Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


Python ist weithin für seine Einfachheit und Lesbarkeit bekannt, was es zu einer beliebten Wahl unter Entwicklern für Web Scraping und die Interaktion mit APIs macht. Eine der wichtigsten Bibliotheken, die solche Interaktionen ermöglichen, ist die Python-Bibliothek "Requests". requests" ist eine HTTP-Anforderungsbibliothek für Python, die es ermöglicht, HTTP-Anforderungen auf einfache Weise zu senden. In diesem Artikel werden wir uns mit den Funktionen der Python-Bibliothek Requests befassen, ihre Verwendung anhand von praktischen Beispielen untersuchen und IronPDF vorstellen und zeigen, wie es mit Requests kombiniert werden kann, um PDFs aus Webdaten zu erstellen und zu bearbeiten.
Requests-BibliothekDie Python-Bibliothek Requests wurde entwickelt, um HTTP-Anfragen einfacher und menschenfreundlicher zu gestalten. Es abstrahiert die Komplexität von Anfragen hinter einer einfachen API, so dass Sie sich auf die Interaktion mit Diensten und Daten im Web konzentrieren können. Egal, ob Sie Webseiten abrufen, mit REST-APIs interagieren, die Überprüfung von SSL-Zertifikaten deaktivieren oder Daten an einen Server senden müssen, die Bibliothek Requests ist für Sie da.
Einfachheit: Einfach zu verwendende und verständliche Syntax.
HTTP-Methoden: Unterstützt alle HTTP-Methoden - GET, POST, PUT, DELETE, etc.
Session-Objekte: Behält Cookies über Anfragen hinweg bei.
Authentifizierung: Vereinfacht das Hinzufügen von Authentifizierungs-Headern.
Proxies: Unterstützung für HTTP-Proxys.
Zeitüberschreitungen: Effiziente Verwaltung von Anfrage-Timeouts.
RequestsUm Requests verwenden zu können, müssen Sie es installieren. Dies kann mit pip durchgeführt werden:
pip install requestsHier ist ein einfaches Beispiel für die Verwendung von Requests zum Abrufen einer Webseite:
import requests
# response object
response = requests.get('https://www.example.com')
print(response.status_code) # 200 status code
print(response.text) # The HTML content of the page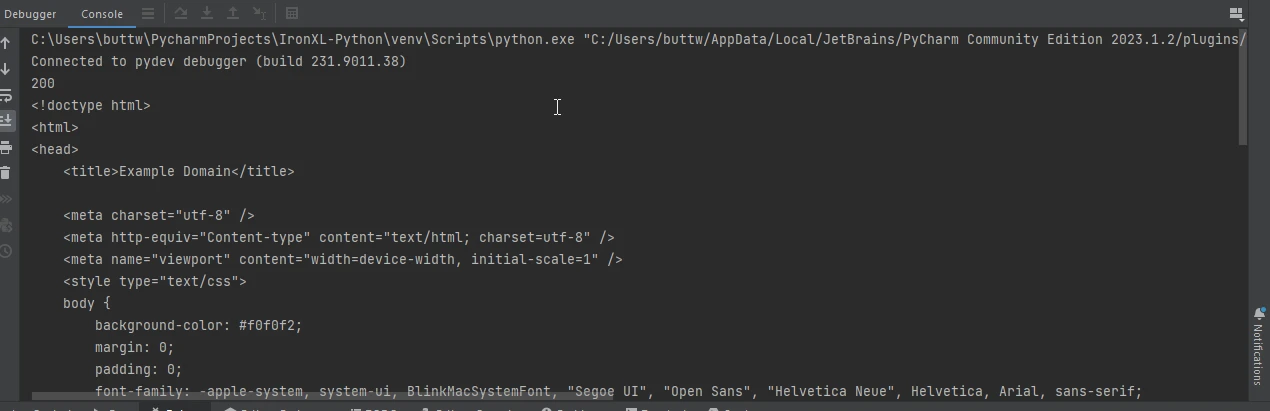
Oft müssen Sie Parameter an die URL übergeben. Das Python-Modul Requests macht dies mit dem Schlüsselwort params einfach:
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://www.example.com', params=params)
print(response.url) # https://www.example.com?key1=value1&key2=value2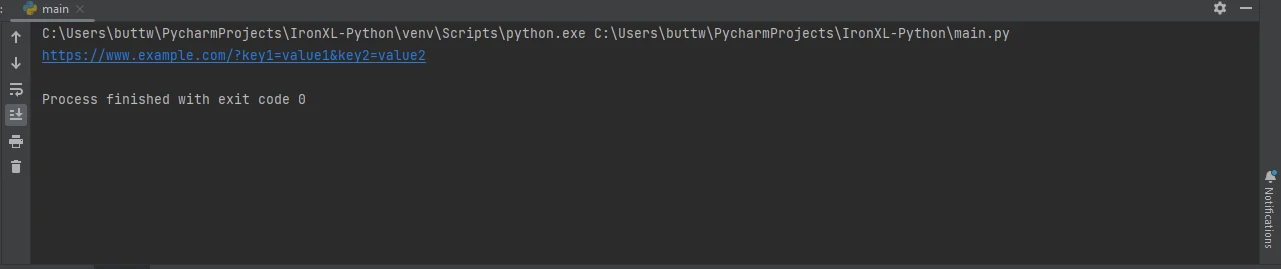
Die Interaktion mit APIs umfasst in der Regel JSON-Daten. anfragen" vereinfacht dies mit eingebauter JSON-Unterstützung:
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
data = response.json()
print(data)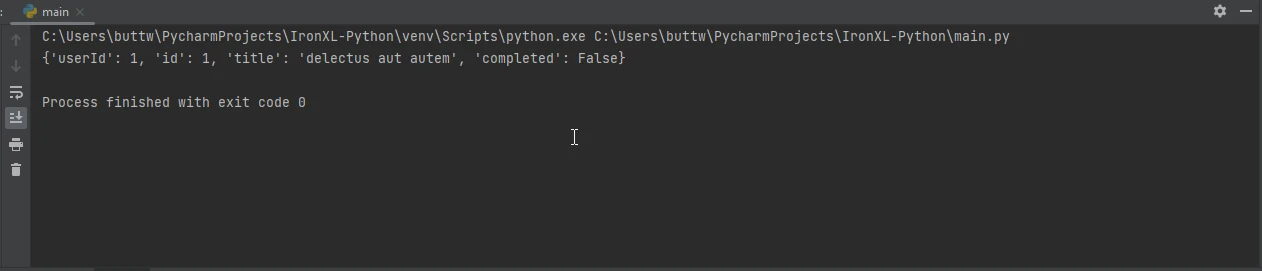
Header sind entscheidend für HTTP-Anfragen. Sie können Ihren Anfragen eine benutzerdefinierte Kopfzeile wie folgt hinzufügen:
headers = {'User-Agent': 'my-app/0.0.1'} # user agent header
response = requests.get('https://www.example.com', headers=headers)
print(response.text)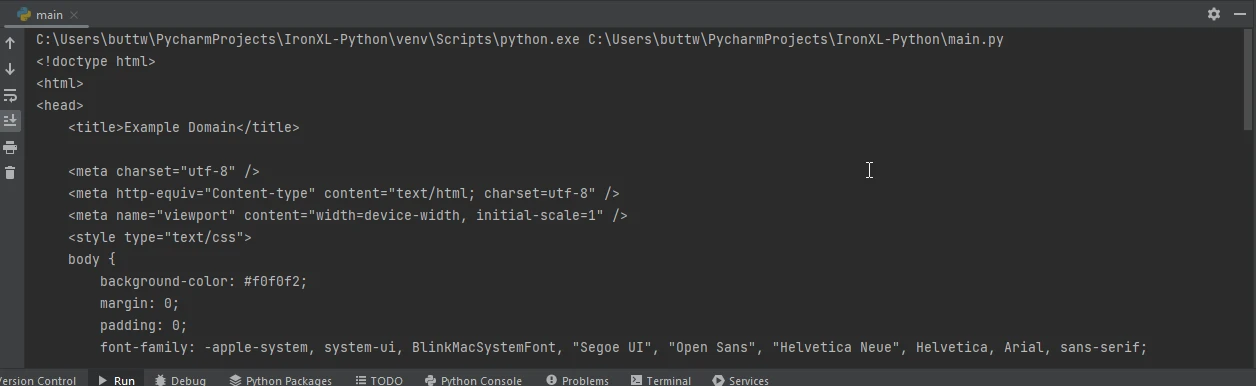
die Funktion "Anfragen" unterstützt auch das Hochladen von Dateien. Hier erfahren Sie, wie Sie eine Datei hochladen können:
files = {'file': open('report.txt', 'rb')}
response = requests.post('https://www.example.com/upload', files=files) # post request
print(response.status_code)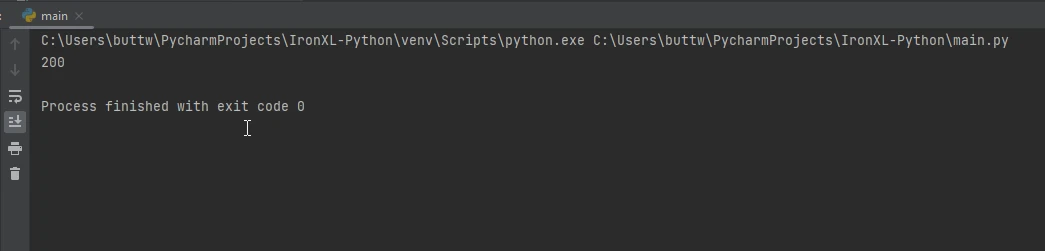
IronPDF ist eine vielseitige Bibliothek zur PDF-Erzeugung, mit der Sie PDFs in Ihren Python-Anwendungen erstellen, bearbeiten und manipulieren können. Es ist besonders nützlich, wenn Sie PDFs aus HTML-Inhalten generieren müssen, was es zu einem großartigen Werkzeug für die Erstellung von Berichten, Rechnungen oder jeder anderen Art von Dokument macht, das in einem portablen Format verteilt werden muss.
Um IronPDF zu installieren, verwenden Sie pip:
pip install ironpdf
RequestsDurch die Kombination von Requests und IronPDF können Sie Daten aus dem Internet abrufen und direkt in PDF-Dokumente umwandeln. Dies kann besonders nützlich sein, um Berichte aus Webdaten zu erstellen oder Webseiten als PDF zu speichern.
Hier ein Beispiel für die Verwendung von Requests, um eine Webseite abzurufen und sie dann mit IronPDF als PDF zu speichern:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Create a PDF from the HTML content
html_content = response.text
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the PDF to a file
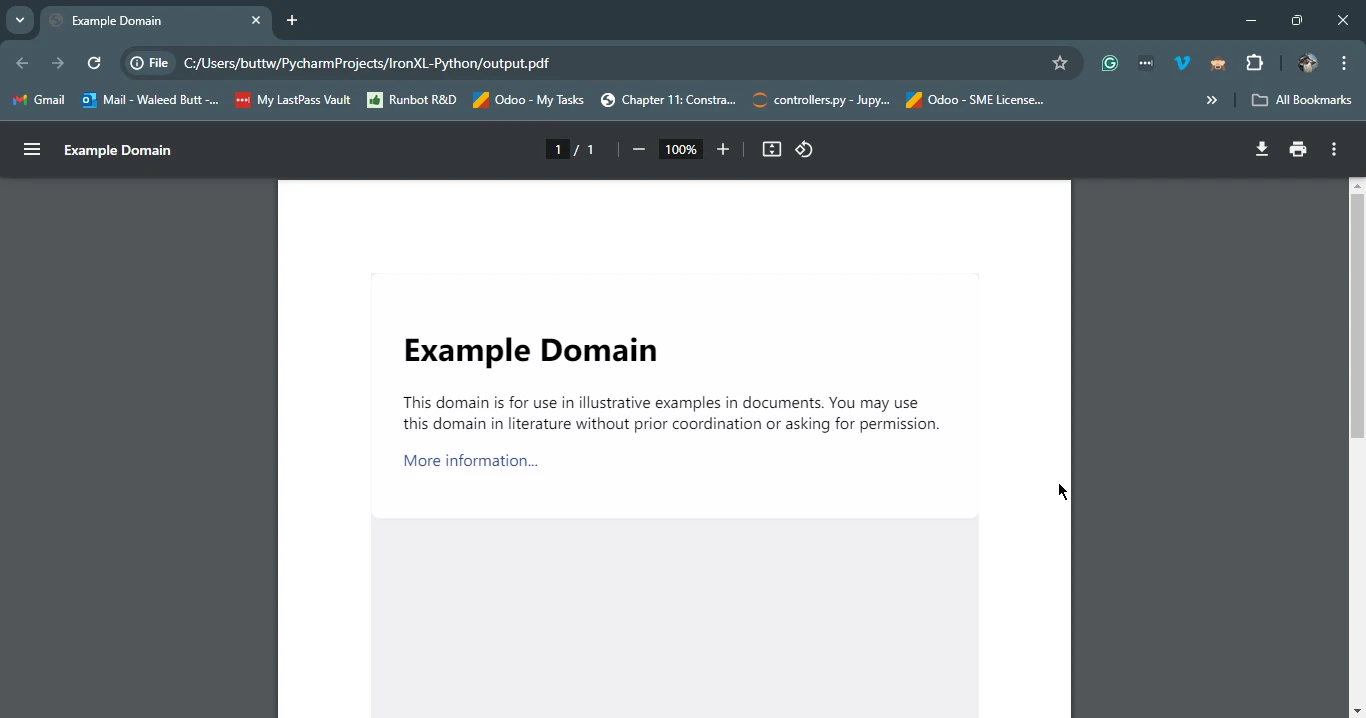
pdf.save('output.pdf')
print('PDF created successfully')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')Dieses Skript holt zunächst den HTML-Inhalt der angegebenen URL mit Hilfe von Requests. Anschließend wird der HTML-Inhalt dieses Antwortobjekts mit IronPDF in ein PDF-Dokument umgewandelt und das Ergebnis in einer Datei gespeichert.
Die Bibliothek Requests ist ein unverzichtbares Werkzeug für jeden Python-Entwickler, der mit Web-APIs interagieren muss. Ihre Einfachheit und Benutzerfreundlichkeit machen sie zur ersten Wahl bei der Erstellung von HTTP-Anfragen. In Kombination mit IronPDF eröffnen sich noch mehr Möglichkeiten: Sie können Daten aus dem Internet abrufen und in professionelle PDF-Dokumente umwandeln. Ganz gleich, ob Sie Berichte, Rechnungen oder Web-Inhalte erstellen, die Kombination von Requests und IronPDF bietet eine leistungsstarke Lösung für Ihre Anforderungen bei der PDF-Erstellung.
Weitere Informationen zur IronPDF-Lizenzierung finden Sie auf der IronPDF-Lizenzseite. Weitere Informationen finden Sie auch in unserem ausführlichen Tutorial zur HTML-zu-PDF-Konvertierung.

pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente