Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Python PDF-Bibliothek


Die Arbeit mit PDF-Dateien in Python ist eine unverzichtbare Fähigkeit für Entwickler, die CLI-Anwendungen erstellen.(s)und Datenverarbeitungssysteme. Ob Sie Text aus Dokumenten extrahieren, Text und Tabellen aus komplexen Layouts abrufen oder benutzerdefinierte Daten zu bestehenden hinzufügen müssen,PDFs, die richtige Python-Bibliothek auszuwählen, ist entscheidend.
Die Python-PDF-Dateibibliothek hilft Entwicklern, HTML-Strings in PDF zu konvertieren, benutzerdefinierte Daten zu verarbeiten oder hinzuzufügen und erweiterte Operationen wie das Extrahieren von Tabellen und Text mit unterschiedlichen Genauigkeitsgraden durchzuführen. Dieser umfassende Leitfaden untersucht fünf beliebte Bibliotheksoptionen, darunterIronPDF, jeweils mit unterschiedlichen Fähigkeiten und Anwendungsbereichen, um Ihnen bei der Auswahl der am besten geeigneten Lösung für Ihre PDF-Ansprüche zu helfen.
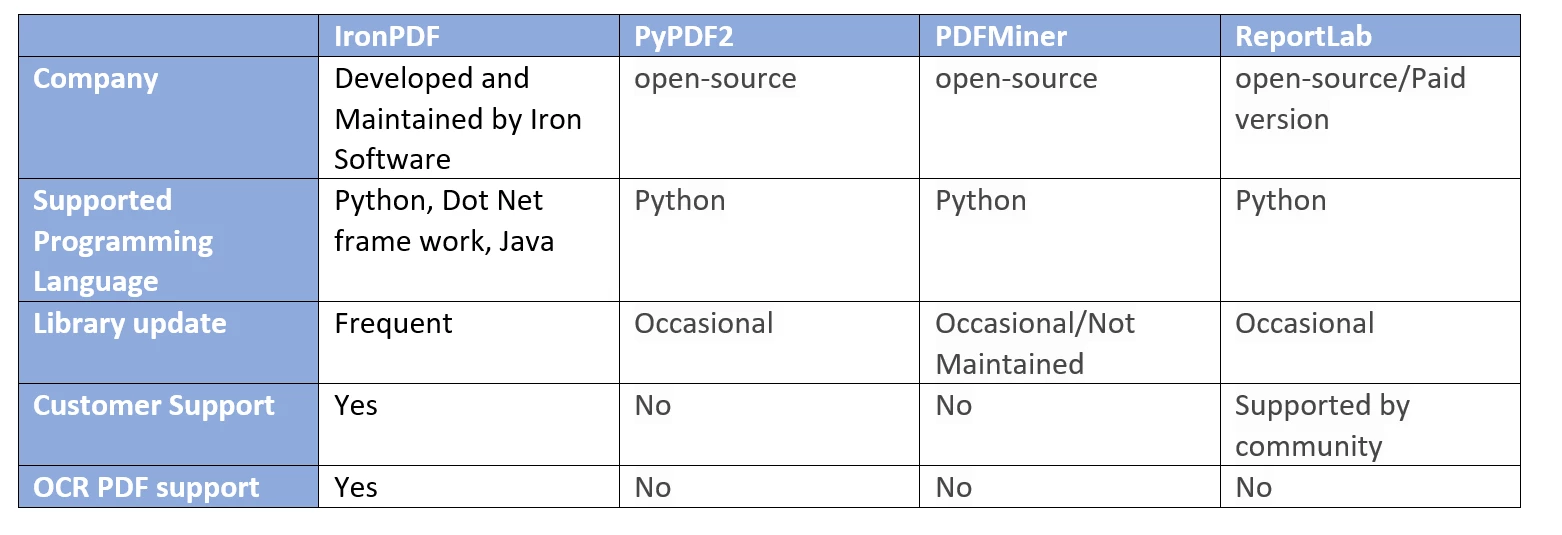
IronPDF ist eine leistungsstarke PDF-Verarbeitungslösung für Python-Entwickler. Basierend auf der leistungsstarken Chromium-Engine, glänzt es bei der KonvertierungHTML zu PDFmit außergewöhnlicher Genauigkeit und Formatierungserhaltung. Es kann HTML-Strings und Dateien in PDF konvertieren. Sie können es auch zum Extrahieren von Text aus PDF-Dateien verwenden. Die Bibliothek wurde speziell für Entwickler entwickelt, die professionelle PDF-Verarbeitungsfähigkeiten in Produktionsumgebungen benötigen.
Es bietet nahtlose Integration in bestehende Python-Anwendungen und unterstützt sowohl synchrone als auch asynchrone Operationen. Was IronPDF auszeichnet, ist seine Fähigkeit, komplexe Layouts, dynamische Inhalte und moderne Webtechnologien wie CSS3 und JavaScript zu verarbeiten. Die Bibliothek umfasst integrierte Unterstützung für Kopfzeilen, Fußzeilen, Seitennummerierung und Wasserzeichen. Es eignet sich am besten für die Erstellung von Geschäftsdokumenten, Berichten, Rechnungen und vielen anderen PDF-bezogenen Vorgängen.
ReportLabhat sich in den letzten zwei Jahrzehnten als De-facto-Standard für die PDF-Erstellung in Python etabliert. Es ist die Engine hinter der PDF-Exportfunktion von Wikipedia und wird von zahlreichen Fortune-500-Unternehmen genutzt. Die Bibliothek bietet zwei verschiedene Versionen an: eine kommerzielle Ausgabe(ReportLab PLUS)und ein Open-Source-Toolkit.
Im Kern bietet ReportLab eine robuste Seiten-Layout-Engine und eine leistungsstarke Grafik-Canvas-API. Die Bibliothek zeichnet sich durch die programmatische Erstellung komplexer Dokumente aus, insbesondere bei solchen, die eine präzise Steuerung von Layout und Design erfordern. Es umfasst Funktionen wie Flowables(Elemente, die über Seiten hinweg fließen können), Tabellen, Diagramme und Vektorgrafiken. Die Architektur von ReportLab ist so konzipiert, dass sie sowohl kleine Dokumente als auch die großangelegte Stapelverarbeitung von Tausenden personalisierter Dokumente bewältigen kann.
PyPDF2(und dessen ForkPyPDF4)ist eine reine Python-PDF-Bibliothek im Python-Ökosystem. Ursprünglich als Abspaltung von pypdf entwickelt, hat es sich zu einer stabilen, zuverlässigen Lösung für grundlegende PDF-Operationen entwickelt. Die Bibliothek ist vollständig in Python geschrieben. Es ist auf die Manipulation von PDFs statt auf deren Erstellung ausgerichtet. Es ist effektiv für Aufgaben wie das Zusammenführen, Aufteilen und Transformieren bestehender PDF-Dokumente.
Es umfasst umfassende Unterstützung für verschlüsselte PDFs und kann sowohl das Lesen als auch das Schreiben von PDF-Metadaten behandeln. Die Architektur von PyPDF2 ist modular, und sie ermöglicht es Entwicklern, mit PDF-Komponenten auf verschiedenen Abstraktionsebenen zu arbeiten. Sie können es mit diesem Befehl installieren:
pip install pypdf
PyFPDFist ein Python-Port der beliebten PHP-PDF-Bibliothek mit dem gleichen Namen. Es bietet einen einfachen Ansatz zur PDF-Erstellung, der auf Einfachheit und Benutzerfreundlichkeit abzielt. Die Bibliothek wurde mit der Philosophie entwickelt, die PDF-Erstellung so einfach wie das Schreiben von einfachen Textdateien zu gestalten. Es übernimmt alle Low-Level-PDF-Operationen und bietet gleichzeitig eine High-Level-Schnittstelle für gängige Aufgaben. PyFPDF umfasst integrierte Unterstützung für mehrere Schriftarten, einschließlich TrueType und Type1, und kann Schriftarten direkt in PDF-Dokumente einbetten. Die Bibliothek bietet auch grundlegende HTML-Unterstützung durch ihre HTMLMixin-Klasse.
PyMuPDF, auch bekannt als Fitz, ist eine leistungsstarke Python-Bindung für die MuPDF-Bibliothek. Es zeichnet sich durch seine Vielseitigkeit bei der Verarbeitung mehrerer Dokumentformate aus, die über PDFs hinausgehen, darunter XPS, EPUB und verschiedene Bildformate. PyMuPDF bietet umfassende Dokumentenbearbeitungsfunktionen, einschließlich fortschrittlicher Textextraktion mit präzisen Positionsinformationen, Bildextraktion und -einfügung sowie Anmerkungsverwaltung. Die Architektur der Bibliothek ist so konzipiert, dass sie sowohl High-Level-Komfortfunktionen als auch bei Bedarf Low-Level-Zugriff auf PDF-Strukturen bietet.
| Funktion | IronPDF | ReportLab | PyPDF2 | FPDF | PyMuPDF |
| PDF-Erstellung | ✓ | ✓ | Begrenzt | ✓ | ✓ |
| Textextraktion | Fortgeschrittene | Grundlegend | Grundlegend | Nein | Fortgeschrittene |
| Ausfüllen von Formularen | ✓ | ✓ | Begrenzt | Nein | ✓ |
| HTML-Unterstützung | Fortgeschrittene | Grundlegend | Nein | Begrenzt | Grundlegend |
| Bildverarbeitung | ✓ | ✓ | Begrenzt | ✓ | ✓ |
| Abhängigkeiten | .NET | Minimal | Keine | Keine | C-Bibliotheken |
| Lizenz | Kommerziell | Dual | MIT | LGPL | GPL/Kommerziell |
Nach der Analyse dieser Python-PDF-Bibliotheken erweist sich IronPDF als umfassende Lösung für professionelle PDF-Entwicklungsanforderungen. Während jede Bibliothek ihre Stärken hat, macht die Kombination aus Funktionen, Leistung und Enterprise-Grade-Fähigkeiten von IronPDF sie geeignet für Produktionsumgebungen. Die auf Chromium basierende Engine der Bibliothek gewährleistet eine überlegene Genauigkeit bei der HTML-zu-PDF-Konvertierung, während ihre umfangreiche API Entwicklern Werkzeuge für komplexe PDF-Manipulationen bietet.
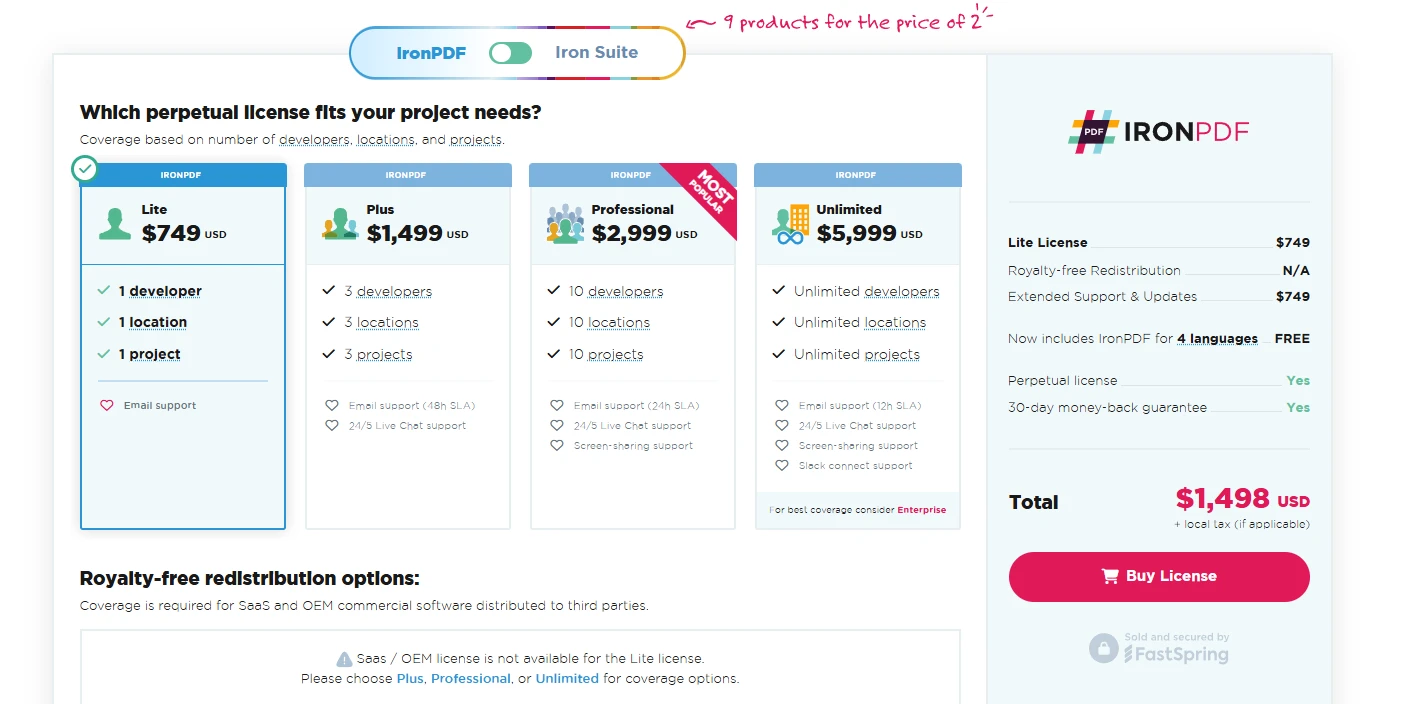
Für Unternehmen, die zuverlässige PDF-Verarbeitungsfunktionen benötigen, rechtfertigen das umfangreiche Funktionsset und der professionelle Support von IronPDF die kommerzielle Investition. IronPDF bietet einekostenloser Test. Die kommerzielle Lizenz beginnt bei $749 pro Entwickler, einschließlich umfassendem Support und regelmäßigen Updates. IronPDF bietet die Zuverlässigkeit, Funktionen und Unterstützung, die erforderlich sind, um Lösungen in professioneller Qualität zu liefern. Während es kostenlose Alternativen gibt, machen die vollständigen Funktionen und die unternehmensfertigen Fähigkeiten von IronPDF es zu einer besseren Wahl.
Berücksichtigen Sie diese Schlüsselfaktoren bei der Auswahl:
Langfristige Wartungsüberlegungen
Egal, ob Sie ein Dokumentenmanagementsystem erstellen, Berichte generieren oder Formulare verarbeiten, IronPDF bietet die Werkzeuge und die Stabilität, die für eine erfolgreiche Implementierung erforderlich sind.

pip install produkt-Name-produkt-version-py37-none-win_amd64.whiKeine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente