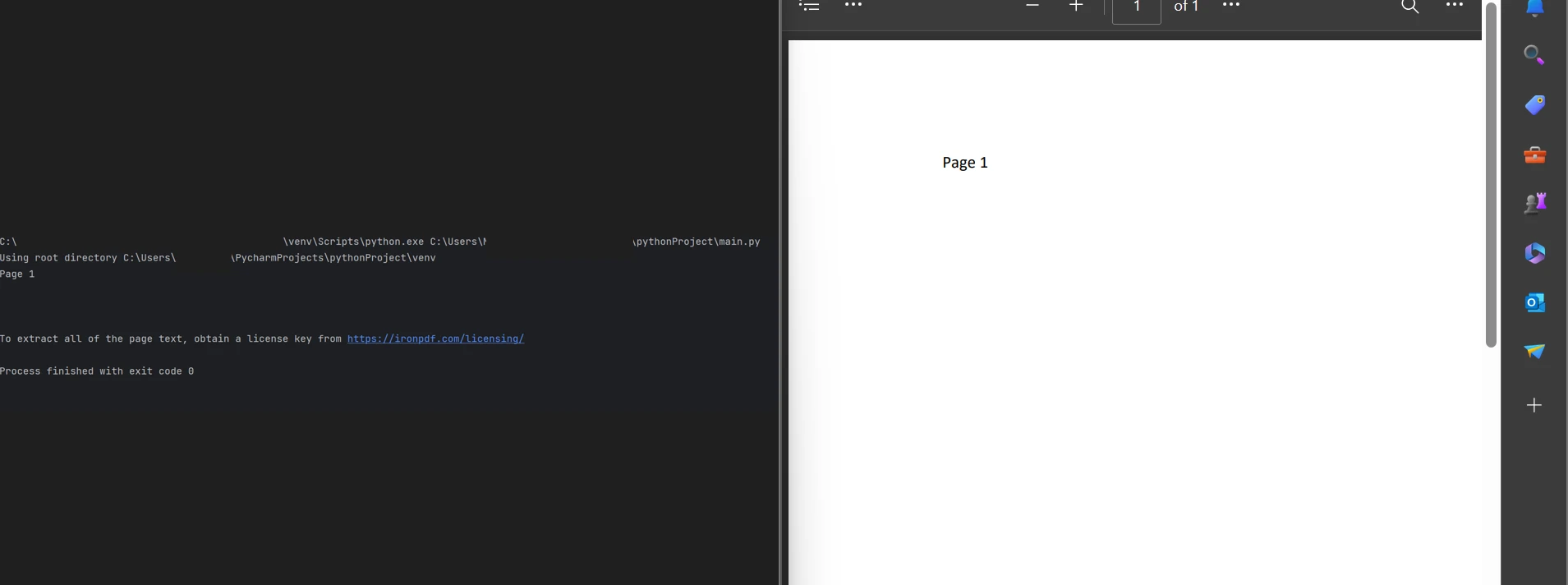
Text anzeigen
Das Code-Beispiel für die zweite Methode, die zum seitenweisen Extrahieren von Text aus einer PDF-Datei verwendet werden kann. Es ist unten angegeben.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from specific page in the document
page_text = pdf.ExtractTextFromPage(1)Die FromFile-Methode wird verwendet, um die PDF-Datei aus einer vorhandenen Datei zu laden und sie in ein PDF-Dateiobjekt zu konvertieren, wie im obigen Code gezeigt. Eine Methode des PDF-Seitenobjekts namens ExtractTextFromPage extrahiert den gesamten Text von einer Seite in einer PDF-Datei. Die Seitennummer muss als Parameter angegeben werden, um den Text von dieser bestimmten Seite zu extrahieren. Dann kann nach dem Extrahieren des Textes page_text verwendet werden, um die Informationen zu halten, die verarbeitet werden können.
Schauen Sie sich weitere Beispiele an, um Text aus einer PDF-Datei zu extrahieren.
Die IronPDF-Bibliothek hingegen bietet starke Sicherheitsmaßnahmen, um potenzielle Risiken zu verringern. Sie ist nicht auf einen bestimmten Browser zugeschnitten und funktioniert mit allen gängigen Browsern. IronPDF ermöglicht es Programmierern, mit nur wenigen Zeilen Code PDF-Dateien zu erstellen und zu lesen. Die IronPDF-Bibliothek bietet eine Reihe von Lizenzierungsoptionen, darunter eine kostenlose Entwicklerlizenz und zusätzliche Entwicklungslizenzen, die käuflich erworben werden können, um den Anforderungen verschiedener Entwickler gerecht zu werden.
IronPDF beinhaltet eine unbefristete Lizenz, eine 30-Tage-Geld-zurück-Garantie, ein Jahr Software-Support und Upgrade-Optionen. Nach dem Erstkauf fallen keine weiteren Kosten an. Diese Lizenzen können in Entwicklungs-, Staging- und Produktionsumgebungen verwendet werden. Erfahren Sie mehr über die Produktlizenzierung.
Downloaden Sie das Softwareprodukt.
30-Tage-Testschlüssel sofort.
15-Tage-Testschlüssel sofort.
Ihr Testschlüssel sollte in der E-Mail sein.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
 Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente