Test in einer Live-Umgebung
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Die C# PDF-Bibliothek
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


In diesem Tutorial lernen wir, wie man Daten aus einem PDF-Dokument (Portable Document Format) in C# liest, mit Beispielen unter Verwendung zweier verschiedener Tools.
Es gibt viele Parser-Bibliotheken/Leseprogramme im Internet, die Text und Bilder aus PDF-Dateien extrahieren können. Wir werden Informationen aus einer PDF-Datei extrahieren, indem wir die beiden nützlichsten und besten Bibliotheken mit relevanten Diensten verwenden, die es gibt. Wir werden auch beide Bibliotheken vergleichen, um herauszufinden, welche der beiden besser ist.
Wir werden [iText 7](https://itextpdf.com/products/itext-7/itext-7-core" target="_blank" rel="nofollow noopener noreferrer) und IronPDF vergleichen. Bevor wir fortfahren, werden wir beide Bibliotheken vorstellen.
die iText 7-Bibliothek ist die neueste Version von iTextSharp. Sie wird sowohl in .NET- als auch in Java-Anwendungen verwendet. Es ist mit einer Dokument-Engine (wie Adobe Acrobat Reader), Hoch- und Niedrigstufen-Programmierfähigkeiten, einem Ereignis-Listener und PDF-Bearbeitungsfunktionen ausgestattet. iText 7 kann Seiten von PDF-Dokumenten erstellen, bearbeiten und verbessern, ohne dass Fehler auftreten. Weitere Funktionen sind das Hinzufügen von Passwörtern, das Erstellen von Kodierungsstrategien und das Speichern von Berechtigungsoptionen in einem PDF-Dokument. Es wird auch verwendet, um Inhalte oder Canvas-Bilder hinzuzufügen oder zu ändern, PDF-Elemente [Dictionaries usw.] hinzuzufügen, Wasserzeichen und Lesezeichen zu erstellen, Schriftgrößen zu ändern und sensible Daten zu signieren.
mit iText 7 können wir benutzerdefinierte PDF-Verarbeitungsanwendungen für Web-, Mobil-, Desktop-, Kernel- oder Cloud-Anwendungen in .NET erstellen.
IronPDF ist eine von Iron Software entwickelte Bibliothek, mit der C#- und Java-Softwareentwickler PDF-Inhalte erstellen, bearbeiten und extrahieren können. Es wird üblicherweise verwendet, um PDFs aus HTML, aus Webseiten oder aus Bildern zu erzeugen. Es wird verwendet, um PDFs zu lesen und ihren Text zu extrahieren. Weitere Funktionen sind das Hinzufügen von Kopf- und Fußzeilen, Signaturen, Anhängen, Passwörtern und Sicherheitsfragen. Mit seinen Multithreading- und asynchronen Funktionen bietet es eine umfassende Leistungsoptimierung.
IronPDF bietet plattformübergreifende Unterstützung und ist kompatibel mit .NET 5, .NET 6 und .NET 7, .NET Core, Standard und Framework. Es ist auch mit Windows, macOS, Linux, Docker, Azure und AWS kompatibel.
Lassen Sie uns nun eine Demonstration für beide sehen.
Wir werden die folgende PDF-Datei verwenden, um Text aus der PDF-Datei zu extrahieren.

IronPDF
Schreiben Sie den folgenden Quellcode für die Extraktion von Text mit iText 7.
//assign PDF location to a string and create new StringBuilder...
string pdfPath = @"D:/TestDocument.pdf";
var pageText = new StringBuilder();
//read PDF using new PdfDocument and new PdfReader...
using (PdfDocument document = new PdfDocument(new PdfReader(pdfPath)))
{
var pageNumbers = document.GetNumberOfPages();
for (int page = 1; page <= pageNumbers; page++)
{
//new LocationTextExtractionStrategy creates a new text extraction renderer
LocationTextExtractionStrategy strategy = new LocationTextExtractionStrategy();
PdfCanvasProcessor parser = new PdfCanvasProcessor(strategy);
parser.ProcessPageContent(document.GetFirstPage());
pageText.Append(strategy.GetResultantText());
}
Console.WriteLine(pageText.ToString());
}//assign PDF location to a string and create new StringBuilder...
string pdfPath = @"D:/TestDocument.pdf";
var pageText = new StringBuilder();
//read PDF using new PdfDocument and new PdfReader...
using (PdfDocument document = new PdfDocument(new PdfReader(pdfPath)))
{
var pageNumbers = document.GetNumberOfPages();
for (int page = 1; page <= pageNumbers; page++)
{
//new LocationTextExtractionStrategy creates a new text extraction renderer
LocationTextExtractionStrategy strategy = new LocationTextExtractionStrategy();
PdfCanvasProcessor parser = new PdfCanvasProcessor(strategy);
parser.ProcessPageContent(document.GetFirstPage());
pageText.Append(strategy.GetResultantText());
}
Console.WriteLine(pageText.ToString());
}'assign PDF location to a string and create new StringBuilder...
Dim pdfPath As String = "D:/TestDocument.pdf"
Dim pageText = New StringBuilder()
'read PDF using new PdfDocument and new PdfReader...
Using document As New PdfDocument(New PdfReader(pdfPath))
Dim pageNumbers = document.GetNumberOfPages()
For page As Integer = 1 To pageNumbers
'new LocationTextExtractionStrategy creates a new text extraction renderer
Dim strategy As New LocationTextExtractionStrategy()
Dim parser As New PdfCanvasProcessor(strategy)
parser.ProcessPageContent(document.GetFirstPage())
pageText.Append(strategy.GetResultantText())
Next page
Console.WriteLine(pageText.ToString())
End Using
Extrahierte Textausgabe
Nun wollen wir mit IronPDF Text aus einer PDF-Datei extrahieren.
Der folgende Quellcode zeigt ein Beispiel für die Extraktion von Text aus PDF-Dateien mit IronPDF.
var pdf = PdfDocument.FromFile(@"D:/TestDocument.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);var pdf = PdfDocument.FromFile(@"D:/TestDocument.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);Dim pdf = PdfDocument.FromFile("D:/TestDocument.pdf")
Dim text As String = pdf.ExtractAllText()
Console.WriteLine(text)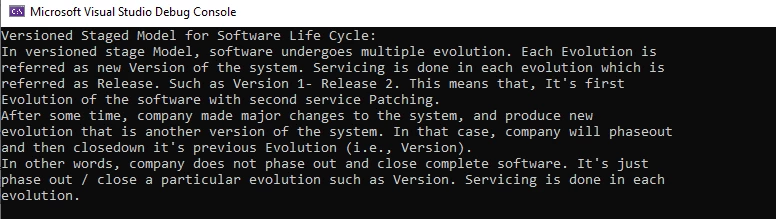
Extrahierter Text mit IronPDF
Mit IronPDF benötigt man zwei Zeilen, um Text aus PDFs zu extrahieren. Mit iText 7 hingegen müssen wir für dieselbe Aufgabe etwa 10 Zeilen Code schreiben.
IronPDF bietet von Haus aus bequeme Methoden zur Textextraktion; aber iText 7 verlangt von uns, dass wir unsere eigene Logik schreiben, um die gleiche Aufgabe zu erfüllen.
IronPDF ist sowohl in Bezug auf die Leistung als auch auf die Lesbarkeit des Codes effizient.
Beide Bibliotheken sind in Bezug auf die Genauigkeit gleichwertig, da beide eine 100 % genaue Ausgabe liefern.
iText 7 ist nur für den [kommerziellen Gebrauch](https://itextpdf.com/how-buy" target="_blank" rel="nofollow noopener noreferrer) verfügbar. IronPDF ist kostenlos für die Entwicklung und bietet auch eine kostenlose Testversion für die kommerzielle Nutzung an.
Für einen tiefergehenden Vergleich von IronPDF und iText 7 lesen Sie bitte diesen Blogbeitrag über IronPDF vs. iText 7.
30-Tage-Testschlüssel sofort.
15-Tage-Testschlüssel sofort.
Ihr Testschlüssel sollte in der E-Mail sein.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
 Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlichInstall-Package IronPdf

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich übermittelt.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase





![]() Keine Kreditkarte oder Kontoerstellung erforderlich
Keine Kreditkarte oder Kontoerstellung erforderlich
Ihr Testschlüssel sollte sich in der E-Mail befinden.
Falls nicht, kontaktieren Sie bitte
support@ironsoftware.com
Starten Sie kostenlos
Keine Kreditkarte erforderlich
Testen Sie in der Produktion ohne Wasserzeichen.
Funktioniert überall, wo Sie es benötigen.
Erhalten Sie 30 Tage lang ein voll funktionsfähiges Produkt.
Haben Sie es in wenigen Minuten einsatzbereit.
Vollständiger Zugang zu unserem technischen Support-Team während Ihrer Produkttestphase
Lizenzen ab $749. Haben Sie eine Frage? Kontaktieren Sie uns.
Buchen Sie eine persönliche 30-minütige Demo.
Kein Vertrag, keine Kartendetails, keine Verpflichtungen.


10 .NET API-Produkte für Ihre Bürodokumente