Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


Ein robustes Python-Paket namens IronPDF kann zum Extrahieren von Daten, Bildern, Optionsschaltflächen und Listenfeld-Widgets verwendet werden(anstelle von Kontrollkästchen-Widgets)und andere Informationen aus PDF-Dateien. In diesem Artikel wird gezeigt, wie man diese Bibliothek verwendet, um interaktive Formulare mit Daten zu gruppieren und neue PDF-Dateien und PDF-Formulare zu erzeugen.
Holen Sie sich die PDF-Datei, um Text für die Datenverarbeitung zu extrahieren.
Erstellen Sie ein Projekt in PyCharm.
Konfigurieren Sie die erforderlichen Python-Bibliotheken für Ihr Projekt.
Extrahieren Sie Informationen aus bestimmten Seiten des PDF-Dokuments.
DieIronPDF for Python die Bibliothek erweitert nahtlos die Python-Programmierung, indem sie eine effiziente PDF-Datenverarbeitung ermöglicht und eine Vielzahl von PDF-Operationen bietet. Seine Integrationsmöglichkeiten erstrecken sich auf verschiedene Frameworks und erweitern die Möglichkeiten zur Entwicklung grafischer Benutzeroberflächen.
Python ist eine vielseitige Programmiersprache, mit der sich schnell und einfach benutzerfreundliche grafische Oberflächen erstellen lassen, weshalb sie von vielen Entwicklern bevorzugt wird. Ihre dynamische Natur unterscheidet sie von anderen Programmiersprachen. Die Einführung der IronPDF-Bibliothek in Python erweist sich als ein unkomplizierter Prozess, der eine effiziente Handhabung und Verarbeitung von PDF-Daten ermöglicht.
Für die schnelle und sichere Entwicklung voll funktionsfähiger grafischer Benutzeroberflächen können Entwickler eine breite Palette vorinstallierter Tools und beliebter Python-Bibliotheken nutzen, darunter PyQt, wxWidgets, Kivy und viele andere.
Darüber hinaus integriert die IronPDF-Bibliothek nahtlos verschiedene Funktionen aus anderen Frameworks, insbesondere im Kontext von .NET Core, das die Unterstützung auf Python und mehrere andere Programmiersprachen ausweitet. Weitere Informationen zu IronPDF for Python finden Sie, wenn Sie die Website besuchen.offizielle Website.
Die IronPDF for Python-Bibliothek vereinfacht den Prozess der Erstellung und Verwaltung von Websites, insbesondere bei der Python-basierten Webentwicklung unter Verwendung von Frameworks wie Django, Flask und Pyramid. Es ist ein wertvolles Werkzeug, auf das sich beliebte Websites und Online-Dienste wie Reddit, Mozilla und Spotify verlassen, um ihre Funktionen und Merkmale zu verbessern.
HTML, HTML5, ASPX und Razor/MVC View sind nur einige der wenigen Formate, die mit IronPDF in das PDF-Format konvertiert werden können. Darüber hinaus bietet IronPDF die praktische Fähigkeit,pDF-Dateien erzeugenaus sowohl Bildern als auch HTML-Seiten.
Das IronPDF-Toolkit kann bei verschiedenen Aufgaben helfen, einschließlich der Erstellung interaktiver PDFs, der Erleichterung vonInteraktive Formularausfüllung und -einreichung, die effiziente zusammenlegung undteilenvon PDF-Dateien, genautext- und Bildextraktionumfassende Textsuche in PDF-Dateien, die Umwandlung vonPDFs in Bilder, und die Flexibilität, Schriftgrößen, Rahmen und Hintergrundfarben anzupassen. IronPDF kann auch mühelos PDF-Dateien konvertieren.
IronPDF geht einen Schritt weiter, indem es seine Unterstützung für User Agents, Proxies, Cookies, HTTP-Header und Formularvariablen erweitert und somit verbessertHTML-Loginformular-Validierung. Sie verwendetBenutzernamen und Passwörter, um den Benutzerzugang zu schützenum Text in PDFs zu sichern.
APDF-Dateidruckkann aus vielen Quellen erstellt werden, wie z. B. aus einem String, Stream oder einer URL, und ist mit nur wenigen Codezeilen erreichbar.
IronPDF kann produzierenabgeflachte PDF-Dokumenteindem interaktive Elemente konvertiert werden und sichergestellt wird, dass der Inhalt des Dokuments unveränderlich und sichtbar bleibt, aber nicht bearbeitbar ist.
Stellen Sie sicher, dass Sie die Programmiersprache Python auf Ihrem Computer installiert haben. Dies ist wichtig, da Python-Bibliotheken häufig für verschiedene Aufgaben benötigt werden. Um dies zu erreichen, besuchen Sie die offizielle Python-Website und laden Sie die neueste Version herunter, die mit Ihrem Betriebssystem kompatibel ist. Dadurch wird sichergestellt, dass Sie über die richtigen Werkzeuge verfügen, um effektiv mit Python-Bibliotheken zu arbeiten.
Nach der Installation von Python richten Sie eine virtuelle Umgebung ein, um die für Ihr Projekt erforderlichen Bibliotheken zu isolieren, da einige Projekte möglicherweise einige notwendige Bibliotheken von Python benötigen. Das venv-Modul, das es Ihnen ermöglicht, virtuelle Umgebungen zu erstellen und zu verwalten, kann Ihrem Konvertierungsprojekt ein ordentliches, unabhängiges Arbeitsumfeld bieten, insbesondere wenn Sie mit mehreren Python-Bibliotheken arbeiten.
Sie haben die Möglichkeit, Python-Code mit einem beliebigen Texteditor oder einer beliebigen Programmierumgebung zu schreiben, z. BVisual Studio-Code, PyCharm, oderErhabener Text. Dieser Artikel verwendet jedoch PyCharm, eine IDE zum Schreiben von Python-Code, um ein Python-Projekt zu erstellen.
Sobald PyCharm IDE gestartet ist, wählen Sie Neues Projekt.
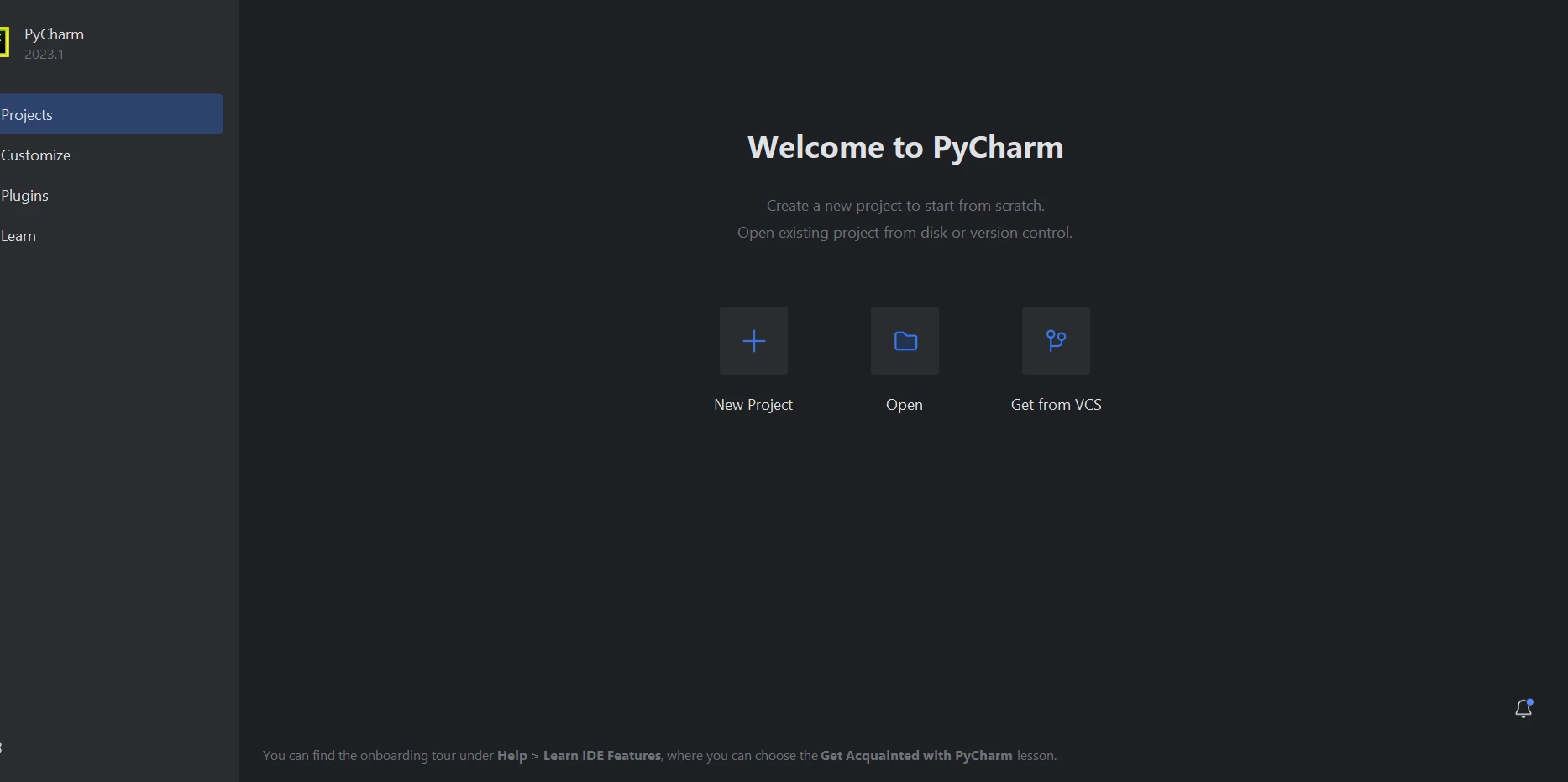
PyCharm IDE zum Erstellen eines neuen Python-Projekts
Nachdem Sie Neues Projekt ausgewählt haben, wird ein neues Fenster angezeigt, in dem Sie die Umgebung und den Speicherort des Projekts angeben können. Das folgende Bild könnte mehr Klarheit schaffen.
Nachdem Sie den Projektstandort und die Umgebungsdetails festgelegt und auf Erstellen geklickt haben, gelangen Sie in die Benutzeroberfläche von PyCharm. Hier finden Sie die Struktur und die Codedateien Ihres Projekts. Dies ist Ihr Arbeitsbereich für die Verwaltung und Entwicklung Ihres Projekts. Python 3.9 ist die in diesem Handbuch verwendete Version.
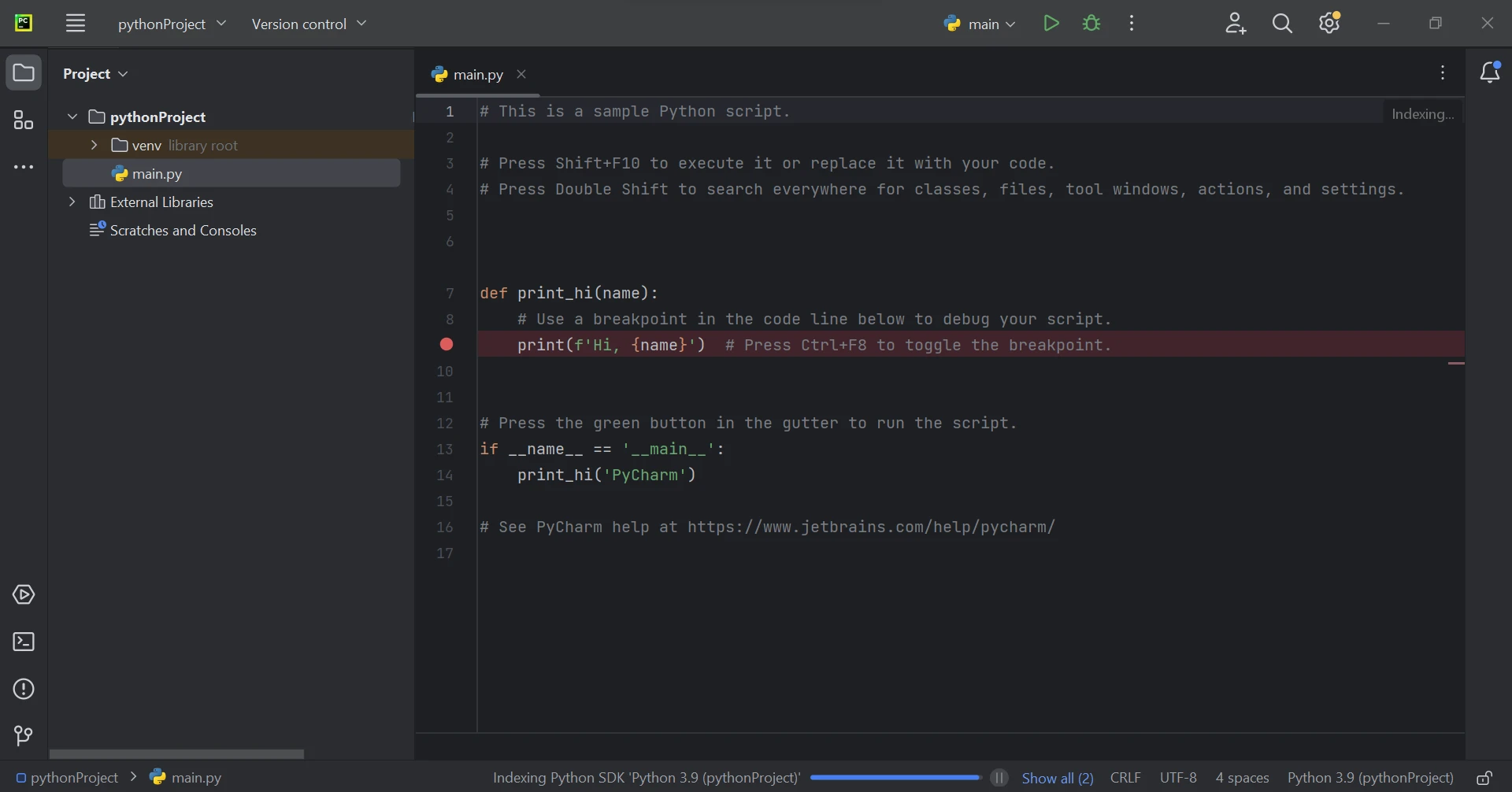
Die Haupt-Python-Datei
Die Python-Bibliothek IronPDF arbeitet häufig mit .NET 6.0 zusammen. Daher muss Ihr Computer mit der .NET 6.0-Laufzeit ausgestattet sein, um IronPDF für Python effektiv nutzen zu können.
Für Linux- und Mac-Benutzer kann es erforderlich sein, .NET zu installieren, bevor sie dieses Python-Modul verwenden können. Eine Anleitung für die Beschaffung der erforderlichen Laufzeitumgebung finden Sie hierMicrosoft-Downloadseite.
Sie müssen das Paket "ironpdf" installieren, um mit PDF-Dateien zu arbeiten, einschließlich Erstellen, Bearbeiten und Öffnen. Um dies in PyCharm zu tun, öffnen Sie das Terminalfenster und geben Sie diesen Befehl ein:
pip installieren ironpdf
Die Installation des Pakets "IronPDF" ist in der nachstehenden Abbildung dargestellt.
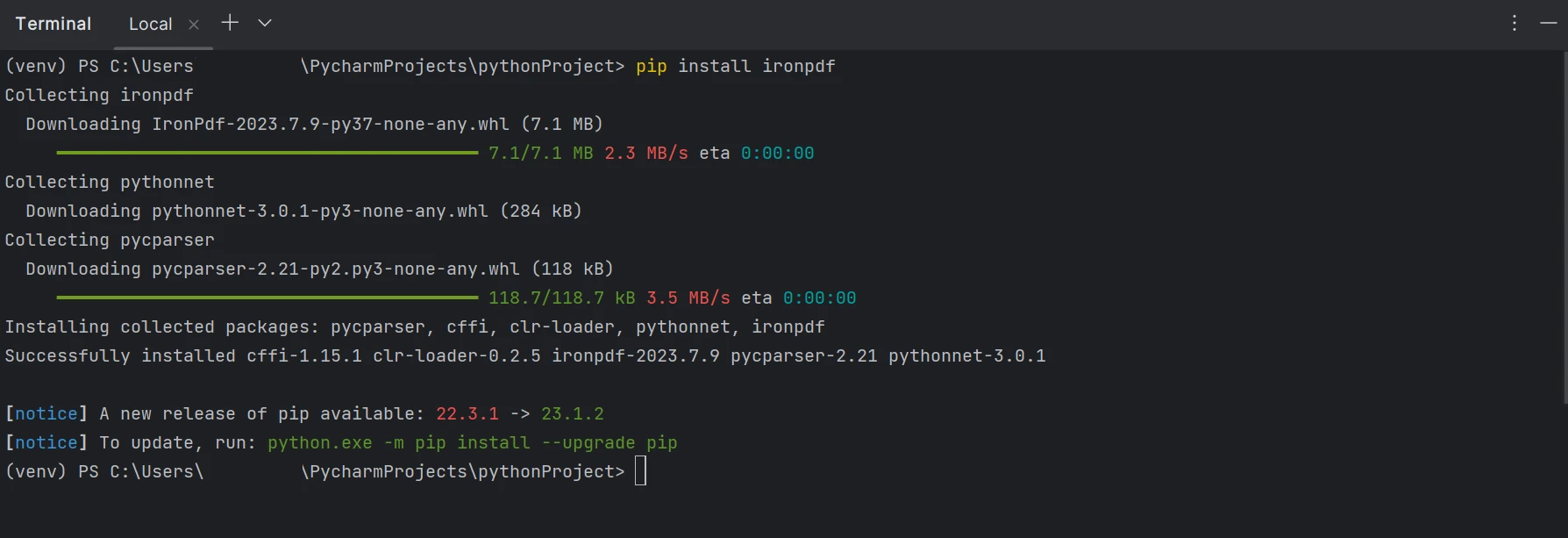
IronPDF Installation
Die IronPDF for Python-Bibliothek verwandelt PDF-Seiten effizient in PDF-Seitenobjekte und vereinfacht den Prozess der Textextraktion aus PDF-Dateien.
In diesem Beispiel wird die Extraktion von Text aus einem vorhandenen PDF-Dokument mit IronPDF demonstriert. In diesem Fall wird das unten stehende PDF-Dokument für diese Demonstration verwendet.
Die erste Methode konzentriert sich auf die Extraktion des gesamten Textes aus der PDF-Datei. Schreiben Sie den folgenden Code, um auf einfache Weise eine vollständige Datenextraktion aus der PDF-Eingabedatei durchzuführen:
from ironpdf import *
pdf = PdfDocument.FromFile("sampleData.pdf")
all_text = pdf.ExtractAllText()Wie im obigen Code dargestellt, spielt die Methode "FromFile" eine Schlüsselrolle. Es lädt die PDF-Datei von einem vorhandenen Speicherort, um sie in PdfDocument-Objekte zu konvertieren. Mit diesem Objekt kann sowohl auf Textinhalte als auch auf Bilder innerhalb der PDF-Seiten zugegriffen werden. Um den gesamten Text aus der gegebenen PDF-Datei zu extrahieren, wird eine Methode namens ExtractAllText verwendet. Der extrahierte Text wird dann in einer Zeichenkette gespeichert und kann weiterverarbeitet werden.
Im Folgenden finden Sie den Code für den zweiten Ansatz, der explizit Text aus jeder Seite der PDF-Datei extrahiert.
from ironpdf import *
pdf = PdfDocument.FromFile("sampleData.pdf")
for xpage in range(pdf.PageCount):
print(pdf.ExtractTextFromPage(xpage))Dieser Beispielcode lädt zunächst die gesamte PDF-Datei und wandelt sie in ein PdfDocument-Objekt namens pdf um. Um sicherzustellen, dass jede einzelne Seite der PDF-Datei der Reihe nach verarbeitet wird, erfolgt der Zugriff auf jede Seite über ihre Seitennummer oder ihren Seitenindex im pdf-Objekt. Zu diesem Zweck wird zunächst die Gesamtzahl der Seiten im Eingabe-PDF mithilfe der Methode "PageCount" des Objekts "pdf" ermittelt.
Mit dieser Seitenzahl durchläuft eine "for"-Schleife jede Seite und ruft die Funktion "ExtractTextFromPage" auf, um Text aus jeder Seite des PDF-Dokuments zu extrahieren. Der extrahierte Text kann in einer String-Variablen gespeichert oder auf dem Benutzerbildschirm angezeigt werden. So ermöglicht diese Methode die organisierte Extraktion von Text aus jeder einzelnen PDF-Seite. Diese Methoden von IronPDF, einer für PDF-Aufgaben konzipierten Python-Bibliothek, unterstreichen ihre Fähigkeit, Textextraktion aus PDF-Dateien einfach und gründlich zu machen. Diese Zugänglichkeit hat viele praktische Anwendungen und verbessert die Nützlichkeit von PDFs in verschiedenen Bereichen.
DieIronPDF bibliothek enthält strenge Sicherheitsmaßnahmen, um potenzielle Risiken zu mindern und die Datensicherheit zu gewährleisten. Es funktioniert auf allen gängigen Browsern ohne besondere Einschränkungen. IronPDF versetzt Entwickler in die Lage, PDF-Dokumente mit nur wenigen Zeilen Python-Code effizient zu generieren und zu analysieren. Um den verschiedenen Anforderungen von Entwicklern gerecht zu werden, bietet die IronPDF-Bibliothek eine Reihe von Lizenzierungsmöglichkeiten, die eine kostenlose Entwicklerlizenz und zusätzliche Entwicklungslizenzen umfassen, die erworben werden können.
Das Lite-Paket kostet $749 und gibt Ihnen eine permanente Lizenz. Sie erhalten außerdem eine 30-Tage-Geld-zurück-Garantie, ein Jahr Software-Wartung und die Möglichkeit, Updates zu erhalten. Nach dem Kauf fallen keine weiteren Kosten an. Sie können diese Lizenz in Produktion, Staging und Entwicklung verwenden. IronPDF bietet auch kostenlose Lizenzen mit gewissen Zeit- und Freigabebeschränkungen an. Sie können es 30 Tage lang ohne Wasserzeichen testen. Für die Kosten und wie Sie die Testversion von IronPDF erhalten, besuchen Sie bitte die IronPDF'slizenzierungsseite.

pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente