

Wie man eingebetteten Text und Bilder aus PDFs extrahiert

Das Extrahieren von eingebettetem Text und Bildern beinhaltet das Abrufen von Textinhalten und grafischen Elementen innerhalb des Dokuments. Dieser Prozess ermöglicht es den Nutzern, auf die Inhalte zuzugreifen und sie für die Bearbeitung, die Suche, die Konvertierung von Text in andere Formate und die Speicherung von Bildern zur Wiederverwendung oder Analyse umzuwandeln.
Um Text und Bilder aus einer PDF-Datei zu extrahieren, verwenden Sie IronPDF. Das extrahierte Bild kann auf der Festplatte gespeichert oder in ein anderes Bildformat konvertiert und in das neu gerenderte Dokument eingebettet werden.
Erste Schritte mit IronPDF
Beginnen Sie noch heute mit der Verwendung von IronPDF in Ihrem Projekt mit einer kostenlosen Testversion.
Wie man eingebetteten Text und Bilder aus PDFs extrahiert
- Laden Sie die IronPdf C# Bibliothek herunter
- Das PDF-Dokument für die Text- und Bildextraktion vorbereiten
- Verwenden Sie die
ExtractAllText-Methode, um Text zu extrahieren - Verwenden Sie die
ExtractAllImages-Methode, um Bilder zu extrahieren - Geben Sie die bestimmten Seiten an, von denen Text und Bilder extrahiert werden sollen
Text extrahieren Beispiel
Die Textextraktion kann sowohl für neu gerenderte als auch für bestehende PDF-Dokumente durchgeführt werden. Verwenden Sie die ExtractAllText-Methode, um den eingebetteten Text aus dem Dokument zu extrahieren. Die Methode gibt eine Zeichenkette zurück, die den gesamten Text in der angegebenen PDF-Datei enthält. Die Seiten werden durch vier aufeinanderfolgende Environment.NewLinesPages getrennt. Verwenden wir ein Beispiel-PDF, das ich von der Wikipedia-Website gerendert habe.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)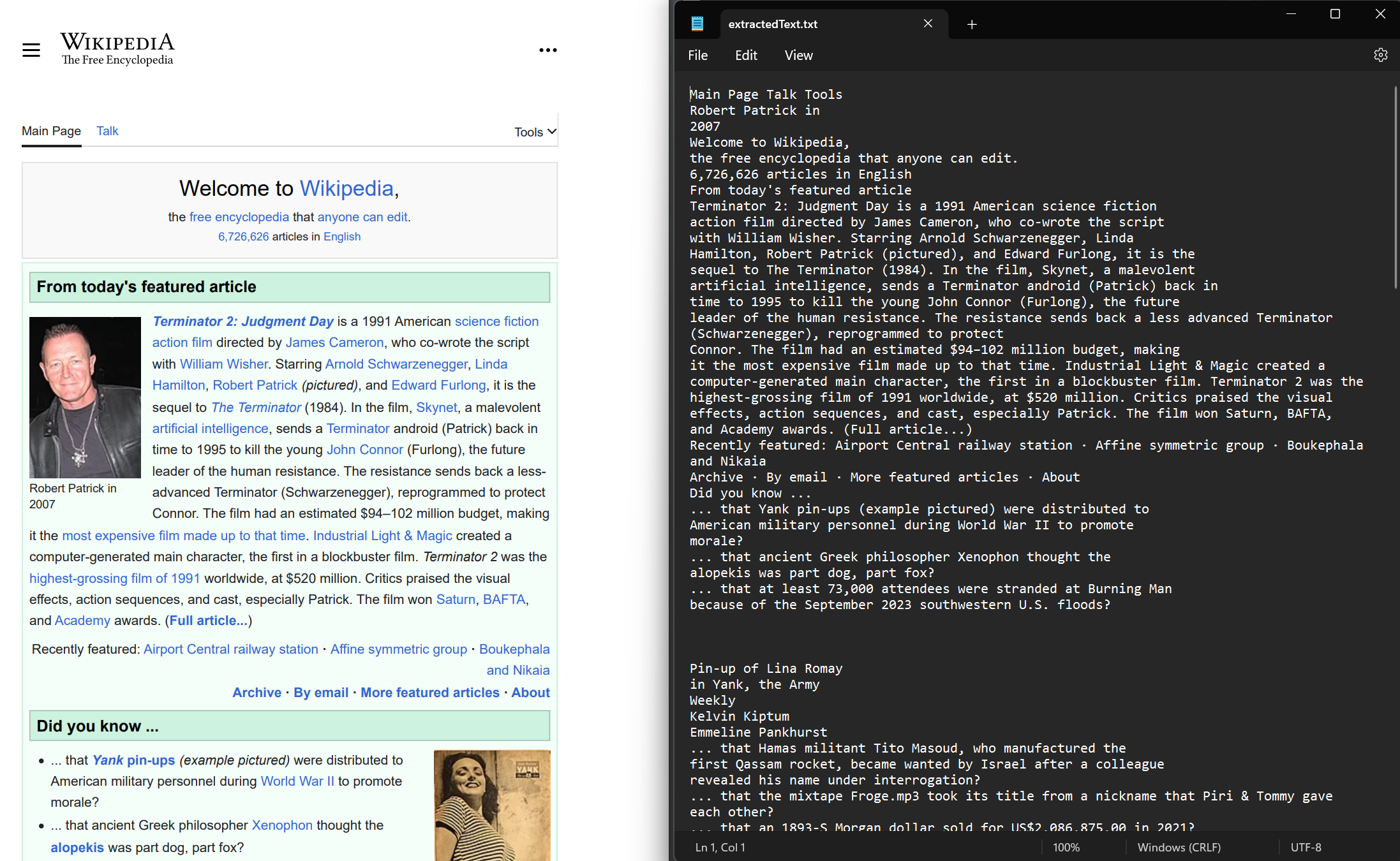
Text zeilen- und zeichenweise extrahieren
Innerhalb jeder PDF-Seite ist es möglich, die Koordinaten von Textzeilen und Zeichen abzurufen. Wählen Sie zuerst eine Seite aus dem PDF und greifen Sie auf die Zeilen und Zeichen Eigenschaft zu. Die Koordinaten werden als Werte für Oben, Rechts, Unten und Links angegeben und stellen die Position des Textes dar.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))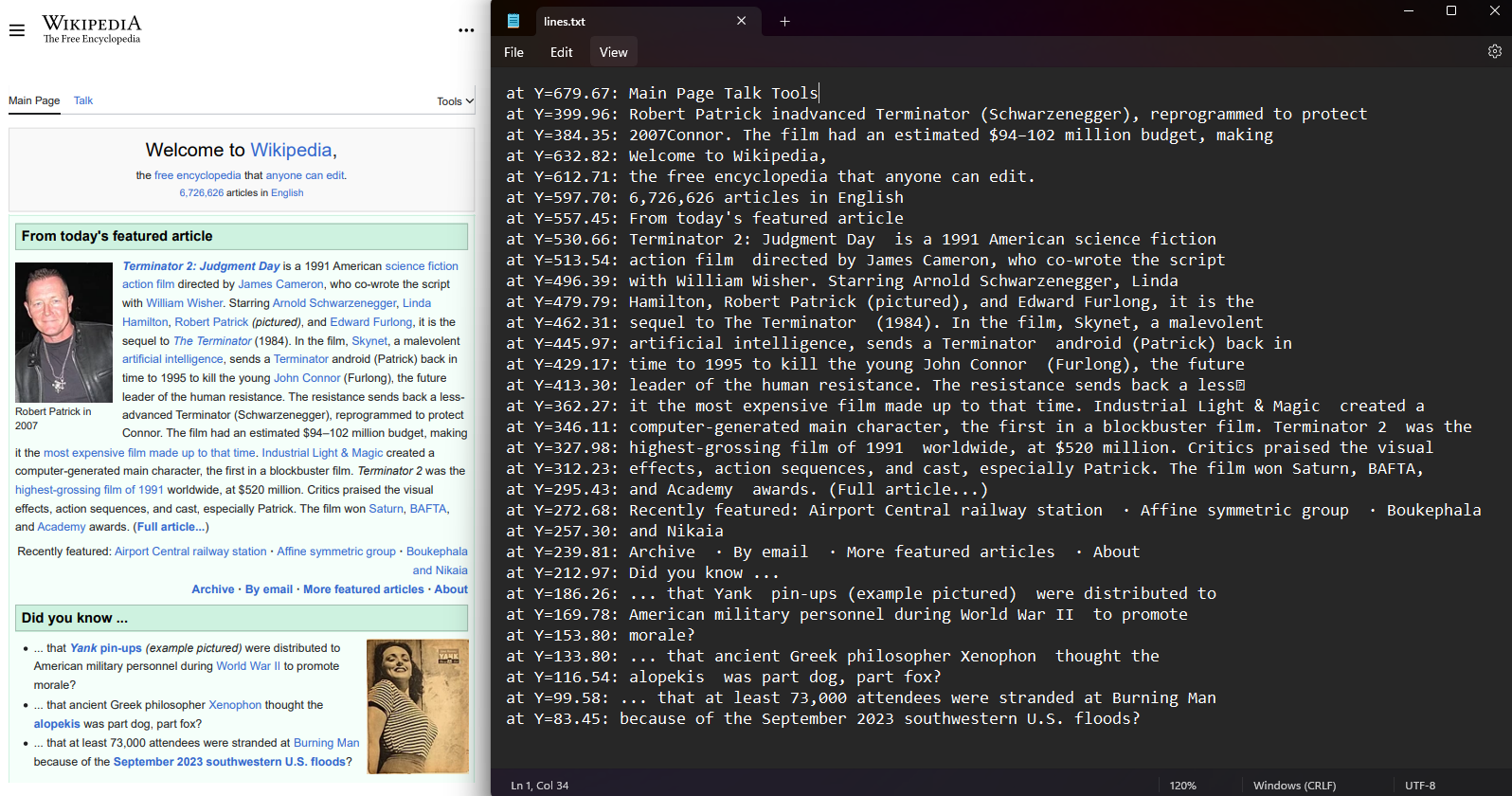
Bilder extrahieren Beispiel
Verwenden Sie die ExtractAllImages-Methode, um alle im Dokument eingebetteten Bilder zu extrahieren. Die Methode gibt die Bilder als eine Liste von AnyBitmap-Objekten zurück. Wir haben das gleiche Dokument wie in unserem vorherigen Beispiel verwendet, die Bilder extrahiert und in den Ordner "images" exportiert.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next iZusätzlich zu der oben gezeigten ExtractAllImages-Methode kann der Benutzer die Methoden ExtractAllBitmaps und ExtractAllRawImages verwenden, um Bildinformationen aus dem Dokument zu extrahieren. Während die ExtractAllBitmaps-Methode eine Liste von AnyBitmap zurückgibt, wie im Codebeispiel, extrahiert die ExtractAllRawImages-Methode alle Bilder aus einem PDF-Dokument und gibt sie als Rohdaten in Form von Byte-Arrays (byte []) zurück.
Text und Bilder auf bestimmten Seiten extrahieren
Sowohl die Text- als auch die Bildextraktion kann auf einzelnen oder mehreren angegebenen Seiten durchgeführt werden. Verwenden Sie die Methoden ExtractTextFromPage und ExtractTextFromPages, um Text von einer einzelnen Seite bzw. von mehreren Seiten zu extrahieren. Verwenden Sie zum Extrahieren von Bildern die Methoden ExtractImagesFromPage und ExtractImagesFromPages.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)







