Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die C# PDF-Bibliothek
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Parallel.ForEachist eine Methode in C#, die es ermöglicht, parallele Iterationen über eine Sammlung oder Datenquelle durchzuführen. Anstatt jedes Element in der Sammlung nacheinander zu verarbeiten, ermöglicht eine parallele Schleife die gleichzeitige Ausführung, was die Leistung erheblich verbessern kann, indem die gesamte Ausführungszeit reduziert wird. Die parallele Verarbeitung funktioniert, indem die Arbeit auf mehrere Kernprozessoren aufgeteilt wird, sodass Aufgaben gleichzeitig ausgeführt werden können. Dies ist besonders nützlich, wenn Aufgaben verarbeitet werden, die unabhängig voneinander sind.
Im Gegensatz zu einer normalen foreach-Schleife, die Elemente sequenziell verarbeitet, kann der parallele Ansatz große Datensätze wesentlich schneller bewältigen, indem er mehrere Threads parallel nutzt.
IronPDFist eine leistungsstarke Bibliothek zur Verarbeitung von PDFs in .NET, fähig zukonvertierung von HTML in PDF, extrahieren von Text aus PDFs, Zusammenführen und Aufteilen von Dokumentenund mehr. Beim Arbeiten mit großen Volumen von PDF-Aufgaben kann die Verwendung von Parallelverarbeitung mit Parallel.ForEach die Ausführungszeit erheblich verkürzen. Egal, ob Sie Hunderte von PDFs erzeugen oder Daten aus mehreren Dateien gleichzeitig extrahieren, die Nutzung von Datenparallelismus mit IronPDF stellt sicher, dass Aufgaben schneller und effizienter abgeschlossen werden.
Dieser Leitfaden richtet sich an .NET-Entwickler, die ihre PDF-Verarbeitungsaufgaben mit IronPDF und Parallel.ForEach optimieren möchten. Grundkenntnisse in C# und Vertrautheit mit der IronPDF-Bibliothek werden empfohlen. Am Ende dieses Leitfadens werden Sie in der Lage sein, parallele Verarbeitung zu implementieren, um mehrere PDF-Aufgaben gleichzeitig zu bearbeiten, was sowohl die Leistung als auch die Skalierbarkeit verbessert.
Zu verwendenIronPDFIn Ihrem Projekt müssen Sie die Bibliothek über NuGet installieren.
Um IronPDF zu installieren, befolgen Sie diese Schritte:
Öffnen Sie Ihr Projekt in Visual Studio.
Gehe zu Tools → NuGet-Paket-Manager → NuGet-Pakete für die Lösung verwalten.
Alternativ können Sie es über die NuGet-Paket-Manager-Konsole installieren:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfSobald IronPDF installiert ist, können Sie mit der Verwendung für PDF-Erstellungs- und -Bearbeitungsaufgaben beginnen.
Parallel.ForEach ist Teil des System.Threading.Tasks-Namespace und bietet eine einfache und effektive Möglichkeit, Iterationen gleichzeitig auszuführen. Die Syntax für Parallel.ForEach lautet wie folgt:
Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, Sub(item)
' Code to process each item
End Sub)Jeder Eintrag in der Sammlung wird parallel verarbeitet, und das System entscheidet, wie die Arbeitslast auf die verfügbaren Threads verteilt wird. Sie können auch Optionen angeben, um den Grad der Parallelität zu steuern, wie zum Beispiel die maximale Anzahl der verwendeten Threads.
Im Vergleich dazu verarbeitet eine herkömmliche foreach-Schleife jedes Element nacheinander, während die parallele Schleife mehrere Elemente gleichzeitig verarbeiten kann, was die Leistung beim Umgang mit großen Kollektionen verbessert.
Stellen Sie zunächst sicher, dass IronPDF wie im Abschnitt „Erste Schritte“ beschrieben installiert ist. Danach können Sie mit der Erstellung Ihrer parallelen PDF-Verarbeitungslogik beginnen.
string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});Dim htmlPages() As String = { "page1.html", "page2.html", "page3.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
End Sub)Dieser Code demonstriert, wie man mehrere HTML-Seiten parallel in PDFs konvertiert.
Bei der Bearbeitung paralleler Aufgaben ist das Fehlerhandling entscheidend. Verwenden Sie try-catch-Blöcke innerhalb der Parallel.ForEach-Schleife, um alle Ausnahmen zu verwalten.
Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, Sub(pdfFile)
Try
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractAllText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
Catch ex As Exception
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}")
End Try
End Sub)Ein weiterer Anwendungsfall für die Parallelverarbeitung ist das Extrahieren von Text aus einer Reihe von PDFs. Beim Umgang mit mehreren PDF-Dateien kann die gleichzeitige Textextraktion viel Zeit sparen. Das folgende Beispiel zeigt, wie dies erfolgen kann.
using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}Imports IronPdf
Imports System.Linq
Imports System.Threading.Tasks
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfFiles() As String = { "doc1.pdf", "doc2.pdf", "doc3.pdf" }
Parallel.ForEach(pdfFiles, Sub(pdfFile)
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
End Sub)
End Sub
End Class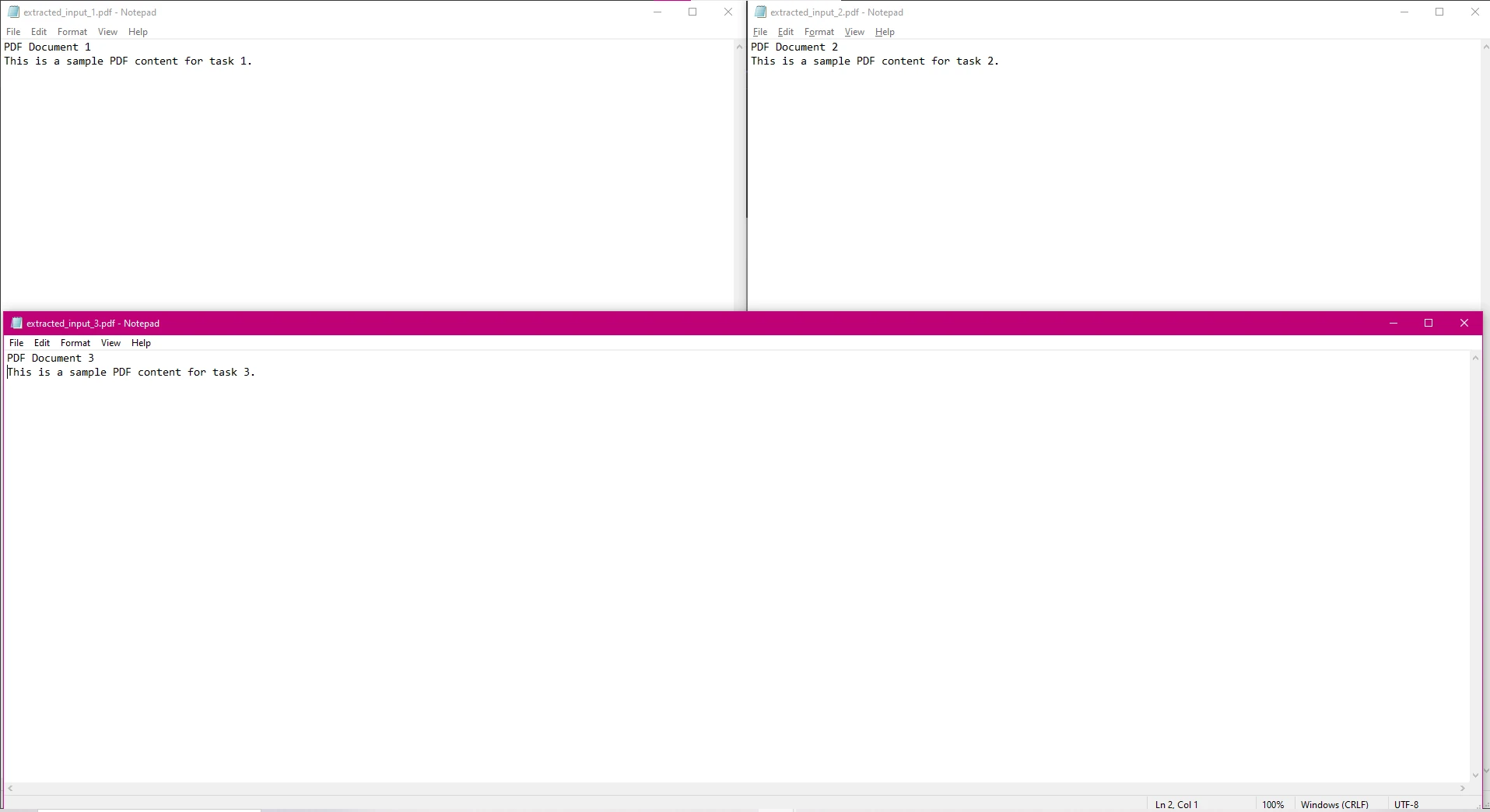
In diesem Code wird jede PDF-Datei parallel verarbeitet, um Text zu extrahieren, und der extrahierte Text wird in separaten Textdateien gespeichert.
In diesem Beispiel werden wir mehrere PDFs aus einer Liste von HTML-Dateien parallel erzeugen, was ein typisches Szenario sein könnte, wenn Sie mehrere dynamische HTML-Seiten in PDF-Dokumente umwandeln müssen.
using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});Imports IronPdf
Private htmlFiles() As String = { "example.html", "example_1.html", "example_2.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
Try
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlFileAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
Console.WriteLine($"PDF created for {htmlFile}")
Catch ex As Exception
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}")
End Try
End Sub)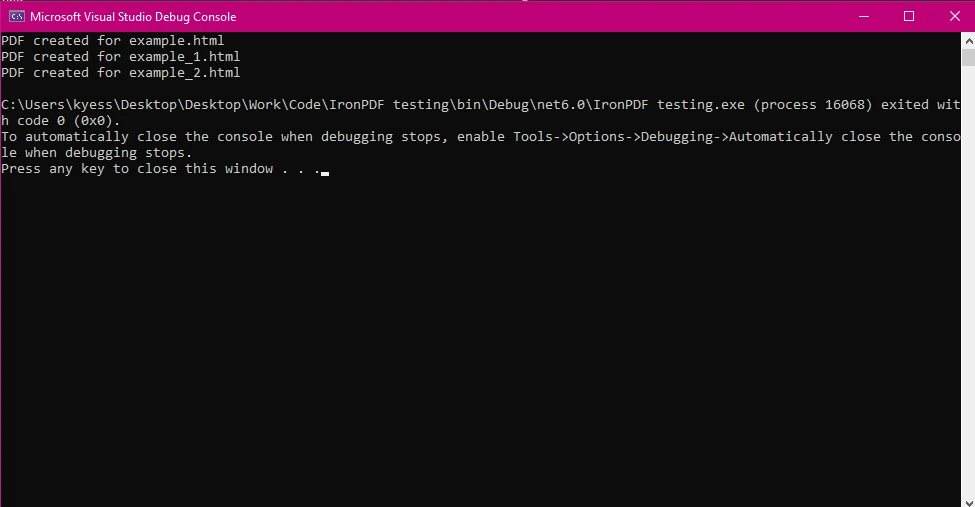
HTML-Dateien: Das Array htmlFiles enthält Pfade zu mehreren HTML-Dateien, die Sie in PDFs umwandeln möchten.
Parallel.ForEach(htmlFiles, htmlFile =>{...}) verarbeitet jede HTML-Datei gleichzeitig, was die Ausführung beschleunigt, wenn mehrere Dateien bearbeitet werden.
Speichern des PDFs: Nach der Generierung des PDFs wird es mit der pdf.SaveAs-Methode gespeichert, wobei der Name der Ausgabedatei um den Namen der ursprünglichen HTML-Datei ergänzt wird.
IronPDF ist für die meisten Operationen thread-sicher. Einige Vorgänge, wie z.B. das gleichzeitige Schreiben in dieselbe Datei, können jedoch Probleme verursachen. Stellen Sie stets sicher, dass jede parallele Aufgabe auf einer separaten Ausgabedatei oder Ressource arbeitet.
Um die Leistung zu optimieren, sollten Sie den Grad der Parallelität steuern. Für große Datensätze sollten Sie möglicherweise die Anzahl der gleichzeitigen Threads begrenzen, um eine Systemüberlastung zu vermeiden.
var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};Dim options = New ExecutionDataflowBlockOptions With {.MaxDegreeOfParallelism = 4}Beim Verarbeiten einer großen Anzahl von PDFs sollte der Speicherverbrauch beachtet werden. Versuchen Sie, Ressourcen wie PdfDocument-Objekte freizugeben, sobald sie nicht mehr benötigt werden.
Eine Erweiterungsmethode ist eine besondere Art von statischer Methode, die es Ihnen ermöglicht, einem bestehenden Typ neue Funktionalität hinzuzufügen, ohne dessen Quellcode zu ändern. Dies kann nützlich sein, wenn Sie mit Bibliotheken wie IronPDF arbeiten, wo Sie benutzerdefinierte Verarbeitungsmethoden hinzufügen oder deren Funktionalität erweitern möchten, um die Arbeit mit PDFs angenehmer zu gestalten, insbesondere in Szenarien mit paralleler Verarbeitung.
Durch die Verwendung von Erweiterungsmethoden können Sie präzisen, wiederverwendbaren Code erstellen, der die Logik in parallelen Schleifen vereinfacht. Dieser Ansatz reduziert nicht nur Duplikationen, sondern hilft Ihnen auch, eine saubere Codebasis zu pflegen, besonders bei der Arbeit mit komplexen PDF-Workflows und Datenparallelität.
Verwenden von parallelen Schleifen wie Parallel.ForEach mitIronPDFbietet erhebliche Leistungssteigerungen bei der Verarbeitung großer Mengen von PDFs. Ob Sie HTML in PDFs umwandeln, Text extrahieren oder Dokumente bearbeiten: Datenparallelität ermöglicht eine schnellere Ausführung durch gleichzeitiges Ausführen von Aufgaben. Der parallele Ansatz stellt sicher, dass Operationen über mehrere Kernprozessoren hinweg ausgeführt werden können, wodurch die gesamte Ausführungszeit verkürzt und die Leistung bei Batch-Verarbeitungsvorgängen verbessert wird.
Während die Parallelverarbeitung Aufgaben beschleunigt, sollten Sie auf die Thread-Sicherheit und das Ressourcenmanagement achten. IronPDF ist für die meisten Vorgänge threadsicher, aber es ist wichtig, potenzielle Konflikte beim Zugriff auf gemeinsam genutzte Ressourcen zu handhaben. Berücksichtigen Sie Fehlerbehandlung und Speichermanagement, um Stabilität zu gewährleisten, insbesondere wenn Ihre Anwendung skaliert.
Wenn Sie bereit sind, tiefer in IronPDF einzutauchen und erweiterte Funktionen zu erforschen, dieoffizielle Dokumentation, sodass Sie die Bibliothek in Ihren eigenen Projekten testen können, bevor Sie sich zu einem Kauf verpflichten.
Install-Package IronPdf

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.
Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente