Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die C# PDF-Bibliothek
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


In der heutigen Entwicklungswelt ist die Arbeit mit PDFs eine häufige Anforderung für Anwendungen, die Dokumente, Formulare oder Berichte verarbeiten müssen. Egal, ob Sie eine E-Commerce-Plattform, ein Dokumentenmanagementsystem erstellen oder einfach nur Rechnungen verarbeiten müssen, das Extrahieren und Suchen von Text aus PDFs kann entscheidend sein. Dieser Artikel wird Sie durch die Verwendung von C# string.Contains() mitIronPDFum Text aus PDF-Dateien in Ihren .NET-Projekten zu suchen und zu extrahieren.
Beim Durchführen von Suchanfragen müssen Sie möglicherweise Zeichenfolgenvergleiche basierend auf spezifischen Teilstring-Anforderungen durchführen. In solchen Fällen bietet C# Optionen wie string.Contains(), was eine der einfachsten Formen des Vergleichs ist.
Wenn Sie angeben müssen, ob Sie die Groß- und Kleinschreibung ignorieren möchten oder nicht, können Sie die StringComparison-Enumeration verwenden. Dadurch können Sie den Typ des Zeichenfolgenvergleichs auswählen, den Sie möchten—wie beispielsweise einen ordinalen Vergleich oder einen nicht case-sensitiven Vergleich.
Wenn Sie mit bestimmten Positionen in der Zeichenfolge arbeiten möchten, wie der ersten oder letzten Zeichenposition, können Sie immer Substring verwenden, um bestimmte Teile der Zeichenfolge zur weiteren Verarbeitung zu isolieren.
Wenn Sie nach Überprüfungen auf leere Zeichenfolgen oder andere Randfälle suchen, stellen Sie sicher, dass Sie diese Szenarien in Ihrer Logik behandeln.
Wenn Sie mit großen Dokumenten zu tun haben, ist es nützlich, den Anfangspunkt Ihrer Textextraktion zu optimieren, um nur relevante Abschnitte und nicht das gesamte Dokument zu extrahieren. Dies kann besonders nützlich sein, wenn Sie versuchen, den Speicher und die Verarbeitungszeit nicht zu überlasten.
Wenn Sie sich über den besten Ansatz für Vergleichsregeln unsicher sind, überlegen Sie, wie die spezifische Methode funktioniert und wie Sie möchten, dass sich Ihre Suche in verschiedenen Szenarien verhält.(z.B. Übereinstimmung mehrerer Begriffe, Umgang mit Leerzeichen, etc.).
Wenn Ihre Anforderungen über einfache Substring-Prüfungen hinausgehen und eine fortgeschrittenere Mustererkennung erfordern, sollten Sie die Verwendung von regulären Ausdrücken in Betracht ziehen, die bei der Arbeit mit PDFs erhebliche Flexibilität bieten.
Wenn Sie es noch nicht getan haben, probieren Sie IronPDFskostenloser Testheute, um seine Fähigkeiten zu erkunden und zu sehen, wie es Ihre PDF-Verwaltungsaufgaben vereinfachen kann. Egal, ob Sie ein Dokumentenmanagementsystem aufbauen, Rechnungen verarbeiten oder einfach nur Daten aus PDFs extrahieren müssen, IronPDF ist das perfekte Werkzeug dafür.
IronPDF ist eine leistungsstarke Bibliothek, die Entwicklern hilft, mit PDFs im .NET-Ökosystem zu arbeiten. Es ermöglicht Ihnen, PDF-Dateien einfach zu erstellen, zu lesen, zu bearbeiten und zu manipulieren, ohne auf externe Tools oder komplexe Konfigurationen angewiesen zu sein.
IronPDF bietet eine breite Palette an Funktionen für die Arbeit mit PDFs in C#-Anwendungen. Einige der wichtigsten Merkmale sind:
Formularverwaltung: Formularfelder in interaktiven PDF-Formularen extrahieren oder ausfüllen.
IronPDF ist darauf ausgelegt, einfach zu bedienen zu sein, aber auch flexibel genug, um komplexe Szenarien mit PDFs zu bewältigen. Es funktioniert nahtlos mit .NET Core und .NET Framework und ist damit ideal für jedes .NET-basierte Projekt geeignet.
Zu verwendenIronPDF, installieren Sie es über den NuGet-Paket-Manager in Visual Studio:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfBevor wir uns mit der Suche in PDFs beschäftigen, lassen Sie uns zunächst verstehen, wie man mit IronPDF Text aus einer PDF extrahiert.
IronPDF bietet eine einfache API zum Extrahieren von Text aus PDF-Dokumenten. Damit können Sie problemlos nach bestimmten Inhalten in PDFs suchen.
Das folgende Beispiel zeigt, wie man mit IronPDF Text aus einer PDF-Datei extrahiert:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
string str = pdf.ExtractAllText();
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
string str = pdf.ExtractAllText();
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
Dim str As String = pdf.ExtractAllText()
End Sub
End ClassIn diesem Beispiel extrahiert die ExtractAllText() Methode extrahiert den gesamten Text aus dem PDF-Dokument. Dieser Text kann dann verarbeitet werden, um nach bestimmten Schlüsselwörtern oder Phrasen zu suchen.
Sobald Sie den Text aus der PDF extrahiert haben, können Sie C#'s eingebauten string.Contains verwenden.()Methode zur Suche nach bestimmten Wörtern oder Phrasen.
Der string.Contains() Methode gibt einen booleschen Wert zurück, der angibt, ob eine bestimmte Zeichenfolge innerhalb einer Zeichenfolge existiert. Dies ist besonders nützlich für die grundlegende Textsuche.
Hier ist, wie Sie string.Contains verwenden können()nach einem Schlüsselwort im extrahierten Text suchen:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)Lassen Sie uns dies mit einem praktischen Beispiel weiter aufschlüsseln. Angenommen, Sie möchten herausfinden, ob eine bestimmte Rechnungsnummer in einem PDF-Rechnungsdokument vorhanden ist.
Hier ist ein vollständiges Beispiel, wie Sie dies implementieren könnten:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
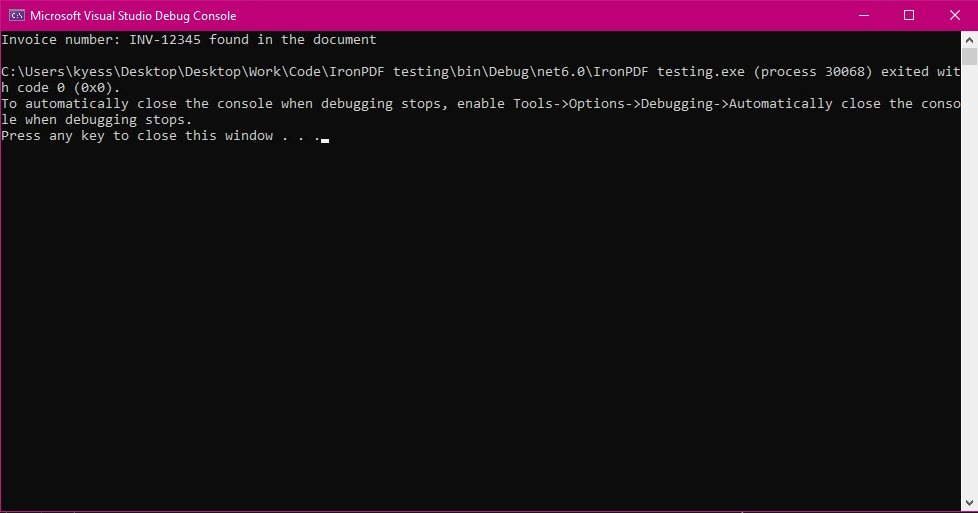
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End Class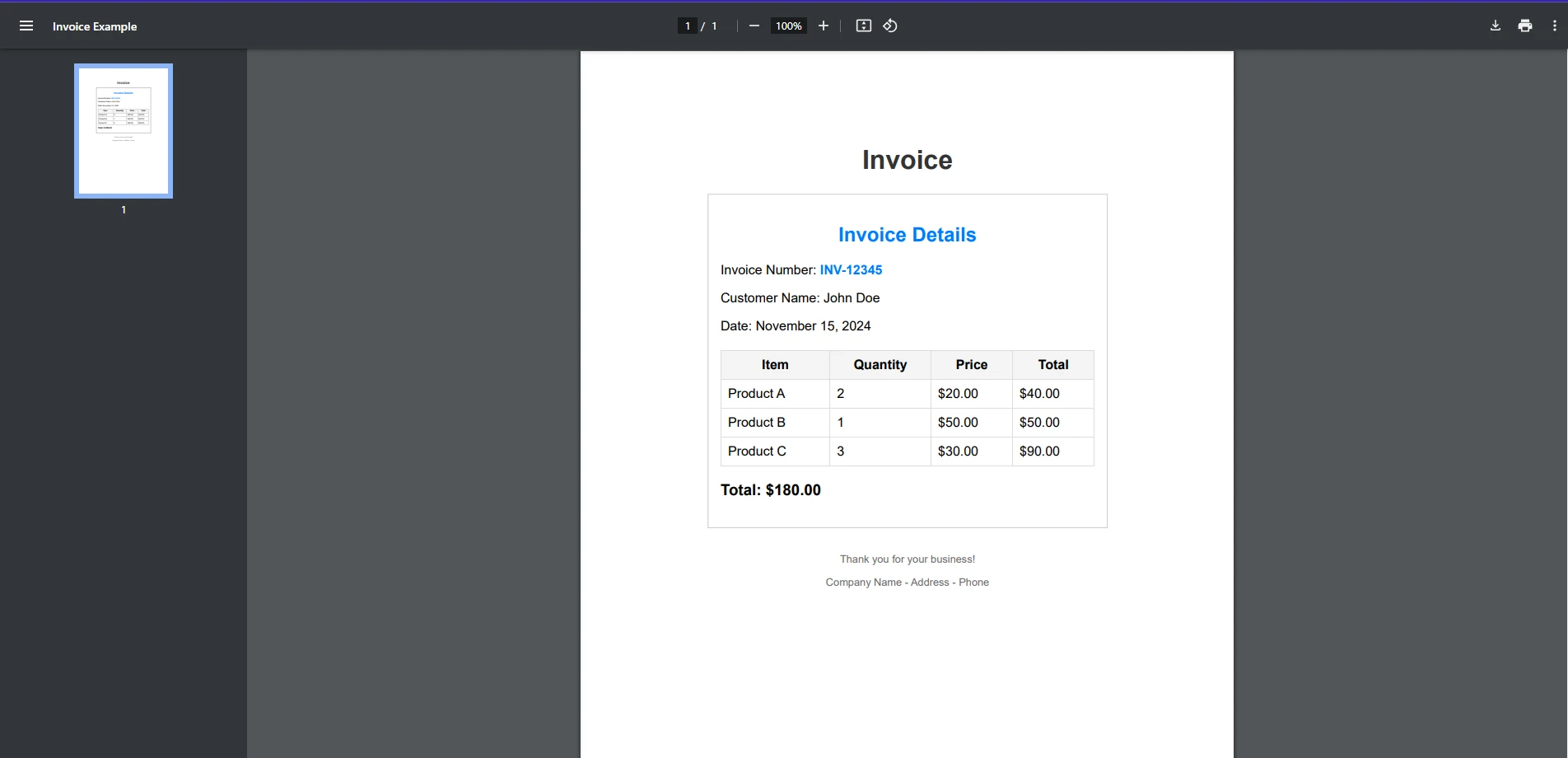
In diesem Beispiel:
Während string.Contains()funktioniert für einfache Substring-Suchen, Sie möchten möglicherweise komplexere Suchen durchführen, wie das Finden eines Musters oder einer Reihe von Schlüsselwörtern. Dafür können Sie reguläre Ausdrücke verwenden.
Hier ist ein Beispiel für die Verwendung eines regulären Ausdrucks, um im PDF-Text nach einem beliebigen gültigen Rechnungsnummernformat zu suchen:
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
}
}Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
End Sub
End ClassDieser Code sucht nach allen Rechnungsnummern im Muster INV-XXXXX, wobei XXXXX eine Reihe von Ziffern ist.
Beim Arbeiten mit PDFs, insbesondere bei großen oder komplexen Dokumenten, gibt es einige bewährte Vorgehensweisen, die beachtet werden sollten:
IronPDF lässt sich problemlos in .NET-Projekte integrieren. Nach dem Herunterladen und Installieren der IronPDF-Bibliothek über NuGet importieren Sie diese einfach in Ihren C#-Code, wie in den obigen Beispielen gezeigt.
Die Flexibilität von IronPDF ermöglicht es Ihnen, komplexe Dokumentverarbeitungs-Workflows zu erstellen, wie zum Beispiel:
IronPDFmacht die Arbeit mit PDFs einfach und effizient, insbesondere wenn Sie Text aus PDFs extrahieren und durchsuchen müssen. Durch die Kombination von C#'s string.Contains()Mithilfe der Textextraktionsfunktionen von IronPDF können Sie PDFs in Ihren .NET-Anwendungen schnell durchsuchen und verarbeiten.
Wenn Sie es noch nicht getan haben, probieren Sie noch heute die kostenlose Testversion von IronPDF aus, um dessen Fähigkeiten zu erkunden und zu sehen, wie es Ihre PDF-Bearbeitungsaufgaben erleichtern kann. Egal, ob Sie ein Dokumentenmanagementsystem aufbauen, Rechnungen verarbeiten oder einfach nur Daten aus PDFs extrahieren müssen, IronPDF ist das perfekte Werkzeug dafür.
Um mit IronPDF zu beginnen, laden Sie daskostenloser Testund erleben Sie seine leistungsstarken Funktionen zur PDF-Bearbeitung aus erster Hand. Besuchen SieIronPDF-Websiteum noch heute zu beginnen.
Install-Package IronPdf

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.
Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente