Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


Dieser Artikel behandelt, wie Sie mit der IronPDF-Bibliothek für Python Textdaten aus PDF-Rechnungsdateien extrahieren können.
Installieren Sie die Python-Bibliothek zur Extraktion von Daten aus PDF-Rechnungen.
Verwenden Sie die Methode PdfDocument.FromFile, um eine PDF-Datei zu öffnen.
Extrahieren Sie alle Daten aus der Rechnung mit der Methode "ExtractAllText".
Verwenden Sie die Methode "print", um alle aus der Rechnung extrahierten Daten zu drucken.
IronPDF for Python ist eine robuste Bibliothek für Python, die als Brücke zwischen Python-Anwendungen und PDF-Dokumenten dient. Dieses vielseitige Werkzeug bietet Entwicklern die Möglichkeit, in ihren Python-Projekten mühelos PDF-Dateien zu erstellen, zu bearbeiten und mit ihnen zu interagieren. Hier sind einige der herausragenden Funktionen, die IronPDF zu einer wertvollen Bereicherung machen:
PDF-Erstellung:IronPDF ermöglicht die dynamische Erstellung von PDF-Dateien von Grund auf, sodass Entwickler programmatisch PDFs mit benutzerdefiniertem Inhalt, Styling und Layout erstellen können.
HTML zu PDF-Konvertierung:Es kann HTML-Inhalte, einschließlich Webseiten, in hochwertige PDFs umwandeln, wobei das Layout und die Formatierung des ursprünglichen HTML beibehalten werden, was besonders nützlich für das Erstellen von Berichten und Dokumentationen ist.
PDF-Bearbeitung:Entwickler können vorhandene PDFs einfach bearbeiten, indem sie Text, Bilder und interaktive Elemente hinzufügen, ändern oder entfernen, was es zu einem leistungsstarken Werkzeug für die Dokumentbearbeitung macht.
PDF-Zusammenführung und -Trennung: IronPDF ermöglicht Ihnen,mehrere PDF-Dokumente zusammenführenin eine einzelne Datei odersplit a PDF file into multiple files, die Flexibilität bei der Verwaltung großer PDF-Sammlungen bietet.
PDF-Formulare:Es unterstützt die Erstellung und das Ausfüllen von interaktiven PDF-Formularen, was es ideal für Anwendungen macht, die Benutzereingaben und Datenerfassung erfordern.
Digitale Signaturen:Sie können digitale Signaturen zu PDF-Dokumenten hinzufügen, um die Integrität und Authentizität Ihrer Dateien zu gewährleisten, was für rechtliche und Sicherheitszwecke von entscheidender Bedeutung ist.
Das Einrichten der Umgebung für IronPDF for Python erfordert einige Schritte, um sicherzustellen, dass Sie die Bibliothek effektiv nutzen können. Hier finden Sie eine schrittweise Anleitung:
Erstellen Sie ein neues Python-Projekt in PyCharm und erstellen Sie eine virtuelle Umgebung oder verwenden Sie einen vorhandenen Interpreter.
pip installieren ironpdf
IronPDF von der Kommandozeile aus installieren
In diesem Abschnitt wird gezeigt, wie Daten aus dem Rechnungsformat und dem Ausgabeformat mit der Python-Bibliothek IronPDF extrahiert werden können. Der folgende Code extrahiert alle Daten aus der Rechnung und gibt sie in der Konsole aus.
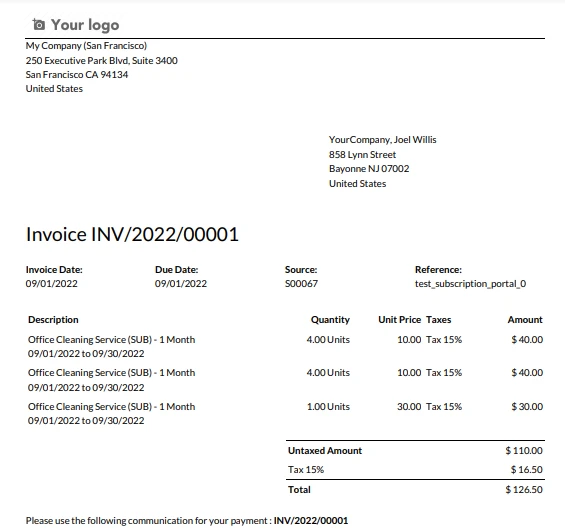
Die Musterrechnung
from ironpdf import *
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
all_text = pdf.ExtractAllText()
print(all_text)Der obige Code lädt eine bestimmte PDF-Datei mit dem Namen "INV_2022_00001.pdf" mit Hilfe der Methode PdfDocument.FromFile. Anschließend extrahiert es Daten über den gesamten Textinhalt aus dem geladenen PDF-Dokument und speichert sie in der Variablen all_text. Schließlich wird der extrahierte Text mit der Funktion print auf der Konsole ausgegeben. Im Wesentlichen automatisiert dieser Code den Prozess der Extraktion von strukturierten und unstrukturierten Textdaten aus einer PDF-Datei und macht sie für die weitere Verarbeitung oder Analyse in einer Python-Umgebung zugänglich.
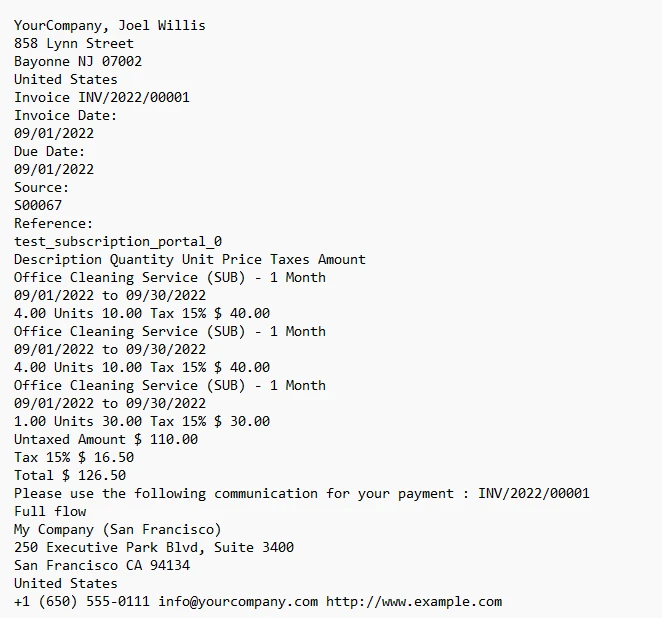
Der Text von der Rechnungsausgabe in die Konsole
Mit IronPDF ist die Extraktion von Rechnungsdaten ein recht einfacher Prozess, wie wir im obigen Beispiel sehen. Das Extrahieren von Daten wie Rechnungsnummer und Betrag aus den PDF-Rechnungsdaten kann ein kniffliger Prozess sein, aber mit IronPDF und Hilfe der Python Open-Source-Bibliothek re kann es erreicht werden. Der folgende Code extrahiert Daten aus PDF-Rechnungen und druckt sie in der Konsole aus.
from ironpdf import *
import re
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
all_text = pdf.ExtractAllText()
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
invoice_number = invoice_number_match.group(1)
if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
print('Invoice Number:' + invoice_number + '\n Amount:$' + amount)Dieses Code-Snippet verwendet Python und die IronPDF-Bibliothek, um Daten aus einem PDF-Dokument zu extrahieren. Es beginnt mit dem Import der erforderlichen Bibliotheken und der Definition von Mustern für reguläre Ausdrücke zur Identifizierung einer Rechnungsnummer und eines Gesamtbetrags innerhalb des Textinhalts der PDF-Datei. Der Code lädt dann die Ziel-PDF-Datei, extrahiert den gesamten Text und sucht dann nach Übereinstimmungen mit den definierten Mustern.
Bei erfolgreichen Übereinstimmungen werden die entsprechenden Werte für die Rechnungsnummer und den Betrag gespeichert; andernfalls wird "Nicht gefunden" zugewiesen. Schließlich drucken das Skript und die Ausgabedatei die extrahierte Rechnungsnummer und den Betrag in die Konsole, wodurch eine effiziente Methode zur Automatisierung der Extraktion spezifischer Daten aus PDF-Dokumenten geboten wird, eine Aufgabe, die häufig in verschiedenen Datenverarbeitungs- und Buchhaltungsanwendungen vorkommt.
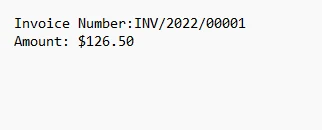
Der Ausgabetext
In der heutigen schnelllebigen Geschäftswelt ist Python ein hervorragender Verbündeter für Unternehmen, die ihre Finanzvorgänge durch die Automatisierung der Extraktion wichtiger Daten aus PDF-Rechnungen rationalisieren möchten. Durch die Nutzung der Fähigkeiten von Python und der IronPDF-Bibliothek können Unternehmen die manuelle Dateneingabe erheblich reduzieren, Fehler minimieren, Zeit sparen und die Gesamtproduktivität bei der Verwaltung von Rechnungen steigern. IronPDF ist mit seinen vielseitigen Funktionen wie PDF-Erzeugung, HTML-zu-PDF-Konvertierung, PDF-Bearbeitung, Zusammenführung, Aufteilung, Formularverarbeitung, digitale Signaturen und genaue Datenextraktion ein leistungsstarkes Werkzeug für diese Aufgaben.
Python-Entwickler können IronPDF durch einfache Einrichtungsprozeduren schnell in ihre Projekte integrieren und so ihre Arbeitsabläufe bei der Rechnungsverarbeitung revolutionieren und die Datenextraktion aus Rechnungen zu einem nahtlosen und effizienten Prozess machen. Das Codebeispiel zur Datenauswertung mit IronPDF finden Sie imdetailliertes Codebeispiel. Das vollständige Tutorial zur Datenauswertung mit IronPDF for Python ist unter folgendem verfügbarPython-Tutorialund für die Extraktion von Rechnungen mit C#, besuchen SieIronOCR-Tutorial.

pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente