
Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Java PDF-Bibliothek


In diesem Artikel wird demonstriert, wie PDF-Dateien in Java unter Verwendung der PDF-Bibliothek für das Java-Demoprojekt mit dem NamenIronPDF for Java Library Übersichtdie Aufgabe besteht darin, Text und metadatenartige Objekte in PDF-Dateien zu lesen und verschlüsselte Dokumente zu erstellen.
Installieren Sie die PDF-Bibliothek, um PDF-Dateien mit Java zu lesen.
Importieren Sie die Abhängigkeiten, um das PDF-Dokument im Projekt zu verwenden.
Laden Sie eine vorhandene PDF-Datei mitdokumentation der Methode PdfDocument.fromFile.
Extrahieren Sie den Text in der PDF-Datei mit dem[Erklärung der PDF-Textextraktionsmethode](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()) methode.
Erstellen Sie das Metadata-Objekt mit dem[Tutorial zum Abrufen von PDF-Metadaten](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata()) methode.
Um den Prozess des Lesens von PDF-Dateien in Java zu rationalisieren, greifen Entwickler häufig auf Bibliotheken von Drittanbietern zurück, die umfassende und effiziente Lösungen bieten. Eine dieser herausragenden Bibliotheken ist IronPDF for Java.
IronPDF ist entwicklerfreundlich und bietet eine unkomplizierte API, die die Komplexität der PDF-Seitenmanipulation abstrahiert. Mit IronPDF können Java-Entwickler PDF-Lesefunktionen nahtlos in ihre Projekte integrieren und so Entwicklungszeit und -aufwand reduzieren. Diese Bibliothek unterstützt eine breite Palette von PDF-Funktionen und ist damit eine vielseitige Wahl für verschiedene Anwendungsfälle.
Die Hauptfunktionen umfassen die Fähigkeit zueine PDF-Datei aus verschiedenen Formaten erstellen dazu gehören HTML, JavaScript, CSS, XML-Dokumente und verschiedene Bildformate. Darüber hinaus bietet IronPDF die Möglichkeit zuhinzufügen von Kopf- und Fußzeilen zu PDFs, tabellen in PDF-Dokumenten erstellenund vieles mehr.
Um IronPDF einzurichten, stellen Sie sicher, dass Sie über einen zuverlässigen Java-Compiler verfügen. Dieser Artikel empfiehlt die Nutzung von IntelliJ IDEA.
Starten Sie IntelliJ IDEA und legen Sie ein neues Maven-Projekt an.
pom.xml zu. Fügen Sie die folgenden Maven-Abhängigkeiten ein, um IronPDF zu integrieren: :ProductInstallLassen Sie uns ein einfaches Java-Codebeispiel untersuchen, das zeigt, wie man IronPDF verwendet, um den Inhalt einer PDF-Datei zu lesen. In diesem Beispiel konzentrieren wir uns auf die Methode zur Textextraktion aus einem PDF-Dokument.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}Dieser Java-Code nutzt die IronPDF-Bibliothek, um Text aus einer bestimmten PDF-Datei zu extrahieren. Er wird die Java-Bibliothek importieren und den Lizenzschlüssel setzen, eine Voraussetzung für die Nutzung der Bibliothek. Der Code lädt dann ein PDF-Dokument aus der Datei "html_file_saved.pdf" und extrahiert den gesamten Textinhalt der Datei als internen String-Puffer. Der extrahierte Text wird in einer Variablen gespeichert und anschließend auf der Konsole ausgegeben.
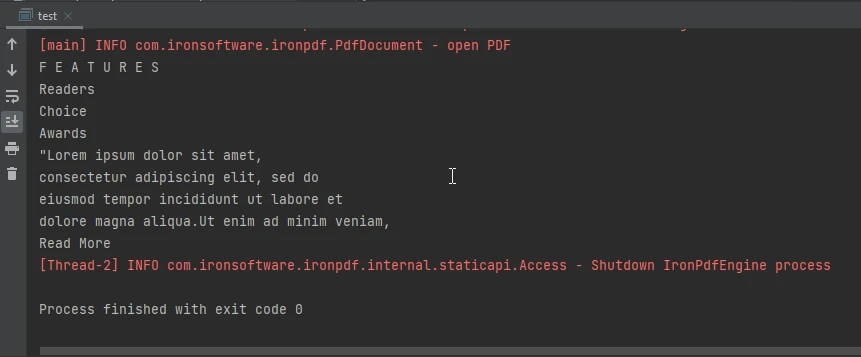
Die Konsolenausgabe
IronPDF erweitert seine Fähigkeiten über die Textextraktion hinaus und unterstützt nun auch die Extraktion von Metadaten aus PDF-Dateien. Zur Veranschaulichung dieser Funktionalität wollen wir uns ein Java-Codebeispiel ansehen, das den Prozess des Abrufs von Metadaten aus einem PDF-Dokument veranschaulicht.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}Dieser Java-Code nutzt die IronPDF-Bibliothek, um Metadaten, insbesondere die Autoreninformationen, aus einem PDF-Dokument zu extrahieren. Es beginnt damit, ein PDF-Dokument aus der Datei "html_file_saved.pdf" zu laden. Der Code ruft die Metadaten des Dokuments ab, indem er dieDokumentation der Klasse MetadataManagerdas Ziel ist es, die Informationen über den Autor abzurufen. Die extrahierten Autorendaten werden in einer Variablen gespeichert und auf der Konsole ausgegeben.
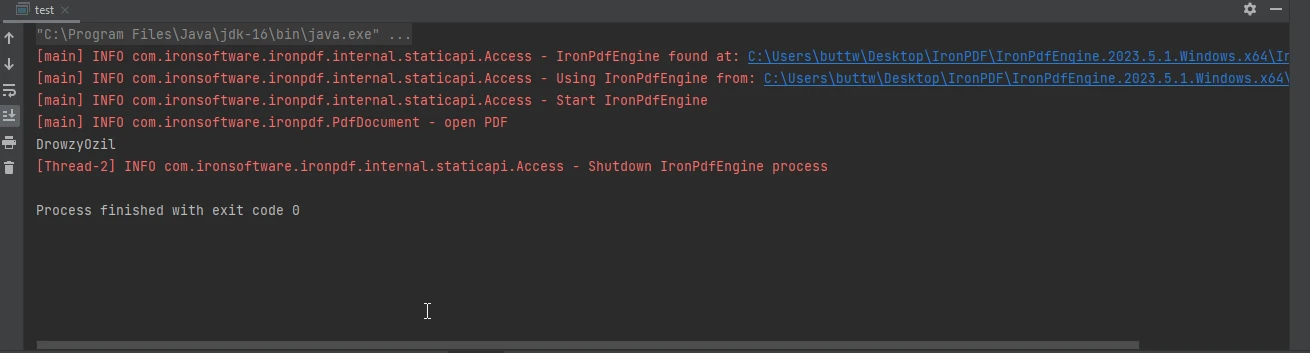
Die Konsolenausgabe
Abschließend ist das Lesen eines vorhandenen PDF-Dokuments in einem Java-Programm eine wertvolle Fähigkeit, die Entwicklern eine Vielzahl von Möglichkeiten eröffnet. Ob es um die Extraktion von Text, Bildern oder anderen Daten geht, die Möglichkeit, PDFs programmatisch zu bearbeiten, ist ein wichtiger Aspekt vieler Anwendungen. IronPDF for Java ist eine robuste und effiziente Lösung für Entwickler, die PDF-Lesefunktionen in ihre Java-Projekte integrieren möchten.
Durch Befolgen der Installationsschritte und Erforschen der bereitgestellten Codebeispiele können Entwickler die Leistungsfähigkeit von IronPDF schnell nutzen, um neue Dateien zu erstellen und PDF-bezogene Aufgaben mühelos zu erledigen. Darüber hinaus kann man auch seine Fähigkeiten zur Erstellung verschlüsselter Dokumente weiter erforschen.
IronPDF-Produktportal bietet umfassende Unterstützung für seine Entwickler. Um mehr darüber zu erfahren, wie IronPDF for Java funktioniert, besuchen Sie diese umfassende Dokumentationsseiten. Außerdem bietet IronPDF eineseite mit dem Angebot einer kostenlosen Testlizenz das ist eine gute Gelegenheit, IronPDF und seine Funktionen kennenzulernen.
Darrius Serrant hat einen Bachelor-Abschluss in Informatik von der University of Miami und arbeitet als Full Stack WebOps Marketing Engineer bei Iron Software. Schon in jungen Jahren vom Programmieren angezogen, sah er das Rechnen sowohl als mysteriös als auch zugänglich an, was es zum perfekten Medium für Kreativität und Problemlösung machte.
Bei Iron Software genießt Darrius es, neue Dinge zu erschaffen und komplexe Konzepte zu vereinfachen, um sie verständlicher zu machen. Als einer unserer ansässigen Entwickler hat er sich auch freiwillig gemeldet, um Schüler zu unterrichten und sein Fachwissen mit der nächsten Generation zu teilen.
Für Darrius ist seine Arbeit erfüllend, weil sie geschätzt wird und einen echten Einfluss hat.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente