
Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die Java PDF-Bibliothek


Dieser Artikel befasst sich mit den folgenden zwei der beliebtesten Bibliotheken, die in Java für die Arbeit mit PDF-Dateien verwendet werden:
IronPDF
Apache PDFBox
Welche Bibliothek sollten wir nun verwenden? In diesem Artikel werde ich die Kernfunktionen beider Bibliotheken vergleichen, damit Sie entscheiden können, welche für Ihre Produktionsumgebung am besten geeignet ist.
PDPageContentStream mit dem Dokument und der Seite als EingabePDPageContentStream-Instanz, um Inhalte zu konfigurieren und hinzuzufügensave-MethodeDie IronPDF-Bibliothek unterstützt die Konvertierung von HTML zu PDF für Java 8+, Kotlin und Scala. Dieser Ersteller bietet plattformübergreifende Unterstützung, d. h. für Windows-, Linux- oder Cloud-Plattformen. Es wurde speziell für Java entwickelt und legt Wert auf Genauigkeit, Benutzerfreundlichkeit und Geschwindigkeit.
IronPDF wurde entwickelt, um Softwareentwickler bei der Erstellung, Bearbeitung und Extraktion von Inhalten aus PDF-Dokumenten zu unterstützen. Sie basiert auf dem Erfolg und der Beliebtheit von IronPDF for .NET.
Zu den herausragenden Merkmalen von IronPDF gehören:
Apache PDFBox ist eine Open-Source-Java-Bibliothek für die Arbeit mit PDF-Dateien. Sie ermöglicht es, bestehende Dokumente zu erstellen, zu bearbeiten und zu manipulieren. Es kann auch Inhalte aus Dateien extrahieren. Die Bibliothek bietet mehrere Dienstprogramme, mit denen verschiedene Operationen an Dokumenten durchgeführt werden können.
Hier sind die herausragenden Merkmale der Apache PDFBox.
Der Rest des Artikels lautet wie folgt:
IronPDF-Installation
Apache PDFBox-Installation
PDF-Dokument erstellen
Bilder zum Dokumentieren
Dokumente verschlüsseln
Lizenzvergabe
Schlussfolgerung
Jetzt werden wir die Bibliotheken herunterladen und installieren, um sie und ihre leistungsstarken Funktionen zu vergleichen.
Die Installation von IronPDF for Java ist einfach. Es gibt verschiedene Wege, dies zu tun. In diesem Abschnitt werden zwei der gängigsten Methoden vorgestellt.
Um die IronPDF JAR-Datei herunterzuladen, besuchen Sie die Maven-Website für IronPDF und laden Sie die neueste Version von IronPDF herunter.
Klicken Sie auf die Option Downloads und laden Sie die JAR-Datei herunter.
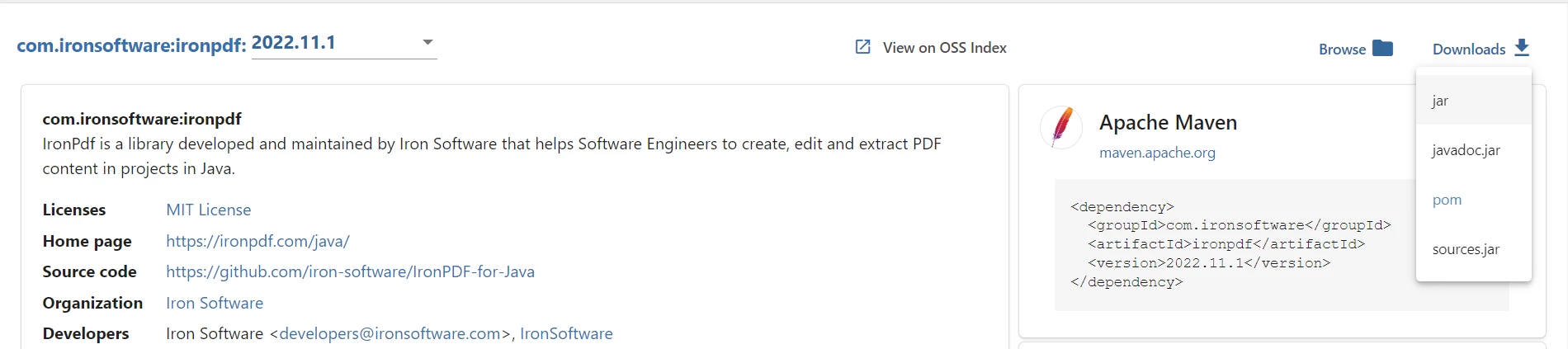
IronPDF JAR herunterladen
Sobald die JAR-Datei heruntergeladen ist, ist es an der Zeit, die Bibliothek in unser Maven-Projekt zu installieren. Sie können jede IDE verwenden, wir werden jedoch NetBeans einsetzen. Im Abschnitt Projekte:
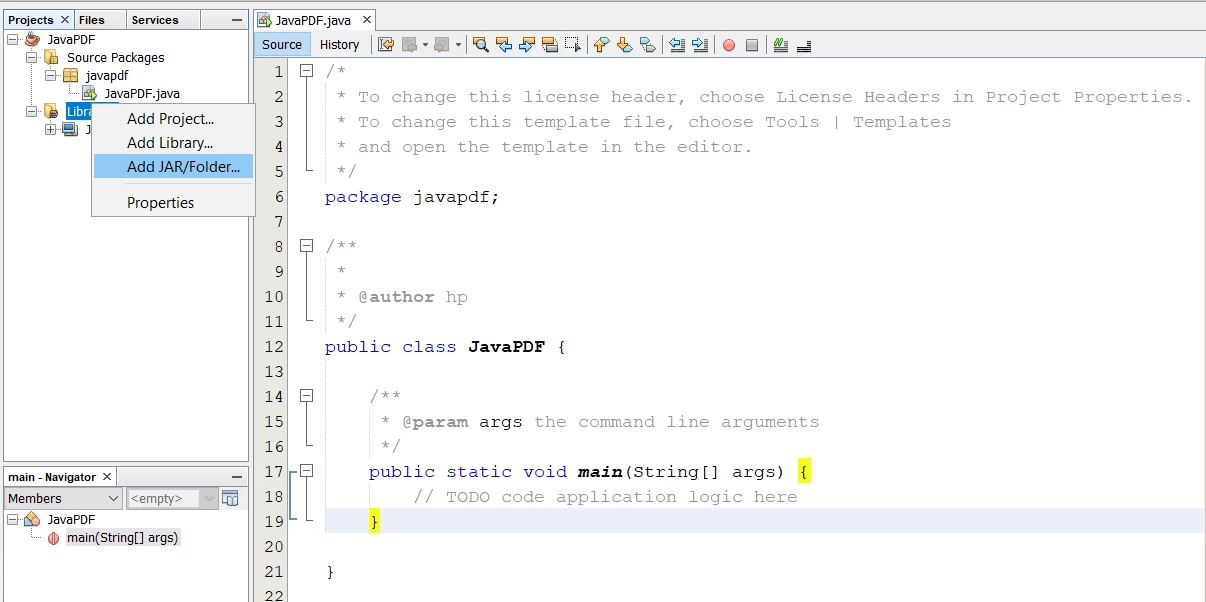
IronPDF-Bibliothek in Netbeans hinzufügen
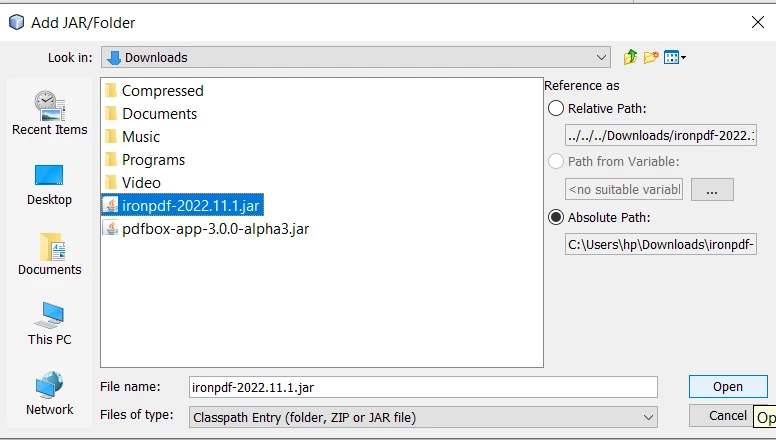
IronPDF JAR öffnen
Eine andere Möglichkeit, IronPDF herunterzuladen und zu installieren, ist die Verwendung von Maven. Sie können die Abhängigkeit einfach in die pom.xml-Datei einfügen oder das Abhängigkeitstool von NetBeans verwenden, um sie in Ihr Projekt einzubinden.
Kopieren Sie den folgenden Code und fügen Sie ihn in die pom.xml ein.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2025.3.6</version>
</dependency>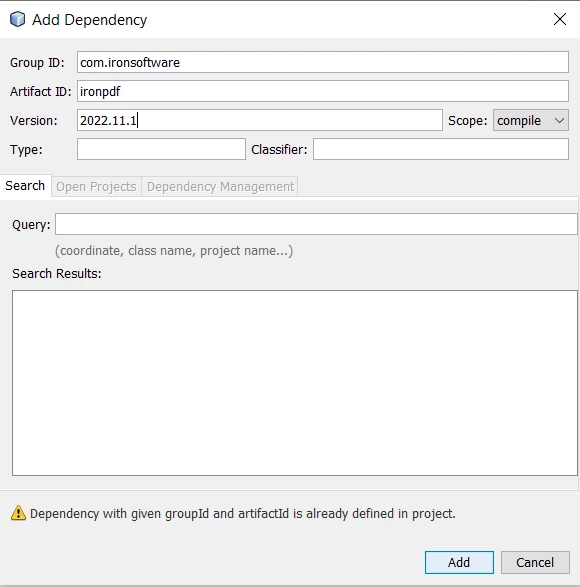
IronPDF-Abhängigkeit hinzufügen
Installieren wir nun Apache PDFBox.
Wir können PDFBox mit denselben Methoden wie IronPDF herunterladen und installieren.
Um die PDFBox JAR zu installieren, besuchen Sie die offizielle Website und laden Sie die PDFBox-Bibliothek in der neuesten Version herunter.
Nachdem Sie ein Projekt erstellt haben, können Sie im Projektbereich
Bibliothek hinzufügen
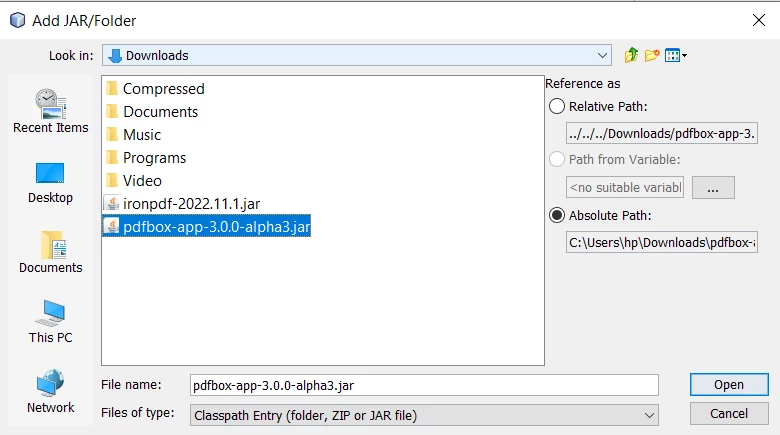
PDFBox JAR öffnen
Kopieren Sie den folgenden Code und fügen Sie ihn in die pom.xml ein.
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies>Dadurch wird die PDFBox-Abhängigkeit automatisch heruntergeladen und im Repository-Ordner installiert. Sie ist nun einsatzbereit.
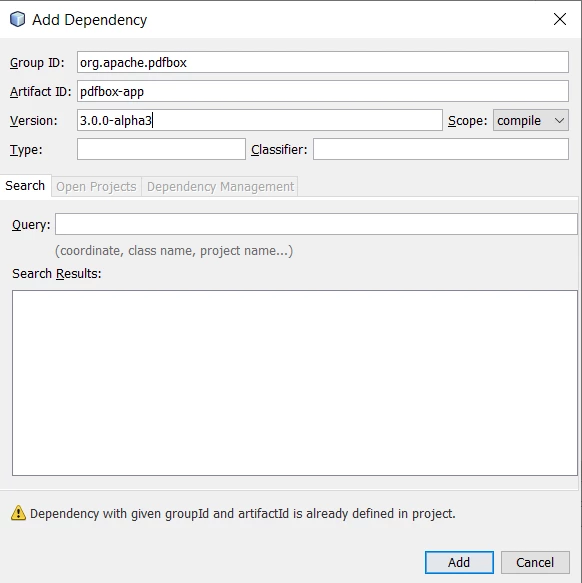
PDFBox-Abhängigkeit hinzufügen
IronPDF bietet verschiedene Methoden zur Erstellung von Dateien. Werfen wir einen Blick auf zwei der wichtigsten Methoden.
IronPDF macht es sehr einfach, Dokumente aus HTML zu erstellen. Das folgende Codebeispiel konvertiert die URL einer Webseite in eine PDF-Datei.
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
myPdf.saveAs(Paths.get("url.pdf"));Die Ausgabe ist die unten stehende URL, die gut formatiert und wie folgt gespeichert wird:
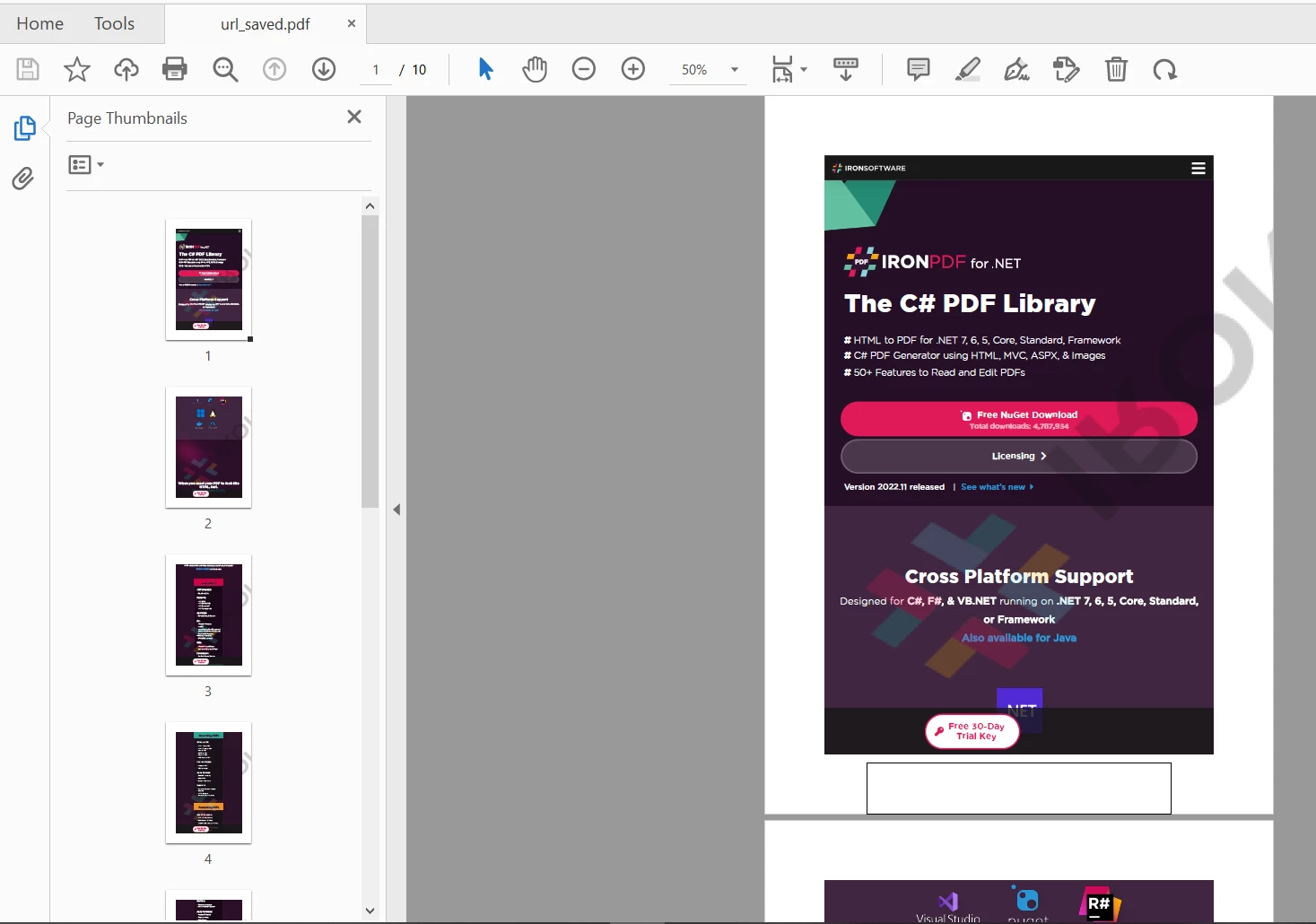
IronPDF URL-Ausgabe
Das folgende Codebeispiel zeigt, wie ein HTML-String zum Rendern einer PDF-Datei in Java verwendet werden kann. Sie verwenden einfach einen HTML-String oder ein Dokument, um es in neue Dokumente zu konvertieren.
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
myPdf.saveAs(Paths.get("html_saved.pdf"));Die Ausgabe lautet wie folgt:

IronPDF HTML-Ausgabe
PDFBox kann auch neue PDF-Dokumente aus verschiedenen Formaten erzeugen, aber es kann nicht direkt aus einer URL oder einem HTML-String konvertieren.
Das folgende Codebeispiel erstellt ein Dokument mit Text:
//Create document object
PDDocument document = new PDDocument();
PDPage blankPage = new PDPage();
document.addPage(blankPage);
//Retrieving the pages of the document
PDPage paper = document.getPage(0);
PDPageContentStream contentStream = new PDPageContentStream(document, paper);
//Begin the Content stream
contentStream.beginText();
//Setting the font to the Content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
//Setting the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
//Adding text in the form of a string
contentStream.showText(text);
//Ending the content stream
contentStream.endText();
System.out.println("Content added");
//Closing the content stream
contentStream.close();
//Saving the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
//Closing the document
document.close();
PDFBox Positionierte Ausgabe
Wenn wir jedoch contentStream.newLineAtOffset(25, 700); aus dem obigen Codebeispiel entfernen und dann das Projekt ausführen, erzeugt es ein PDF mit einer Ausgabe am unteren Rand der Seite. Das kann für einige Entwickler ziemlich lästig sein, da sie den Text mit (x,y)-Koordinaten anpassen müssen. y = 0 bedeutet, dass der Text am unteren Rand erscheint.

PDFBox ohne Positionierungsausgabe
IronPDF kann problemlos mehrere Bilder in eine einzige PDF-Datei konvertieren. Der Code zum Hinzufügen mehrerer Bilder zu einem einzigen Dokument lautet wie folgt:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs("output.pdf");
IronPDF Bilder zur Ausgabe
import java.io.File;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageContentStream;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++){
//Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
//Creating PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(),doc);
//creating the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
//Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
//Closing the PDPageContentStream object
contents.close();
}
//Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
//Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory,
exception.getMessage()),
exception);
}
PDFBox Bilder zur Ausgabe
Der Code zum Verschlüsseln von PDFs mit einem Passwort in IronPDF ist unten angegeben:
// Open a document(or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));Apache PDFBox bietet auch die Möglichkeit der Dokumentenverschlüsselung, um die Sicherheit der Dateien zu erhöhen. Sie können auch zusätzliche Informationen wie Metadaten hinzufügen. Der Code lautet wie folgt:
//Loading an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
//Creating access permission object
AccessPermission ap = new AccessPermission();
//Creating StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
//Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
//Setting the access permissions
spp.setPermissions(ap);
//Protecting the document
document.protect(spp);
System.out.println("Document encrypted");
//Saving the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
//Closing the document
document.close();IronPDF ist kostenlos für die Entwicklung einfacher PDF-Anwendungen und kann jederzeit für die kommerzielle Nutzung lizenziert werden. IronPDF bietet Einzelprojektlizenzen, Einzelentwicklerlizenzen, Lizenzen für Agenturen und multinationale Organisationen sowie SaaS- und OEM-Weiterverteilungslizenzen und Support. Alle Lizenzen sind mit einer kostenlosen Testversion, einer 30-tägigen Geld-zurück-Garantie und einem Jahr Softwareunterstützung und Upgrades erhältlich.
Das Lite-Paket ist verfügbar für $749. Bei IronPDF-Produkten fallen keinerlei wiederkehrende Gebühren an. Ausführlichere Informationen zur Softwarelizenzierung finden Sie auf der IronPDF-Lizenzierungsseite.
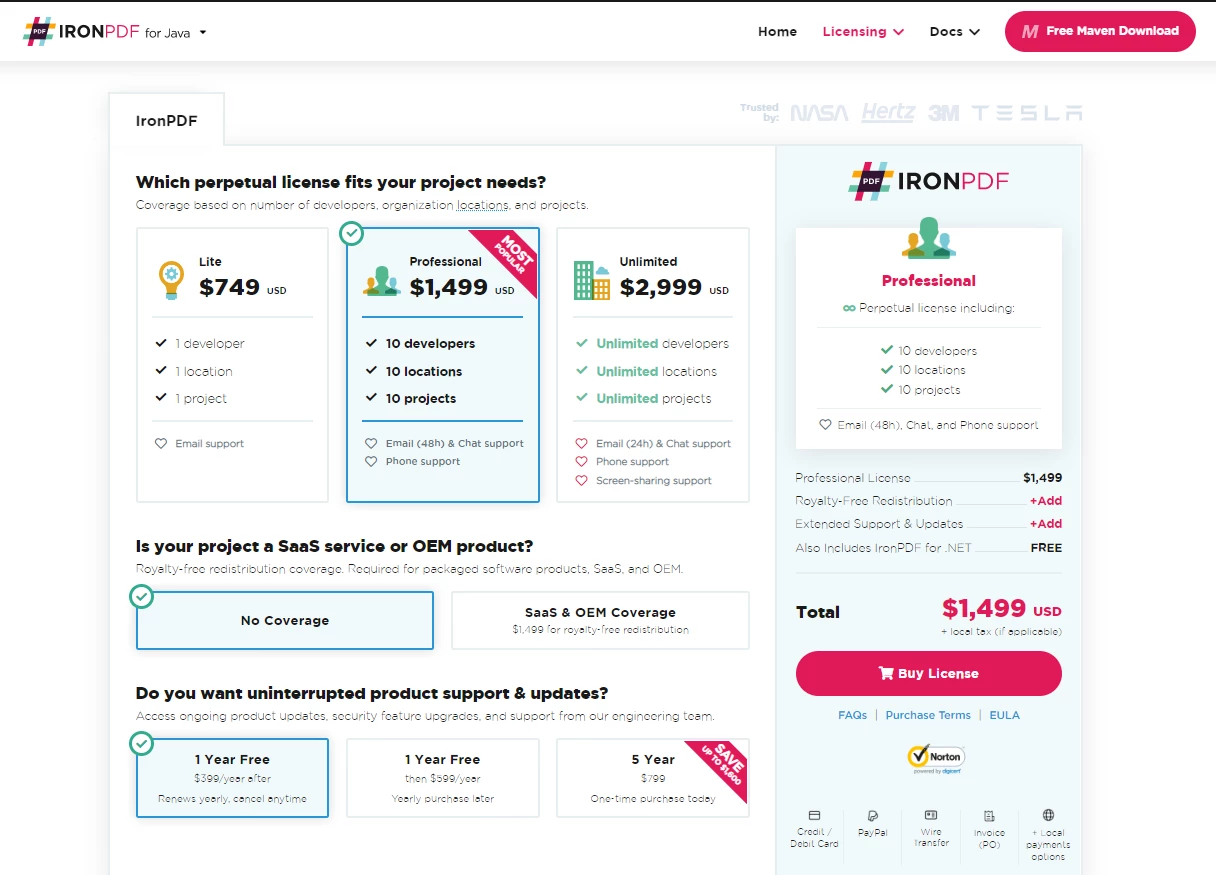
IronPDF-Lizenzierung
Apache PDFBox ist frei und kostenlos erhältlich. Sie ist kostenlos, unabhängig davon, wie sie verwendet wird, ob für persönliche, interne oder kommerzielle Zwecke.
Sie können die Apache License 2.0 (aktuelle Version) von der Apache License 2.0 Text einfügen. Um die Kopie der Lizenz einzubinden, fügen Sie sie einfach in Ihre Arbeit ein. Sie können auch den folgenden Hinweis als Kommentar am Anfang Ihres Quellcodes anbringen.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.Im Vergleich dazu hat IronPDF gegenüber Apache PDFBox die Nase vorn, sowohl was die Funktionalität als auch die Produktunterstützung betrifft. Sie bietet auch SaaS- und OEM-Support, was in der modernen Softwareentwicklung eine Voraussetzung ist. Die Bibliothek ist jedoch nicht wie Apache PDFBox für die kommerzielle Nutzung frei.
Unternehmen mit umfangreichen Softwareanwendungen benötigen möglicherweise kontinuierliche Fehlerbehebungen und Support von Drittanbietern, um Probleme zu lösen, die während der Softwareentwicklung auftreten. Dies ist etwas, das vielen Open-Source-Lösungen wie Apache PDFBox fehlt, die auf die freiwillige Unterstützung ihrer Entwicklergemeinschaft angewiesen sind, um sie zu pflegen. Kurz gesagt, IronPDF eignet sich am besten für den Einsatz in Unternehmen und auf dem Markt, während Apache PDFBox besser für persönliche und nicht-kommerzielle Anwendungen geeignet ist.
Es gibt auch eine kostenlose Testversion, um die Funktionalität von IronPDF zu testen. Probieren Sie es aus oder kaufen Sie IronPDF.
Sie können jetzt alle Produkte von Iron Software in der Iron Suite zu einem stark reduzierten Preis erhalten. Besuchen Sie diese Iron Suite-Webseite für weitere Informationen zu diesem erstaunlichen Angebot.

30-Tage-Testschlüssel sofort.
15-Tage-Testschlüssel sofort.
Ihr Testschlüssel sollte in der E-Mail sein.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
 Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.3.6</version>
</dependency>
Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich

Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.

Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente