
Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Java PDF-Bibliothek


Dieses Tutorial zeigt Ihnen, wie Sie verwendenIronPDF for Javaum Daten aus einer PDF-Datei zu extrahieren. Das Einrichten der Umgebung, das Importieren der Bibliothek, das Lesen der Eingabedatei und das Extrahieren der benötigten Daten werden alle mit Codebeispielen erklärt.
IronPDF ist eine Softwarebibliothek, die Entwicklern die Möglichkeit bietet, PDFs zu erzeugen, zu bearbeiten undextrahieren von Daten aus PDF-Dateien mit IronPDF for Javainnerhalb ihrer Java-Anwendungen. Sie ermöglicht es IhnenpDFs aus HTML-Dokumenten erstellen, Bilder und mehr, sowiemehrere PDFs zusammenführen, pDF-Dateien aufteilen, und bestehende PDFs bearbeiten. IronPDF bietet auch die Möglichkeit, PDFs zu sichern mitpasswortschutz-Funktionen undhinzufügen digitaler Signaturen zu PDFs, unter anderem Funktionen.
IronPDF for Java wird von Iron Software entwickelt und gepflegt. Eine der am besten bewerteten Funktionen ist die Extraktion von Text und Daten aus PDF-Dateien sowie aus HTML und URLs.
Um IronPDF zum Extrahieren von Daten aus PDF-Dateien zu verwenden, müssen Sie die folgenden Voraussetzungen erfüllen:
Java-Installation: Vergewissern Sie sich, dass Java auf Ihrem System installiert ist und der Pfad in den Umgebungsvariablen festgelegt ist. Wenn Sie Java noch nicht installiert haben, lesen Sie diesedownload-Seite auf der Java-Website für Anweisungen.
Java IDE: Sie müssen eine Java IDE wie Eclipse oder IntelliJ installiert haben. Sie können Eclipse von dieser Seite herunterladenEclipse Download-Seite und IntelliJ von diesemIntelliJ Download-Seite.
IronPDF-Bibliothek: Laden Sie die IronPDF-Bibliothek herunter und fügen Sie sie als Abhängigkeit zu Ihrem Projekt hinzu. Besuchen Sie dieIronPDF Setup-Anleitung Seite für Anweisungen zur Einrichtung.
Die Installation von IronPDF for Java ist einfach und unkompliziert, sofern alle Voraussetzungen erfüllt sind. In dieser Anleitung wird JetBrains' IntelliJ IDEA verwendet, um die Installation zu demonstrieren und Beispielcode auszuführen.
Das ist zu tun:
Öffnen Sie IntelliJ IDEA: Starten Sie JetBrains IntelliJ IDEA auf Ihrem System.
Erstellen Sie ein Maven-Projekt: Erstellen Sie in IntelliJ IDEA ein neues Maven-Projekt. Dadurch wird eine geeignete Umgebung für die Installation von IronPDF for Java geschaffen.
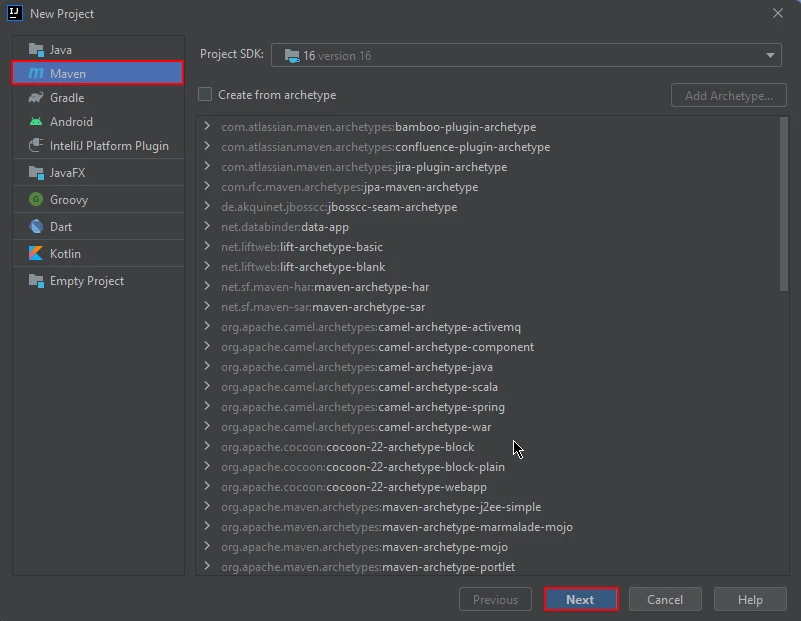
Neues Maven-Projekt in IntelliJ
Es erscheint ein neues Fenster. Geben Sie den Namen des Projekts ein und klicken Sie auf Fertig stellen.
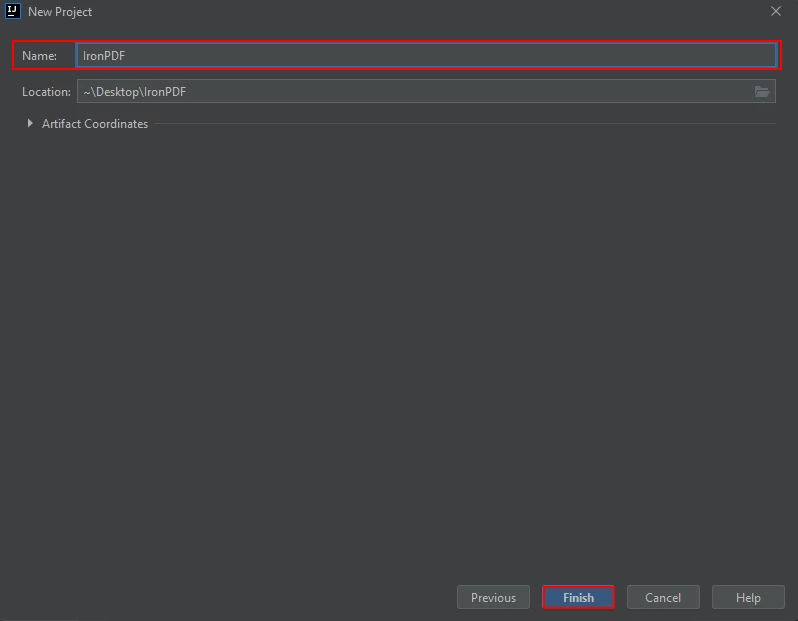
Benennen Sie das Maven-Projekt und klicken Sie auf Fertigstellen
Ein neues Projekt mit einer pom.xml wird geöffnet, sobald Sie auf Fertig stellen klicken. Dies wird verwendet, um IronPDF Java Maven-Abhängigkeiten hinzuzufügen.
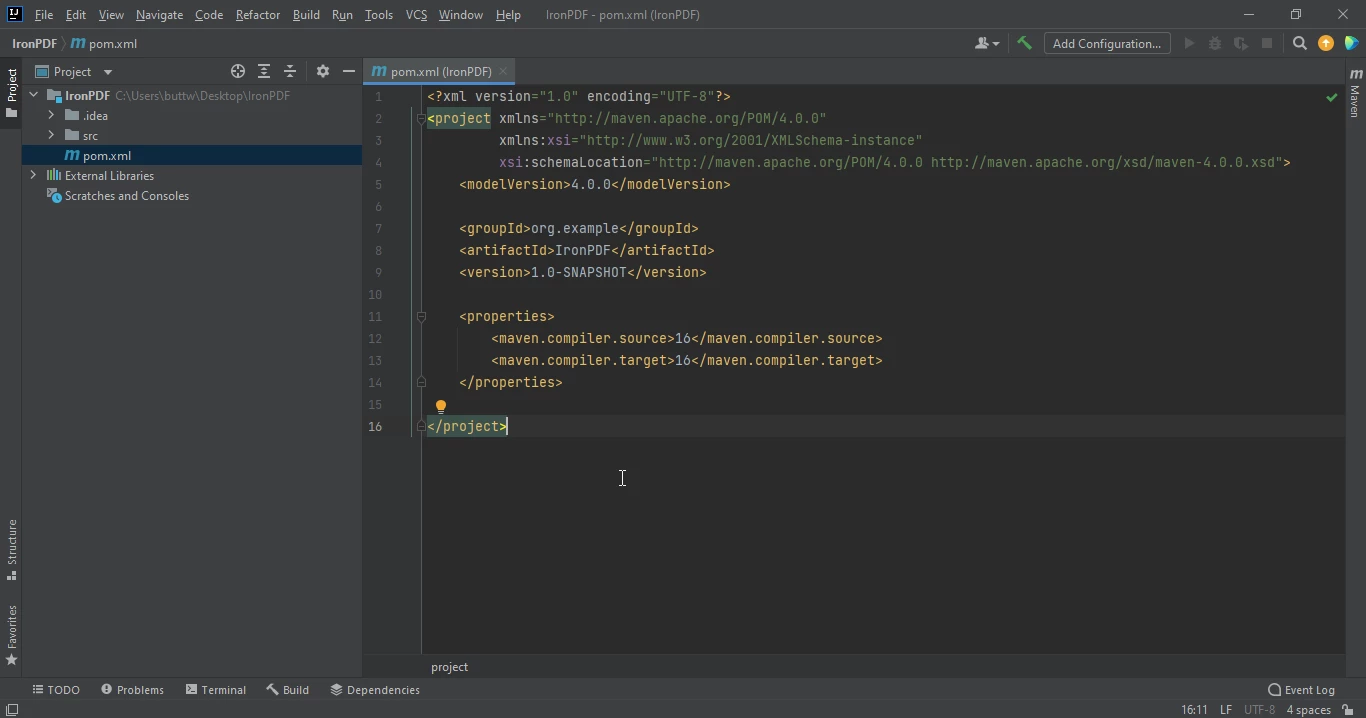
Die pom.xml-Datei
Fügen Sie die folgenden Abhängigkeiten in die Datei pom.xml ein oder laden Sie die JAR-Datei von derIronPDF-Bibliotheksseite auf Sonatype Central.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2025.4.4</version>
</dependency>
Sobald Sie die Abhängigkeiten in die Datei pom.xml eingefügt haben, erscheint ein kleines Symbol in der rechten oberen Ecke der Datei.
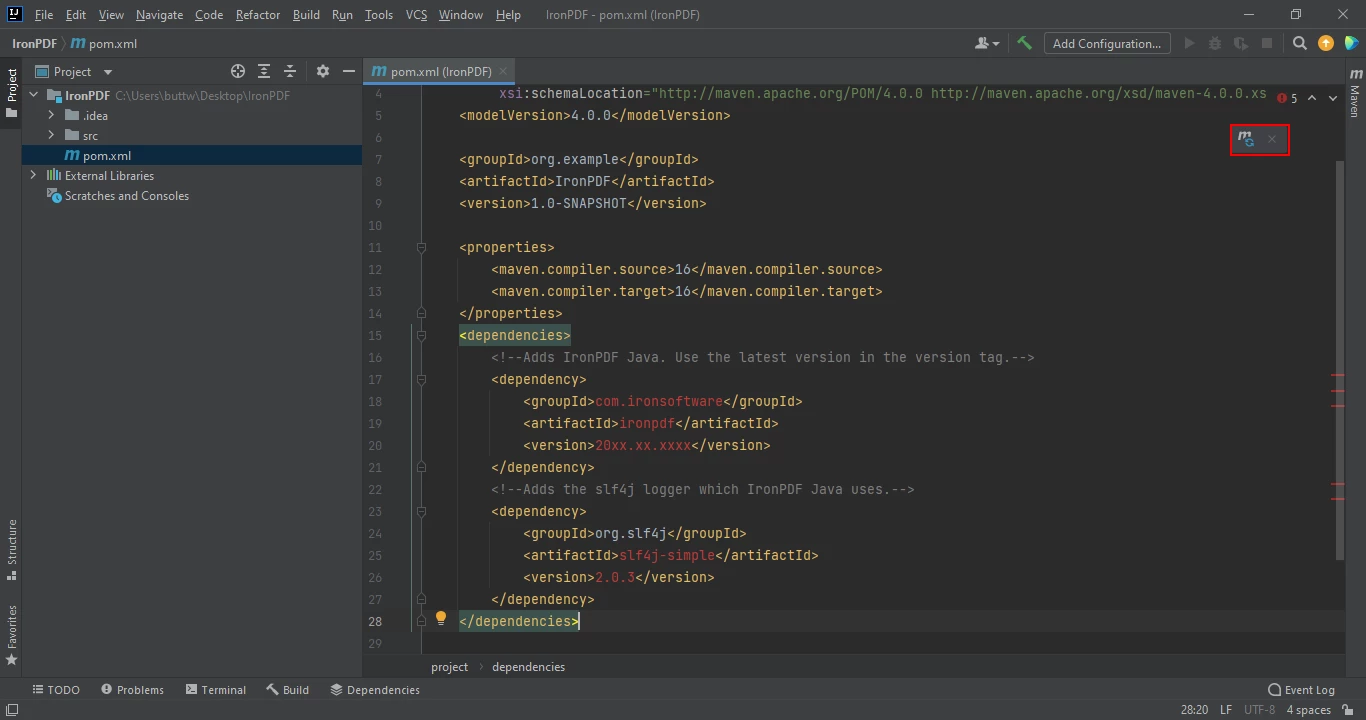
Klicken Sie auf das schwebende Symbol, um die Maven-Abhängigkeiten automatisch zu installieren
Installieren Sie die Maven-Abhängigkeiten von IronPDF for Java, indem Sie auf diese Schaltfläche klicken. Je nach Geschwindigkeit Ihrer Internetverbindung sollte dies nur ein paar Minuten dauern.
IronPDF ist eine Java-Bibliothek zum Erstellen, Bearbeiten und Extrahieren von Daten aus PDF-Dokumenten. Es bietet eine einfache API, um Text aus PDF-Dateien, URLs und Tabellen zu extrahieren.
Mit IronPDF for Java können Sie problemlos Textdaten aus PDF-Dokumenten extrahieren. Nachfolgend finden Sie den Beispielcode für die Extraktion von Daten aus einer PDF-Datei.
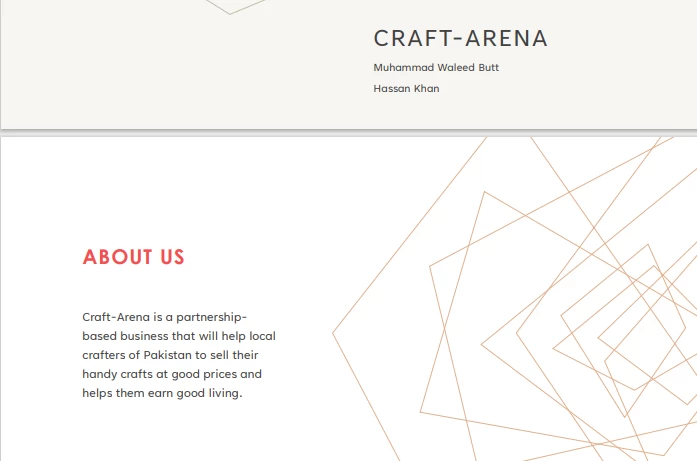
PDF-Eingang
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
String text = pdf.extractAllText();
System.out.println("Text extracted from the PDF: " + text);
}
}Der Quellcode erzeugt die unten angegebene Ausgabe:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnershipbased business that will help local crafters of Pakistan to sell their handy crafts at good prices and helps them earn good living.IronPDF for Java konvertiert die URL zur Laufzeit in PDF und extrahiert den Text daraus. Dieses Beispiel zeigt den Quellcode zum Extrahieren von Text aus URLs.
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// new PDF parser
String text = pdf.extractAllText();
System.out.println("Text extracted from the URLs: " + text);
}
}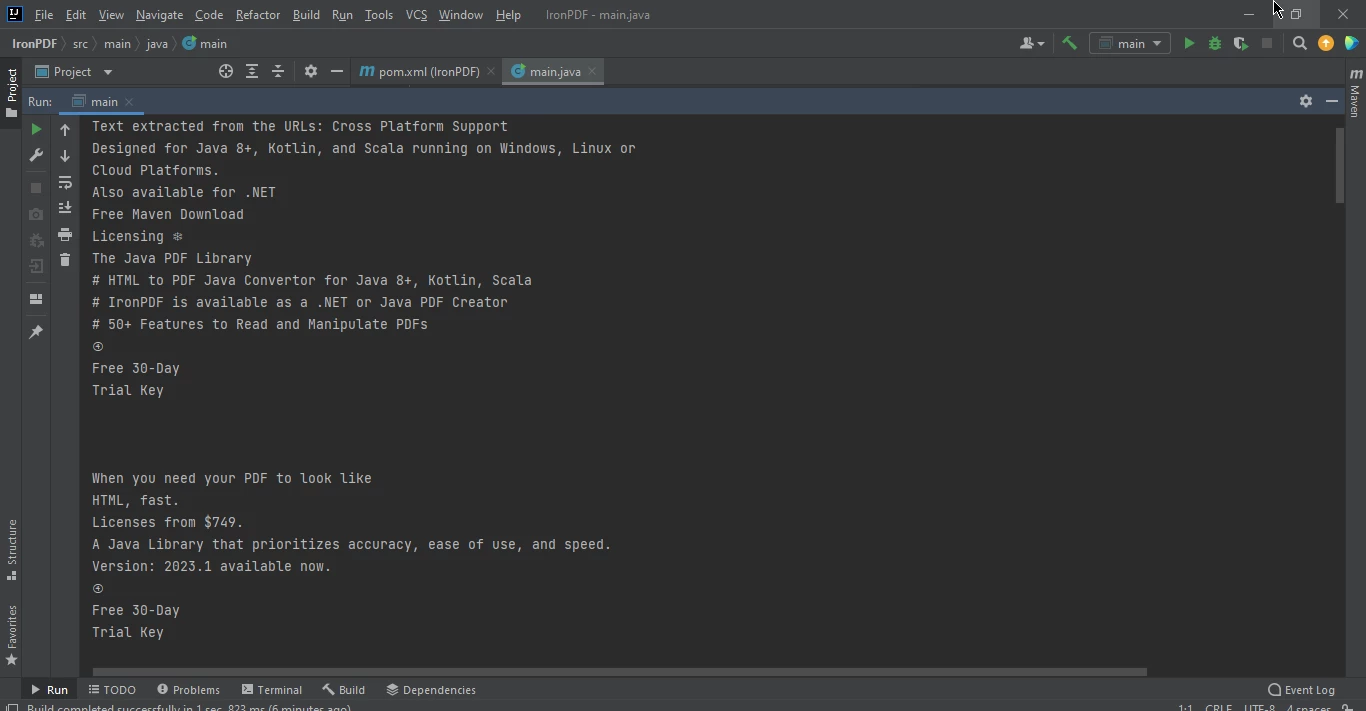
Extrahierte Webseitendaten
Das Extrahieren von Tabellendaten aus einer PDF-Datei mit IronPDF for Java ist sehr einfach; sie benötigen lediglich eine PDF-Datei mit einer Tabelle und müssen den unten stehenden Code ausführen.
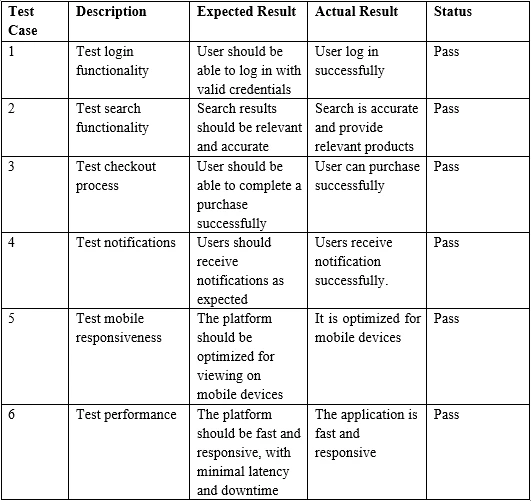
Beispiel-PDF-Tabelleneingabe
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
String text = pdf.extractAllText();
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully PassAbschließend hat dieses Tutorial gezeigt, wie man mit IronPDF for Java Daten, insbesondere Tabellendaten, aus einer PDF-Datei extrahieren kann.
Weitere Informationen finden Sie in dertext aus einem PDF-Beispiel extrahieren auf der IronPDF-Website.
IronPDF ist eine Bibliothek mit einerdetails zur kommerziellen Lizenzbeginnend mit $749. Sie können es jedoch in der Produktion mit einerkostenlose Testversion mit IronPDF-Testlizenz.
Darrius Serrant hat einen Bachelor-Abschluss in Informatik von der University of Miami und arbeitet als Full Stack WebOps Marketing Engineer bei Iron Software. Schon in jungen Jahren vom Programmieren angezogen, sah er das Rechnen sowohl als mysteriös als auch zugänglich an, was es zum perfekten Medium für Kreativität und Problemlösung machte.
Bei Iron Software genießt Darrius es, neue Dinge zu erschaffen und komplexe Konzepte zu vereinfachen, um sie verständlicher zu machen. Als einer unserer ansässigen Entwickler hat er sich auch freiwillig gemeldet, um Schüler zu unterrichten und sein Fachwissen mit der nächsten Generation zu teilen.
Für Darrius ist seine Arbeit erfüllend, weil sie geschätzt wird und einen echten Einfluss hat.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente