Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


This tutorial introduces how to programmatically extract texts and images from PDF files with first-class support from IronPDF.
Efficient PDF conversion. Almost anything a machine can do, IronPDF can as well. Thanks to this PDF library, developers can quickly create, read text content, write, load, and manipulate PDF.
IronPDF converts HTML into a PDF record with the aid of using the Chrome engine. Along with Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms, and WPF. IronPDF also supports Xamarin, Blazor, Unity, and HoloLense applications. IronPDF supports both Microsoft .NET and .NET Core applications (Both ASP.NET Web packages and conventional Windows packages). IronPDF can be used to make aesthetically appealing PDFs.
IronPDF can create a PDF using HTML5, JavaScript, CSS, and images. IronPDF also has a powerful HTML-to-PDF converter that integrates with PDF. A strong PDF conversion mechanism is present in IronPDF using the Chromium rendering engine. It is also unconnected to any outside sources.
For more details, visit this IronPDF licensing information page for a free limited key and professional version.
 IronPDF- Font formatting
IronPDF- Font formatting
IronPDF can also read and extract text from PDF files with the help of the IronPDF libraries. Below is a pattern of IronPDF code that may be used to examine present PDF files.
The code example below demonstrates the first method to acquire all the PDF content as a string with just a few lines.
Imports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractAllText()
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractAllText()
Console.WriteLine(AllText)
End Sub
End ModuleThe sample code above demonstrates how to use the FromFile method to read a PDF from an existing file and convert it into a PDF document object. The object provides a method called ExtractAllText that will extract plain text from the PDF and turn it into a string.
Below sample code below shows how to extract data from a PDF file using the page number.
Imports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPage(0)
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPage(0)
Console.WriteLine(AllText)
End Sub
End ModuleThe code above shows how to read a PDF from an existing file and turn it into a PDF document object using the FromFile function. Texts and images can be accessed on the PDF using this object. The object offers a method called ExtractTextFromPage that allows to send a page number as a parameter to get a string that contains every word that was on the page of the PDF.
The below code shows how to extract the data between multiple pages.
Imports IronPdf
Module Program
Sub Main(args As String())
Dim Pages As List(Of Integer) = New List(Of Integer)
Pages.Add(3)
Pages.Add(5)
Pages.Add(7)
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPages(Pages)
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim Pages As List(Of Integer) = New List(Of Integer)
Pages.Add(3)
Pages.Add(5)
Pages.Add(7)
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPages(Pages)
Console.WriteLine(AllText)
End Sub
End ModuleThe code above demonstrates how to use the FromFile method to read a PDF from an existing file and convert it into a PDF document object. This object allows examining the text and images in PDF. The object has a method called ExtractTextFromPages that can be used to get a string that includes all the text content on a given page of the document by passing a list of page numbers as a parameter. Below the left side is the source PDF and the right side is the data extracted.
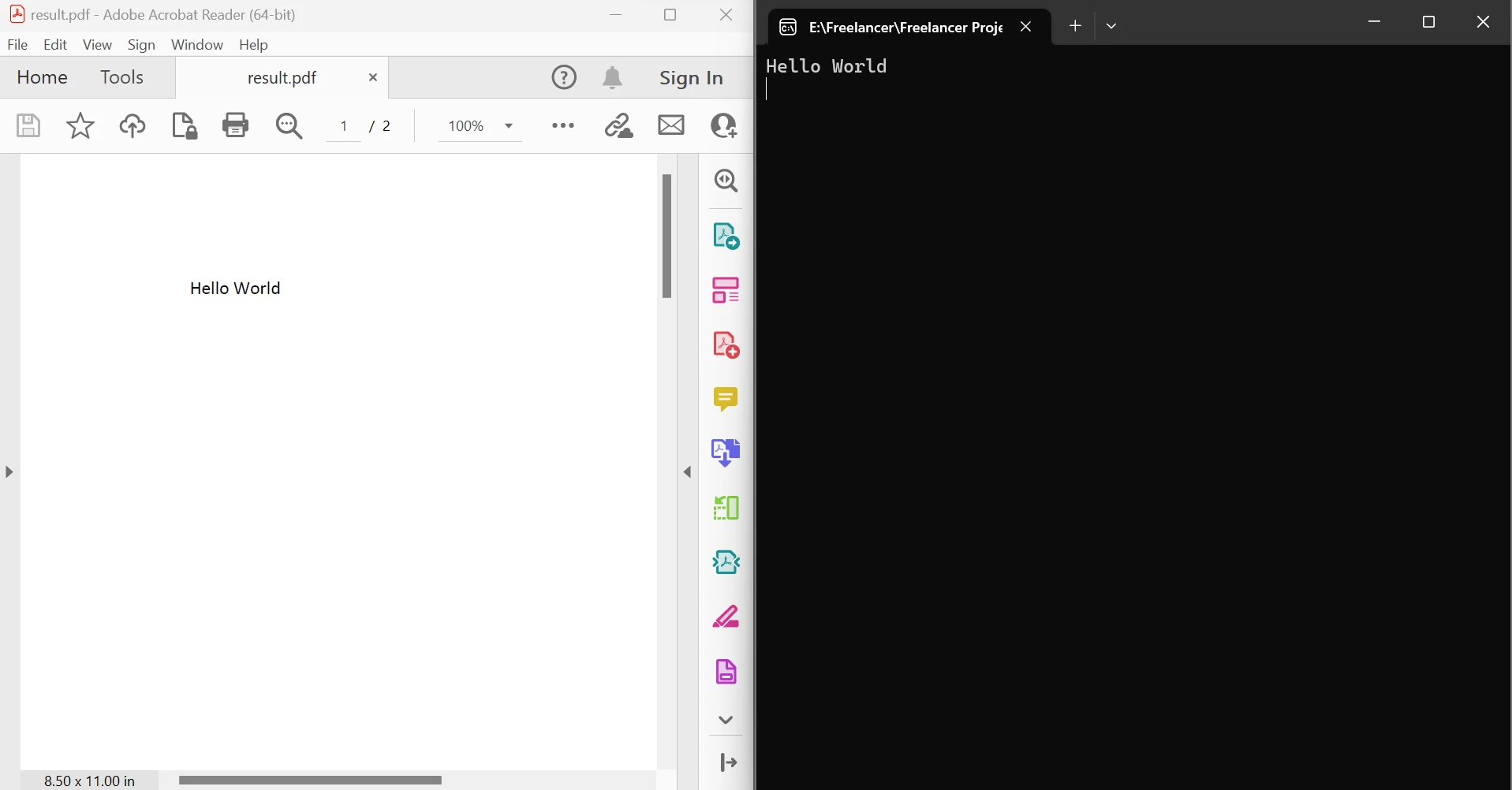 Extract text between pages output
Extract text between pages output
IronPDF provides a list of methods to extract images such as:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPagesEach method allows to extract images from a page or multiple pages of the document.
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
For Each As Byte() In images
Dim ms As New IO.MemoryStream(CType(, Byte()))
Dim image = New Bitmap(ms)
image.Save("output//test.jpg")
NextDim pdfdoc = PdfDocument.FromFile("result.pdf")
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
For Each As Byte() In images
Dim ms As New IO.MemoryStream(CType(, Byte()))
Dim image = New Bitmap(ms)
image.Save("output//test.jpg")
NextThe code above shows how to read a document from an existing file and turn it into a PDF document object using the FromFile function. By passing a list of page numbers to the object's ExtractRawImagesFromPage method, a list of bytes can be obtained that contains every picture that was present on a given page of the document. Using a foreach loop to handle each byte and turn it into a memory stream. Then into a bitmap, which aids in picture saving. The below image shows the output from the above code.
 Extract Images from PDF output
Extract Images from PDF output
To know more about the IronPDF API code tutorial, refer to the IronPDF documentation. You can also visit other tutorials to learn how to parse PDF text using C#.
The development license for the library IronPDF is gratis. If using IronPDF in a production environment, different licenses can be bought depending on the developer's needs. The Lite plan starts at $749 and has no ongoing costs. SaaS and OEM redistribution alternatives are also provided. All licenses include updates, a year of product support, and a permanent license. They are also useful for manufacturing, staging, and development. It is a one-time purchase. There are additional free, time-limited licenses accessible. Visit the comprehensive IronPDF licensing information to read the complete pricing and licensing details for IronPDF. IronPDF also provides free licenses for copy protection.
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents