Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die C# PDF-Bibliothek
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Für dieses Tutorial werden wir uns ansehen, wie mantext extrahierenaus PDF(Portable Document Format)Dokumente in C# mit zwei verschiedenen PDF-Bibliotheken.
In der heutigen modernen Web-Ära gibt es eine Reihe von Bibliotheken, die in der Lage sind, Text und Bilder aus PDF-Dateien zum Parsen und Lesen zu extrahieren. Heute werden wir zwei leistungsstarke PDF-Bibliotheken verwenden,IronPDF undQuestPDF, um Text aus einer PDF-Datei zu extrahieren. Durch den Vergleich, wie diese beiden Bibliotheken eine einfache Textextraktionsaufgabe verarbeiten, können wir feststellen, welche besser für die Bewältigung solcher fortgeschrittener PDF-Aufgaben geeignet sein könnte. Bevor wir zum Vergleichsabschnitt kommen, werfen wir zunächst einen kurzen Blick auf eine kurze Einführung zu jeder Bibliothek.
QuestPDF ist eine moderne Open-Source-Bibliothek zur PDF-Erstellung, die speziell für .NET-Entwickler entwickelt wurde. Es nutzt eine moderne deklarative API, die es Nutzern ermöglicht, komplexe PDF-Layouts mit großer Flexibilität und Präzision zu definieren und zu erzeugen. Während sich QuestPDF primär auf die Dokumentenerstellung anstatt auf die Textextraktion konzentriert, bietet es einen sauberen, intuitiven Ansatz zum Erstellen von Dokumenten von Grund auf und zum Manipulieren verschiedener Elemente innerhalb des Dokuments. Dies macht es besonders geeignet für Anwendungen, die benutzerdefinierte, dynamische PDF-Inhalte erfordern.
IronPDF ist eine vielseitige PDF-Verarbeitungsbibliothek, die entwickelt wurde, um die Arbeit mit PDFs in C# einfacher und effizienter zu gestalten. Im Gegensatz zu QuestPDF ist IronPDF speziell für die Erstellung und Bearbeitung von PDFs entwickelt worden. Zu den angebotenen Funktionen gehört PDFverschlüsselung, umfangreiche Unterstützung für die Bearbeitung undanmerkenvorhandene PDFs, Konvertierung verschiedener Dokumente in das PDF-Format, Hinzufügen vonkopfzeilen und Fußzeilen (die verwendet werden können, um Seitenzahlen anzuzeigen), Bearbeitung von Dokumentmetadaten, Multithreading- & asynchrone Unterstützung sowie fortschrittliche PDF-Konvertierungswerkzeuge.
Zusätzlich zu seinem umfangreichen Funktionsumfang bietet IronPDF vollständige plattformübergreifende Unterstützung und unterstützt .NET 5/6/7, .NET Core und .NET Framework. Es ist auch vollständig kompatibel mit Windows, macOS, Linux und Cloud-Plattformen wie Azure und AWS, was es zu einer ausgezeichneten Wahl für plattformübergreifende .NET-Anwendungen macht.
In unserem heutigen Beispiel werden wir Text aus unserem Beispiel-Rechnungs-PDF-Dokument mit beiden Bibliotheken extrahieren.
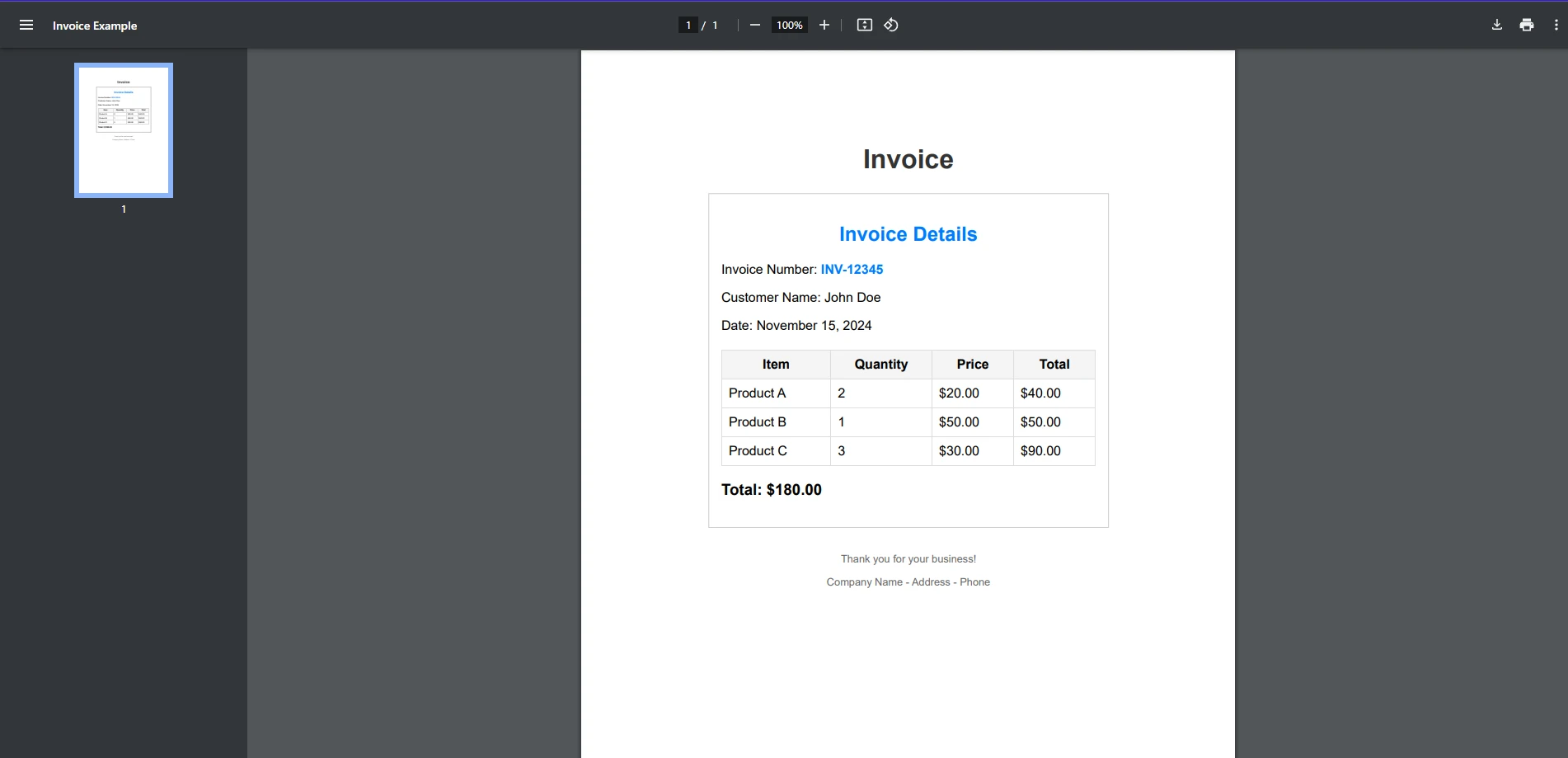
Zuerst werden wir schauen, ob QuestPDF diese Aufgabe bewältigen kann.
Leider, obwohl QuestPDF bei der PDF-Erstellung und der Durchführung bestimmter PDF-Aufgaben hervorragend ist, gehört die Textextraktion nicht zu den Funktionen, die es derzeit anbietet. Obwohl QuestPDF nicht von Natur aus für die Extraktion von Text aus bestehenden PDF-Dateien ausgelegt ist, bietet es grundlegende Tools zur Arbeit mit PDFs, die mit zusätzlicher Logik oder Drittanbieter-Integrationen für die Textextraktion erweitert werden können. Zum Beispiel könnte QuestPDF verwendet werden, um PDF-Dokumente mit strukturiertem Inhalt zu erstellen, und Sie könnten eine maßgeschneiderte Lösung implementieren, um Inhalte basierend auf der Struktur des Dokuments mithilfe einer Drittanbieterbibliothek zu extrahieren.
Text-Extraktionist nur eine der Aufgaben, in denen IronPDF bei der Arbeit mit PDFs glänzt. Mit nur wenigen Codezeilen können wir Text aus einem gesamten PDF-Dokument extrahieren. Dies kann im folgenden Code-Snippet gesehen werden:
using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}Imports IronPdf
Public Class Program
Public Shared Sub main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Console.WriteLine(text)
End Sub
End Class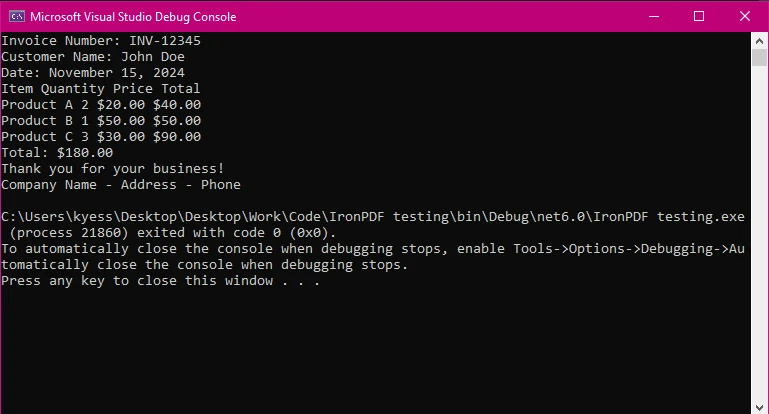
IronPDF bietet eine einfache API zum Extrahieren von Text, was es ideal für Entwickler macht, die auf Effizienz achten. In nur drei Zeilen konnten wir den Textinhalt aus unserem PDF-Dokument extrahieren und zur Ansicht anzeigen. Von hier aus können Sie den extrahierten Text einfach für die weitere Verwendung oder Bearbeitung speichern.
QuestPDF hingegen konnte eine Aufgabe wie die Textextraktion nicht bewältigen, da es über weniger Funktionen verfügt als Bibliotheken wie IronPDF. Während es andere Aufgaben wie die PDF-Erstellung und grundlegende Manipulation bewältigen kann, müssten Sie externe Bibliotheken implementieren, um Text zu extrahieren.
Wenn es darum gehtextrahieren von Text. QuestPDF ist kostenlos über die Verwendung seiner Community-Lizenz für private Projekte, bietet jedoch auch die Option fürkommerzielle Lizenzen.
Beide Bibliotheken sind genau und zuverlässig, aber die Wahl hängt letztendlich von den Anforderungen Ihres Projekts ab.
Für einen tieferen Vergleich dieser Bibliotheken, lesen Sie den vollständigen Blog aufIronPDF vs QuestPDF.
Install-Package IronPdf

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.
Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente