Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die C# PDF-Bibliothek
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF (Portable Document Format) ist ein weit verbreitetes Dateiformat zum konsistenten und sicheren Teilen von Dokumenten. Das Lesen und Bearbeiten solcher Dateien in C# ist eine häufige Anforderung in verschiedenen Anwendungen, wie z. B. Dokumentenverwaltungssystemen, Berichtstools und mehr. In diesem Artikel werden wir zwei beliebte Bibliotheken für das Lesen von PDF-Dateien in C# vergleichen: IronPDF und iTextSharp (die neueste .NET-Bibliothek iText).
IronPDF ist eine umfassende C#-Bibliothek von Iron Software, die eine breite Palette von Funktionen zum Arbeiten mit PDF-Dateien bietet. Es ermöglicht Entwicklern, PDF-Dokumente nahtlos zu erstellen, zu bearbeiten und zu manipulieren. IronPDF ist für seine Einfachheit und Benutzerfreundlichkeit bekannt und damit eine ausgezeichnete Wahl für Entwickler, die PDF-Funktionen schnell in ihre Anwendungen integrieren müssen.
iTextSharp ist eine weitere beliebte Bibliothek für die Arbeit mit PDF-Dateien in C#. Es gibt sie schon seit geraumer Zeit und sie ist in der Industrie weit verbreitet. iText bietet eine Vielzahl von Funktionen zur Erstellung und Bearbeitung von PDF-Dokumenten. Es ist bekannt für seine Flexibilität und Erweiterbarkeit, wodurch es sich für komplexe Aufgaben im Zusammenhang mit PDF eignet.
Erstellen Sie ein neues C#-Projekt in Visual Studio, um IronPDF mit iTextSharp für das Lesen von PDF-Dateien zu vergleichen.
Installieren Sie IronPDF- und iTextSharp-Bibliotheken in das Projekt.
Lesen Sie PDF-Dateien mit IronPDF.
Visual Studio: Stellen Sie sicher, dass Visual Studio oder eine andere C#-Entwicklungsumgebung installiert ist.
Beginnen Sie mit dem Einrichten einer C#-Konsolenanwendung. Öffnen Sie Visual Studio und wählen Sie Neues Projekt erstellen. Wählen Sie den Typ Konsolenanwendung.
Geben Sie den Projektnamen wie unten gezeigt an.
Wählen Sie die gewünschte .NET-Version für das Projekt aus.
Sobald dies geschehen ist, erstellt Visual Studio ein neues Projekt.
iTextSharp kann über den NuGet Package Manager für iText installiert werden. Die neueste Version ist als iText-Paket erhältlich.
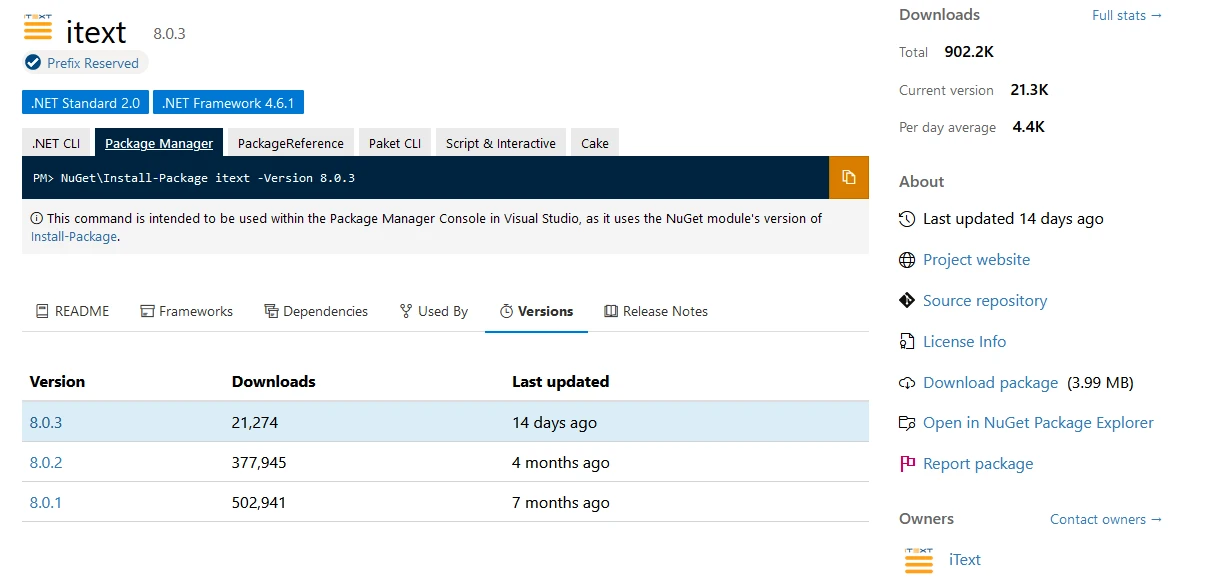
Oder über den Visual Studio Package Manager wie unten gezeigt. Suchen Sie im Paketmanager nach iText und klicken Sie auf Installieren.

IronPDF kann wie unten gezeigt über den NuGet Package Manager für IronPDF installiert werden.
Oder über den Visual Studio-Paketmanager wie unten gezeigt. Suche im Paketmanager nach IronPDF: C# PDF Library und klicke auf Installieren.

Fügen Sie den folgenden Code zur Datei program.cs hinzu und erstellen Sie ein PDF-Beispieldokument mit dem folgenden Inhalt.

using IronPdf;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
// pdfreader reader
ReadUsingIronPDF.Read();
public class ReadUsingIronPDF
{
public static void Read()
{
// read from specific location
string filename = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
var pdfReader = PdfDocument.FromFile(filename);
// Get all text to put in a search index using new simpletextextractionstrategy
var allText = pdfReader.ExtractAllText();
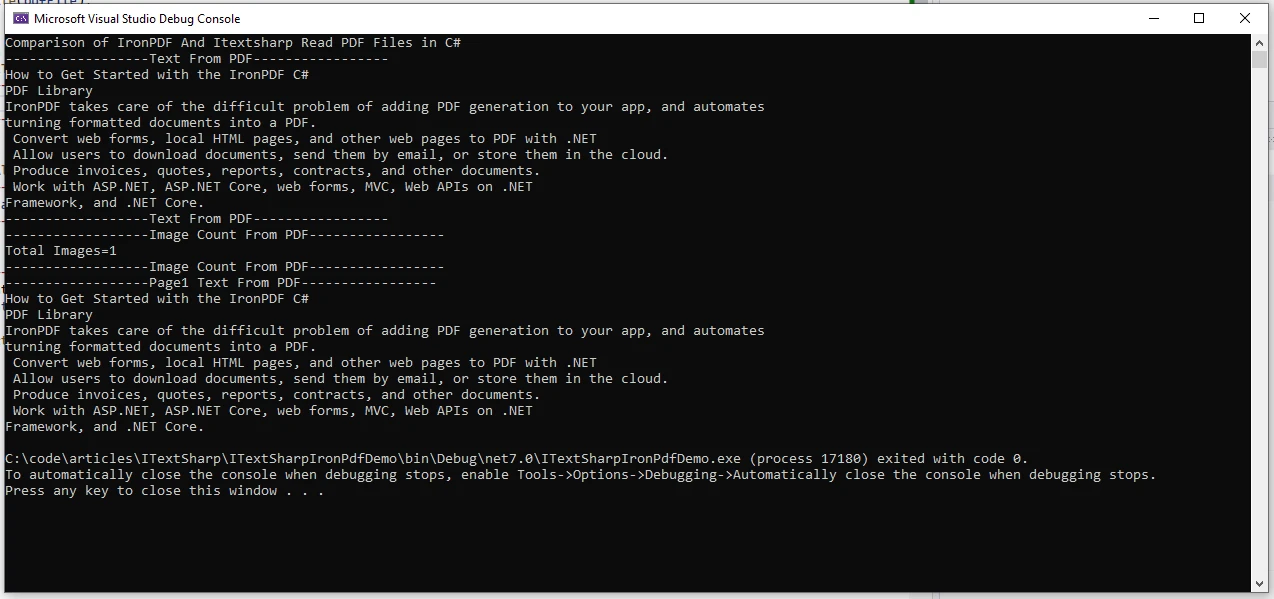
Console.WriteLine("------------------Text From PDF-----------------");
Console.WriteLine(allText);
Console.WriteLine("------------------Text From PDF-----------------");
var allIMages = pdfReader.ExtractAllImages();
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine($"Total Images={allIMages.Count()}");
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine("------------------one Page Text From PDF page-----------------");
var pageCount = pdfReader.PageCount;
for (int page = 0; page < pageCount; page++)
{
string Text = pdfReader.ExtractTextFromPage(page);
Console.WriteLine(Text);
}
}
}using IronPdf;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
// pdfreader reader
ReadUsingIronPDF.Read();
public class ReadUsingIronPDF
{
public static void Read()
{
// read from specific location
string filename = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
var pdfReader = PdfDocument.FromFile(filename);
// Get all text to put in a search index using new simpletextextractionstrategy
var allText = pdfReader.ExtractAllText();
Console.WriteLine("------------------Text From PDF-----------------");
Console.WriteLine(allText);
Console.WriteLine("------------------Text From PDF-----------------");
var allIMages = pdfReader.ExtractAllImages();
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine($"Total Images={allIMages.Count()}");
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine("------------------one Page Text From PDF page-----------------");
var pageCount = pdfReader.PageCount;
for (int page = 0; page < pageCount; page++)
{
string Text = pdfReader.ExtractTextFromPage(page);
Console.WriteLine(Text);
}
}
}Imports IronPdf
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#")
' pdfreader reader
ReadUsingIronPDF.Read()
'INSTANT VB TODO TASK: Local functions are not converted by Instant VB:
'public class ReadUsingIronPDF
'{
' public static void Read()
' {
' ' read from specific location
' string filename = "C:\code\articles\ITextSharp\ITextSharpIronPdfDemo\Example.pdf";
' var pdfReader = PdfDocument.FromFile(filename);
' ' Get all text to put in a search index using new simpletextextractionstrategy
' var allText = pdfReader.ExtractAllText();
' Console.WriteLine("------------------Text From PDF-----------------");
' Console.WriteLine(allText);
' Console.WriteLine("------------------Text From PDF-----------------");
' var allIMages = pdfReader.ExtractAllImages();
' Console.WriteLine("------------------Image Count From PDF-----------------");
' Console.WriteLine(string.Format("Total Images={0}", allIMages.Count()));
' Console.WriteLine("------------------Image Count From PDF-----------------");
' Console.WriteLine("------------------one Page Text From PDF page-----------------");
' var pageCount = pdfReader.PageCount;
' for (int page = 0; page < pageCount; page++)
' {
' string Text = pdfReader.ExtractTextFromPage(page);
' Console.WriteLine(Text);
' }
' }
'}Um ein Text-PDF zu erstellen, erstellen Sie ein Word-Dokument, fügen Sie den obigen Text in das Word-Dokument ein und speichern Sie es als PDF-Dokument unter dem Namen Beispiel.pdf
Im Code erstellen wir einen PDFReader aus dem Pfad der PDF-Datei und extrahieren den gesamten Text
Die Bilder in PDF können mit der Methode ExtractImages extrahiert werden
Um nun den gelesenen Text aus iTextSharp zu vergleichen, fügen Sie den folgenden Code in dieselbe program.cs-Datei ein. Der Einfachheit halber haben wir die Klassen nicht in verschiedene Dateien aufgeteilt.
using IronPdf;
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
//ReadUsingIronPDF.Read();
ReadUsingITextSharp.Read();
public class ReadUsingITextSharp
{
public static void Read()
{
string pdfFile = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
// Create a PDF reader
PdfReader pdfReader = new PdfReader(pdfFile);
iText.Kernel.Pdf.PdfDocument pdfDocument = new iText.Kernel.Pdf.PdfDocument(pdfReader);
// Extract plain text from the PDF
LocationTextExtractionStrategy strategy = new LocationTextExtractionStrategy();
string pdfText = PdfTextExtractor.GetTextFromPage(pdfDocument.GetPage(1), strategy);
// Display or manipulate the extracted text as needed
Console.WriteLine(pdfText);
}
}using IronPdf;
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
//ReadUsingIronPDF.Read();
ReadUsingITextSharp.Read();
public class ReadUsingITextSharp
{
public static void Read()
{
string pdfFile = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
// Create a PDF reader
PdfReader pdfReader = new PdfReader(pdfFile);
iText.Kernel.Pdf.PdfDocument pdfDocument = new iText.Kernel.Pdf.PdfDocument(pdfReader);
// Extract plain text from the PDF
LocationTextExtractionStrategy strategy = new LocationTextExtractionStrategy();
string pdfText = PdfTextExtractor.GetTextFromPage(pdfDocument.GetPage(1), strategy);
// Display or manipulate the extracted text as needed
Console.WriteLine(pdfText);
}
}Imports IronPdf
Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#")
'ReadUsingIronPDF.Read();
ReadUsingITextSharp.Read()
'INSTANT VB TODO TASK: Local functions are not converted by Instant VB:
'public class ReadUsingITextSharp
'{
' public static void Read()
' {
' string pdfFile = "C:\code\articles\ITextSharp\ITextSharpIronPdfDemo\Example.pdf";
' ' Create a PDF reader
' PdfReader pdfReader = New PdfReader(pdfFile);
' iText.Kernel.Pdf.PdfDocument pdfDocument = New iText.Kernel.Pdf.PdfDocument(pdfReader);
' ' Extract plain text from the PDF
' LocationTextExtractionStrategy strategy = New LocationTextExtractionStrategy();
' string pdfText = PdfTextExtractor.GetTextFromPage(pdfDocument.GetPage(1), strategy);
' ' Display or manipulate the extracted text as needed
' Console.WriteLine(pdfText);
' }
'}
Lernkurve: iTextSharp hat eine steilere Lernkurve, insbesondere für Anfänger.
Benutzerfreundlichkeit: IronPDF ist bekannt für seine einfache API, die es Entwicklern leicht macht, schnell loszulegen.
Fügen Sie Ihren IronPDF-Lizenzschlüssel in die appsettings.json-Datei ein.
"IronPdf.LicenseKey": "your license key"Um eine Testlizenz zu erhalten, geben Sie bitte Ihre E-Mail-Adresse an.
Die Wahl zwischen IronPDF und iTextSharp hängt von den spezifischen Anforderungen Ihres Projekts ab. Wenn Sie eine unkomplizierte und benutzerfreundliche Bibliothek für gängige PDF-Operationen benötigen, ist IronPDF möglicherweise die bessere Wahl. Berücksichtigen Sie Faktoren wie die Komplexität Ihrer Anwendung, Ihr Budget und die Lernkurve, wenn Sie Ihre Entscheidung treffen.
IronPDF wurde entwickelt, um die PDF-Erzeugung nahtlos in Ihre Anwendung zu integrieren und die Konvertierung von formatierten Dokumenten in PDFs mühelos durchzuführen. Mit diesem vielseitigen Tool können Sie Webformulare, lokale HTML-Seiten und andere Webinhalte mit .NET in PDF konvertieren. Die Benutzer können Dokumente bequem herunterladen, per E-Mail versenden oder in der Cloud speichern. Ob Sie Rechnungen, Angebote, Berichte, Verträge oder andere professionelle Dokumente erstellen müssen, IronPDF's PDF-Erstellungsmöglichkeiten haben Sie abgedeckt. Verbessern Sie Ihre Anwendung mit den intuitiven und effizienten PDF-Erstellungsfunktionen von IronPDF.
Install-Package IronPdf

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.
Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente