Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


Pandas ist ein beliebtes Datenanalysewerkzeug in der Programmiersprache Python, das für seine Benutzerfreundlichkeit und Vielseitigkeit im Umgang mit tabellarischen Daten bekannt ist. Dieses Handbuch führt Sie durch die Grundlagen der Verwendung von Pandas und konzentriert sich dabei auf praktische Beispiele und effiziente Techniken zur Datenmanipulation und -analyse.
Die primäre Struktur inPandas ist der DataFrame, ein leistungsfähiges Werkzeug für die Datenanalyse und -manipulation. Zu Beginn wollen wir uns ansehen, wie man auf Daten innerhalb einerDataFrame.
Wenn Sie zum Beispiel eine CSV-Datei mit Ihren Daten haben, können Sie diese in einen DataFrame laden und mit der Bearbeitung beginnen. Der folgende Code zeigt, wie man Daten aus einer CSV-Datei lädt:
import pandas as pd
df = pd.read_csv('your_file.csv')Nach dem Laden gibt es mehrere Möglichkeiten, auf die Daten im DataFrame zuzugreifen. Sie können auf die Daten einer Spalte über den Spaltenindex oder den Namen der Spalte zugreifen. Der folgende Code greift beispielsweise auf Daten aus einer Spalte mit dem Namen "data" zu:
column_data = df ['data']In ähnlicher Weise können Sie auch auf Zeilendaten zugreifen, indem Sie Zeilenindizes oder Bedingungen verwenden:
row_data = df.loc [0] # Accesses the first rowEin häufiges Problem bei der Datenanalyse ist der Umgang mit Nullwerten. Pandas bietet robuste Methoden, um diese zu handhaben. Der Code füllt Nullwerte mit einem bestimmten Wert, oder Sie können Zeilen oder Spalten mit Nullen löschen. Hier ein Codebeispiel für das Füllen von Nullwerten:
df.fillna(0, inplace=True)DataFrames sind vielseitig und ermöglichen die Erstellung neuer Spalten. Egal, ob es sich um eine neue Integer-Spalte oder eine aus vorhandenen Daten abgeleitete Spalte handelt, der Prozess ist unkompliziert. Hier ist ein Beispiel für das Hinzufügen einer neuen Spalte zu einem DataFrame:
df ['new_column'] = df ['existing_column'] * 10Sie können Daten auch anhand von Bedingungen filtern. Wenn Sie beispielsweise eine neue Spalte mit Daten aus einer Spalte mit dem Namen "Daten" erstellen möchten, die größer als ein bestimmter Wert ist:
df ['new_column'] = df [df ['column_named_data'] > value]Pandas eignen sich hervorragend zum Gruppieren und Aggregieren von Daten. Der folgende Code verwendet die Methode groupby und gruppiert die Daten nach einer bestimmten Spalte und berechnet Aggregatfunktionen wie Mittelwert, Summe usw.:
grouped_data = df.groupby('column_name').mean()Die Handhabung von Datum und Uhrzeit ist in vielen Datensätzen entscheidend. Wenn Ihr Datenrahmen eine Datumsspalte hat, vereinfacht Pandas Aufgaben wie Filtern nach Datum, Aggregieren nach Monat oder Jahr usw. Hier ist ein einfaches Beispiel:
df ['date_column'] = pd.to_datetime(df ['date_column'])
Für komplexere Datenmanipulationen bietet Pandas die Möglichkeit, benutzerdefinierte Funktionen zu schreiben und diese auf Ihren DataFrame anzuwenden. Dies ist besonders nützlich für Szenarien, die einen sprachintegrierten Abfrageansatz erfordern.
def custom_function(row):
# Your custom manipulation
return modified_row
df.apply(custom_function, axis=1)Pandas lässt sich gut mit Bibliotheken wie Matplotlib und Seaborn zur Datenvisualisierung integrieren. Die Anzeige von Daten in einem visuellen Format kann so einfach sein wie im folgenden Quellcode gezeigt:
df.plot(kind='bar')Der obige Code verwendet die Methode plot, um ein Balkendiagramm zur Datenvisualisierung zu erstellen.
Pandas ist, wie bereits erwähnt, ein robustes Werkzeug zur Datenmanipulation und -analyse in Python. IronPDF, eine von Iron Software entwickelte Bibliothek, bietet zusätzliche Funktionen, die Datenanalyse-Workflows verbessern können, insbesondere im Umgang mit PDF-Inhalten.
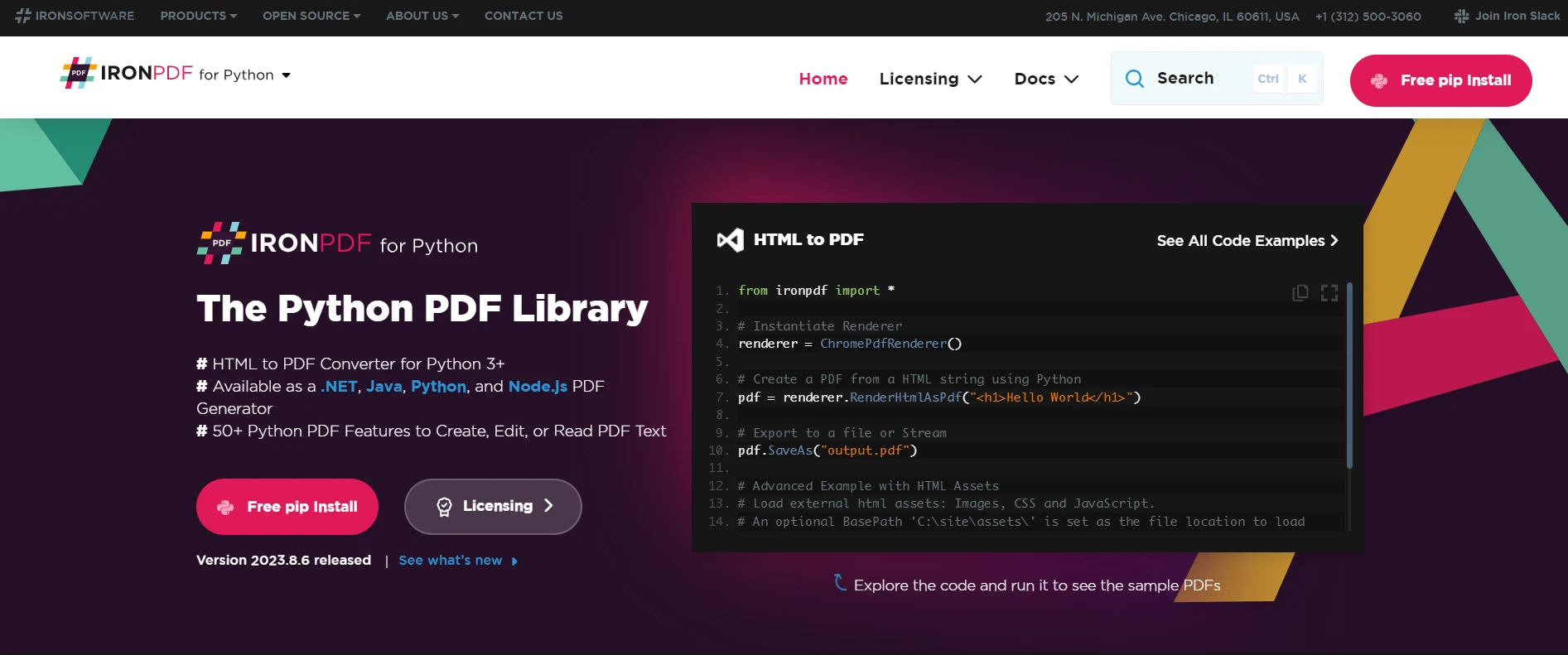
IronPDF ist eine vielseitige Python PDF-Bibliothek zum Erstellen, Bearbeiten und Extrahieren von PDF-Inhalten in Python-Projekten. Es ist so konzipiert, dass es auf verschiedenen Plattformen wie Windows, Mac, Linux und Cloud-Umgebungen funktioniert, was es zu einer geeigneten Wahl für verschiedene Python-Projekte macht. Diese Bibliothek ist besonders leistungsfähig im Umgang mit PDF-Dateien und bietet eine nahtlose Erfahrung und effiziente Verarbeitung, was für Entwickler, die mit PDF-Daten arbeiten, entscheidend ist.
Die Integration von IronPDF mit Pandas eröffnet Möglichkeiten für eine erweiterte Datenverarbeitung und Berichterstattung. Stellen Sie sich einen Analyse-Workflow vor, bei dem Sie Pandas für die Datenmanipulation und -analyse verwenden und dann Ihre Ergebnisse und Visualisierungen mit IronPDF nahtlos in einen professionell formatierten PDF-Bericht umwandeln. Diese Integration kann den Prozess der gemeinsamen Nutzung und Präsentation von Datenanalyseergebnissen erheblich rationalisieren.
Zusammenfassend lässt sich sagen, dass Pandas zwar die Grundlage für die Datenanalyse bildet, die Integration vonIronPDF erweitert den Arbeitsablauf der Datenanalyse in Python um eine neue Dimension. Diese Kombination erhöht nicht nur die Effizienz von Datenmanipulations- und -analyseprozessen, sondern verbessert auch die Art und Weise, wie Daten präsentiert und gemeinsam genutzt werden, was sie zu einem unschätzbaren Vorteil für Python-basierte Datenanalysten und Wissenschaftler macht.
IronPDF für Nutzer, die sich vor dem Kauf über die Funktionen informieren möchten.
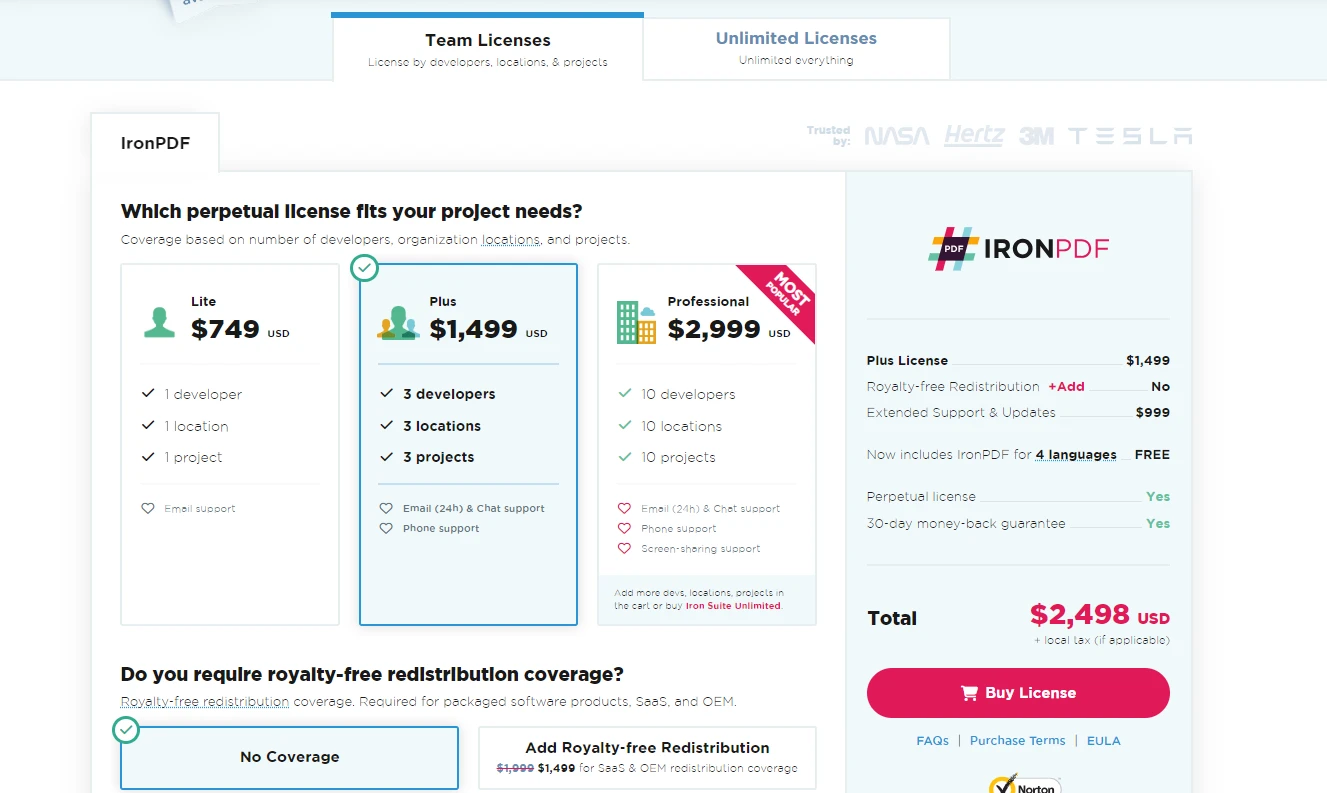
Für diejenigen, die eine vollständige Lizenz erwerben möchten,IronPDF ermöglicht es den Nutzern, einen Plan zu wählen, der den Bedürfnissen und dem Budget ihres Projekts am besten entspricht.

pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente