Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


XGBoost steht für eXtreme Gradient Boosting, einen leistungsstarken und genauen Machine-Learning-Algorithmus. Es wurde hauptsächlich in der Regressionsanalyse, Klassifikation und bei Rangfolgeproblemen angewendet. Es umfasst Funktionen wie Regulierung, die helfen, Überanpassung zu vermeiden,Parallelismusund fehlende Datenverarbeitung.
IronPDF ist eine Python-Bibliothek zum Erstellen, Ändern und Lesen von PDF-Dateien. Es ermöglicht, HTML, Bilder oder Text einfach in PDFs zu konvertieren und kann auch Kopf- und Fußzeilen sowie Wasserzeichen hinzufügen. Obwohl es hauptsächlich um die Verwendung in Python geht, ist es bemerkenswert, dass das NET-Tool mit Hilfe von Interoperabilitätswerkzeugen wie Python in dieser Programmiersprache implementiert werden kann.
Die Kombination von XGBoost und IronPDF bietet breitere Anwendungsmöglichkeiten. Durch IronPDF kann das Prognoseergebnis mit der Erstellung interaktiver PDF-Dokumente kombiniert werden. Diese Kombination ist besonders hilfreich bei der Erstellung präziser Unternehmensdokumente und -zahlen sowie der aus den angewandten prädiktiven Modellen gewonnenen Ergebnisse.
XGBoost ist eine leistungsstarke Machine-Learning-Bibliothek für Python, die auf Ensemble-Learning basiert und äußerst effizient und flexibel ist. XGBoost ist eine Implementierung eines Gradienten-Boosting-Algorithmus von Tianqi Chen, die zusätzliche Optimierungen enthält. Die Effektivität wurde in vielen Anwendungsbereichen mit entsprechenden Aufgaben, die durch diese Methode gelöst werden können, wie Klassifikation, Regression, Ranking-Aufgaben usw., bewiesen. XGBoost verfügt über mehrere einzigartige Merkmale: Das Fehlen von fehlenden Werten stellt kein Problem dar; Es besteht die Möglichkeit, L1- und L2-Normen einzusetzen, um gegen Overfitting vorzugehen.
Das Training wird parallel durchgeführt, was den Trainingsprozess erheblich beschleunigt. Baumschnitt wird in XGBoost ebenfalls tiefensuchend durchgeführt, was hilft, die Modellkapazität zu verwalten. Eine seiner Funktionen ist die Kreuzvalidierung von Hyperparametern und integrierte Funktionen zur Bewertung der Leistung des Modells. Die Bibliothek funktioniert gut mit anderen Data-Science-Utilities, die in einer Python-Umgebung integriert sind, wie NumPy, SciPy und sci-kit-learn, was es ermöglicht, sie in eine bestehende Umgebung zu integrieren. Dennoch ist XGBoost aufgrund seiner Geschwindigkeit, Einfachheit und hohen Leistungsfähigkeit zu einem unverzichtbaren Werkzeug im „Arsenal“ vieler Datenanalysten, Machine-Learning-Spezialisten und aufstrebender Datenwissenschaftler im Bereich neuronaler Netze geworden.
XGBoost ist bekannt für seine vielen Funktionen, die es bei verschiedenen maschinellen Lernaufgaben und maschinellen Lernalgorithmen vorteilhaft machen und die Implementierung zugänglicher machen. Hier sind die Hauptmerkmale von XGBoost in Python. Hier sind die Hauptmerkmale von XGBoost in Python:
Regularisierung:
Wendet L1- und L2-Regularisierungstechniken an, um das Overfitting zu reduzieren und die Leistung des Modells zu verbessern.
Parallelverarbeitung:
Das vortrainierte Modell nutzt alle CPU-Kerne während des Trainings, was das Training von Modellen erheblich verbessert.
Umgang mit fehlenden Daten:
Ein Algorithmus, der bei trainiertem Modell automatisch entscheidet, wie am besten mit fehlenden Werten umgegangen wird.
Baumschnitt:
Beim Baumschnitt wird die Tiefensuche in den Bäumen mit dem Parameter „max_depth“ erreicht, wodurch Overfitting reduziert wird.
Eingebaute Kreuzvalidierung:
Es umfasst integrierte Methoden der Kreuzvalidierung zur Modellbewertung und Hyperparameter-Optimierung. Da es die Kreuzvalidierung nativ unterstützt und durchführt, ist die Implementierung weniger kompliziert.
Skalierbarkeit:
Es ist für Skalierbarkeit optimiert; So kann es große Datenmengen analysieren und Daten im Merkmalsraum angemessen verarbeiten.
Unterstützung für mehrere Sprachen:
XGBoost wurde ursprünglich in Python entwickelt; Um jedoch den Anwendungsbereich zu erweitern, unterstützt es auch R, Julia und Java.
Verteiltes Rechnen:
Das Paket ist so konzipiert, dass es vertrieben werden kann, was bedeutet, dass es auf mehreren Computern ausgeführt werden kann, um große Datenmengen zu verarbeiten.
Benutzerdefinierte Ziel- und Bewertungsfunktionen:
Es ermöglicht Nutzern, Zielfunktionen und Leistungskennzahlen für ihre spezifischen Anforderungen einzurichten. Darüber hinaus unterstützt es sowohl binäre als auch Mehrklassenklassifizierung.
Funktionswichtigkeit:
Es hilft dabei, den Wert verschiedener Funktionen zu identifizieren, kann bei der Auswahl von Funktionen für einen bestimmten Datensatz unterstützen und bietet Interpretationen mehrerer Modelle.
Sparse Aware
Es arbeitet gut mit spärlichen Datenformaten, was sehr nützlich ist, wenn man mit Daten arbeitet, die viele NULL-Werte oder Nullen enthalten.
Integration mit anderen Bibliotheken:
Es ergänzt die kurzlebige Beliebtheit von Datenwissenschaftsbibliotheken wie NumPy, SciPy und sci-kit-learn, die sich leicht in Datenwissenschaftsarbeitsabläufe integrieren lassen.
In Python gibt es mehrere Prozesse, die an der Erstellung und Konfiguration eines XGBoost-Modells beteiligt sind: der Prozess der Datensammlung und -vorverarbeitung, die Erstellung des Modells, die Verwaltung des Modells und die Bewertung des Modells. Nachfolgend finden Sie eine ausführliche Anleitung, die Ihnen beim Einstieg hilft:
XGBoost installieren
Überprüfen Sie zunächst, ob das Xgboost-Paket auf Ihrem System vorhanden ist. Sie können es mit pip auf Ihrem Computer installieren:
pip install xgboostBibliotheken importieren
import xgboost as xgb
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorDaten vorbereiten
In diesem Beispiel werden wir den Boston Housing-Datensatz verwenden:
# Load the Boston housing dataset
boston = load_boston()
#load default value from the package
X = boston.data
y = boston.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)DMatrix erstellen
XGBoost verwendet eine selbstdefinierte Datenstruktur namens DMatrix für das Training.
# Create DMatrix for training and testing sets
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)Parameter festlegen
Konfigurieren Sie die Modellparameter. Eine Beispielkonfiguration ist wie folgt:
# Set parameters
params = {
'objective': 'reg:squarederror', # Objective function
'max_depth': 4, # Maximum depth of a tree
'eta': 0.1, # Learning rate
'subsample': 0.8, # Subsample ratio of the training instances
'colsample_bytree': 0.8, # Subsample ratio of columns when constructing each tree
'seed': 42 # Random seed for reproducibility
}Das Modell trainieren
Verwenden Sie die Methode train, um ein XGBoost-Modell zu trainieren.
# Number of boosting rounds
num_round = 100
# Train the model
bst = xgb.train(params, dtrain, num_round)Vorhersagen treffen
Nun verwenden Sie dieses trainierte Modell und treffen Vorhersagen auf dem Testset.
# Make predictions
preds = bst.predict(dtest)Bewerten Sie das Modell
Überprüfen Sie die Leistung des maschinellen Lernmodells mit einer geeigneten Metrik, zum Beispiel dem Root Mean Squared Error:
# Calculate mean squared error
mse = mean_squared_error(y_test, preds)
print(f"Mean Squared Error: {mse}")Modell speichern und laden
Sie können das trainierte Modell in einer Datei speichern und bei Bedarf später laden:
# Save the model
bst.save_model('xgboost_model.json')
# Load the model performance
bst_loaded = xgb.Booster()
bst_loaded.load_model('xgboost_model.json')Unten ist die generierte JSON-Datei.

Nachfolgend finden Sie die Basisinstallation beider Bibliotheken, mit einem Beispiel, wie Sie mit XGBoost für die Datenanalyse und IronPDF zur Erstellung von PDF-Berichten beginnen können.
Verwenden Sie das leistungsstarke Python-Paket IronPDF, um PDFs zu erstellen, zu bearbeiten und zu lesen. Dies ermöglicht Programmierern, viele programmierungsbasierte Operationen an PDFs durchzuführen, wie das Arbeiten mit vorhandenen PDFs und das Konvertieren von HTML in PDF-Dateien. IronPDF ist eine effiziente Lösung für Anwendungen, die eine dynamische Erstellung und Verarbeitung von PDFs erfordern, da es eine anpassungsfähige und benutzerfreundliche Methode zur Erstellung hochwertiger PDF-Dokumente bietet.
IronPDF kann PDF-Dokumente aus jedem HTML-Inhalt erstellen, sei es neu oder bereits vorhanden. Es ermöglicht die Erstellung von schönen, künstlerischen PDF-Veröffentlichungen aus Webinhalten, die die Kraft von modernem HTML5, CSS3 und JavaScript in all ihren Formen einfangen.
Es kann Text, Bilder, Tabellen und andere Inhalte in neu programmatisch generierte PDF-Dokumente einfügen. Mit IronPDF können bestehende PDF-Dokumente geöffnet und zur weiteren Bearbeitung bearbeitet werden. In einem PDF können Sie Inhalt bearbeiten/hinzufügen und spezifischen Inhalt im Dokument bei Bedarf löschen.
Es verwendet CSS, um den Inhalt in PDFs zu gestalten. Es unterstützt komplexe Layouts, Schriftarten, Farben und all diese Designkomponenten. Darüber hinaus ermöglichen die Methoden zur Wiedergabe von HTML-Material, die mit JavaScript verwendet werden können, die dynamische Erstellung von Inhalten in PDFs.
IronPDF kann über Pip installiert werden. Verwenden Sie den folgenden Befehl, um es zu installieren:
pip install ironpdfImportieren Sie alle relevanten Bibliotheken und laden Sie Ihren Datensatz. In unserem Fall werden wir den Boston Housing-Datensatz verwenden:
import xgboost as xgb
import numpy as np
from ironpdf import * from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
boston = load_boston()
X = boston.data
y = boston.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Train model
num_round = 100
bst = xgb.train(params, dtrain, num_round)
# Make predictions
preds = bst.predict(dtest)
# Create a PDF document
iron_pdf = ChromePdfRenderer()
# Create HTML content
html_content = f"""
<html>
<head>
<title>XGBoost Model Report</title>
</head>
<body>
<h1>XGBoost Model Report</h1>
<p>Mean Squared Error: {mse}</p>
<h2>Predictions</h2>
<ul>
{''.join([f'<li>{pred}</li>' for pred in preds])}
</ul>
</body>
</html>
"""
pdf=iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("XGBoost_Report.pdf")
print("PDF document generated successfully.")Jetzt erstellen Sie Objekte der Klasse DMatrix, um Ihre Daten effizient zu verwalten, und richten dann die Modellparameter in Bezug auf die Zielfunktion und Hyperparameter ein. Nach dem Trainieren des XGBoost-Modells auf dem Testdatensatz vorhersagen. Sie können den mittleren quadratischen Fehler oder ähnliche Metriken verwenden, um die Leistung zu bewerten. Erstellen Sie dann mit IronPDF ein PDF mit allen Ergebnissen.
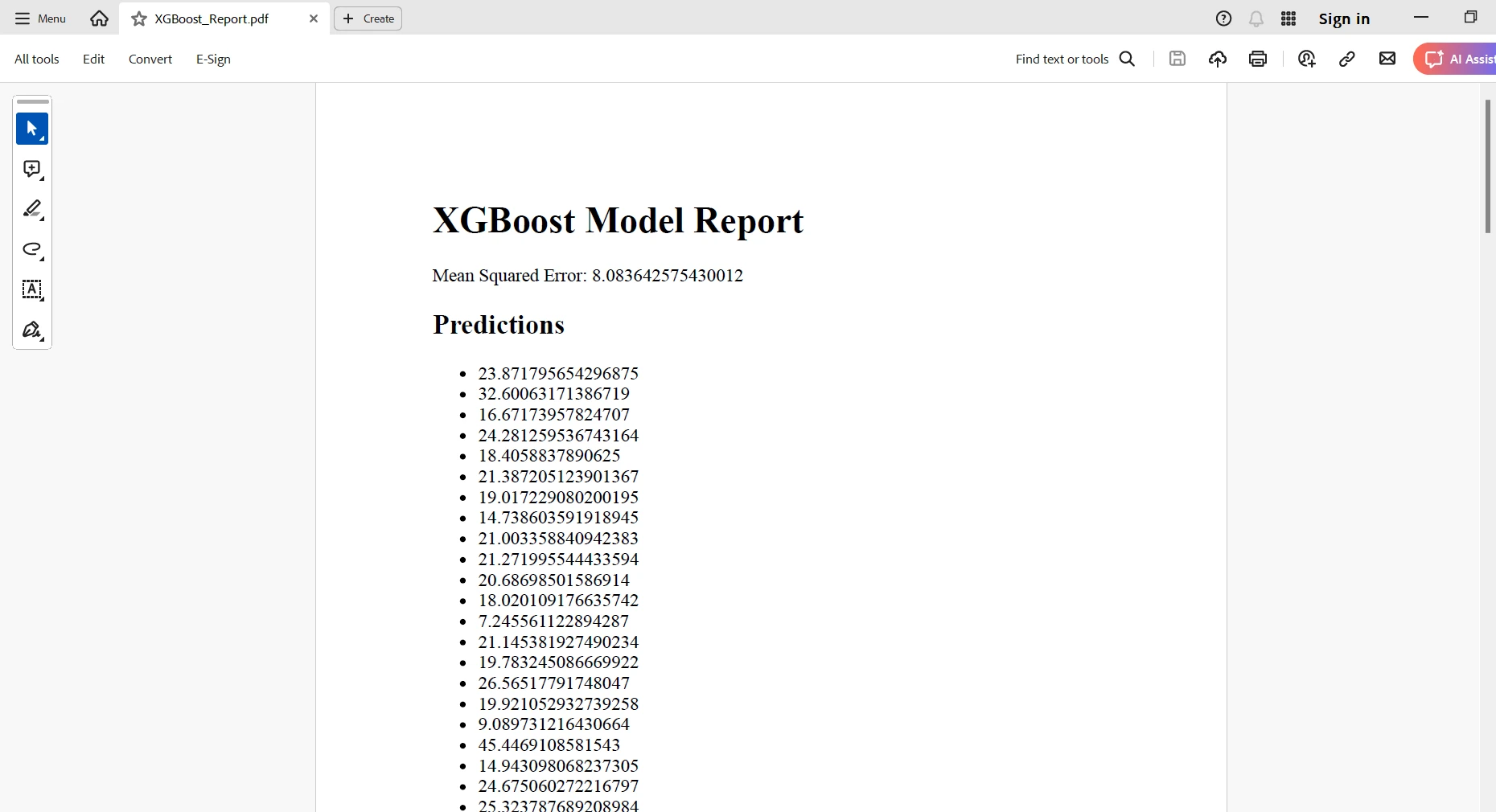
Sie erstellen eine HTML-Darstellung mit allen Ihren Ergebnissen; dann verwenden Sie die RenderHtmlAsPdf-Klasse von IronPDF, um diesen HTML-Inhalt in einPDF-Dokument. Schließlich können Sie diesen erstellten PDF-Bericht an einem gewünschten Ort speichern. Mit anderen Worten, diese Integration ermöglicht Ihnen die Automatisierung der Erstellung sehr aufwendiger, professioneller Berichte, in denen die Erkenntnisse aus Ihren Machine-Learning-Modellen zusammengefasst werden.
Zusammenfassend sind XGBoost und IronPDF für fortschrittliche Datenanalyse und professionelle Berichtserstellung integriert. Die Effizienz und Skalierbarkeit von XGBoost bieten die beste Lösung im Streaming durch komplizierte maschinelle Lernaufgaben mit robusten Vorhersagefähigkeiten und hervorragenden Werkzeugen zur Modelloptimierung. Sie können Python verwenden, um diese großen Werkzeuge nahtlos in Python mit IronPDF zu verknüpfen und die reichhaltigen Erkenntnisse, die aus XGBoost gewonnen werden, in hochdetaillierte PDF-Berichte zu verwandeln.
Diese Integrationen werden somit die Erstellung attraktiver und informationsreicher Dokumente in Bezug auf die Ergebnisse erheblich erleichtern, wodurch sie kommunizierbar für die Stakeholder oder geeignet für weitere Analysen werden. Geschäftsanalysen, akademische Forschung oder jedes datengetriebene Projekt wären nicht möglich gewesen ohne eine eingebaute Synergie zwischen XGBoost und IronPDF, um Daten effizient zu verarbeiten und die Ergebnisse mühelos zu kommunizieren.
IntegrierenIronPDF undIronSoftwareProdukte, um sicherzustellen, dass Ihre Kunden und Endbenutzer funktionsreiche, hochwertige Softwarelösungen erhalten. Dies wird auch dazu beitragen, Ihre Projekte und Prozesse zu optimieren.
Umfassende Dokumentation, aktive Community und häufige Updates—alles geht Hand in Hand mit der Funktionalität von IronPDF. Iron Software ist der Name eines vertrauenswürdigen Partners für moderne Softwareentwicklungsprojekte. IronPDF steht allen Entwicklern für eine kostenlose Testversion zur Verfügung. Sie können alle Funktionen ausprobieren. Lizenzgebühren in Höhe von 749 $ sind verfügbar, um den größtmöglichen Nutzen aus diesem Produkt zu ziehen.

pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente