Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF (Portable Document Format) files play a vital role in countless industries, enabling businesses to securely share, store, and manage documents. For developers, working with PDFs often involves creating, reading, converting, and extracting content to support client needs. Extracting text from PDFs is essential for tasks like data analysis, document indexing, content migration, or enabling accessibility features. Modern libraries like IronPDF make these tasks easier than ever, offering powerful tools for manipulating PDF files with minimal effort.
This guide focuses on one of the most common requirements: extracting text from a PDF in C#. We'll walk you through setting up a project in Visual Studio, installing IronPDF, and using it to perform text extraction with concise code examples. Along the way, we'll highlight IronPDF's robust features, including its ability to create, manipulate, and convert PDF files using .NET. Whether you're building document-heavy applications or simply need efficient PDF handling, this tutorial will get you started.
IronPDF is a robust PDF converter that can perform nearly any operation that a browser can. Creating, reading, and manipulating PDF documents is simple with the .NET library for developers. IronPDF converts HTML-to-PDF documents using the Chrome engine. IronPDF supports HTML, ASPX, Razor HTML, and MVC View, among other web components. The Microsoft .NET application is supported by IronPDF (both ASP.NET Web applications and traditional Windows applications). IronPDF can also be used to create a visually appealing PDF document.
We can make a PDF document from HTML5, JavaScript, CSS, and images with IronPDF. Additionally, the files can have headers and footers. Thanks to IronPDF, we can easily read a PDF document. IronPDF also has a comprehensive PDF converting engine and a powerful HTML-to-PDF converter that can handle PDF documents.
Open the Visual Studio software and go to the File menu. Select "New Project", and then select "Console Application". In this article, we are going to use a console application to generate PDF documents.
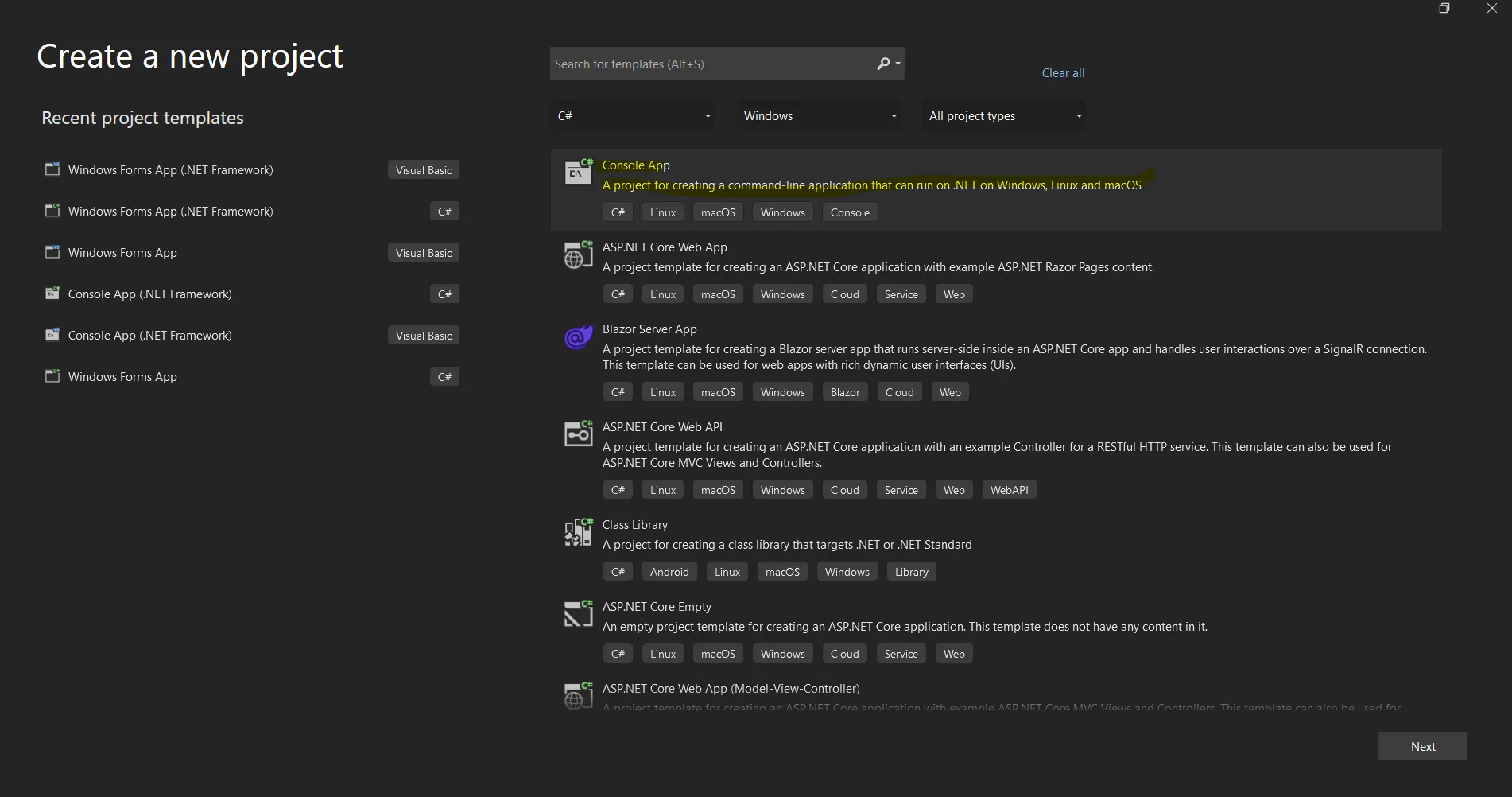 Create a new project in Visual Studio
Create a new project in Visual Studio
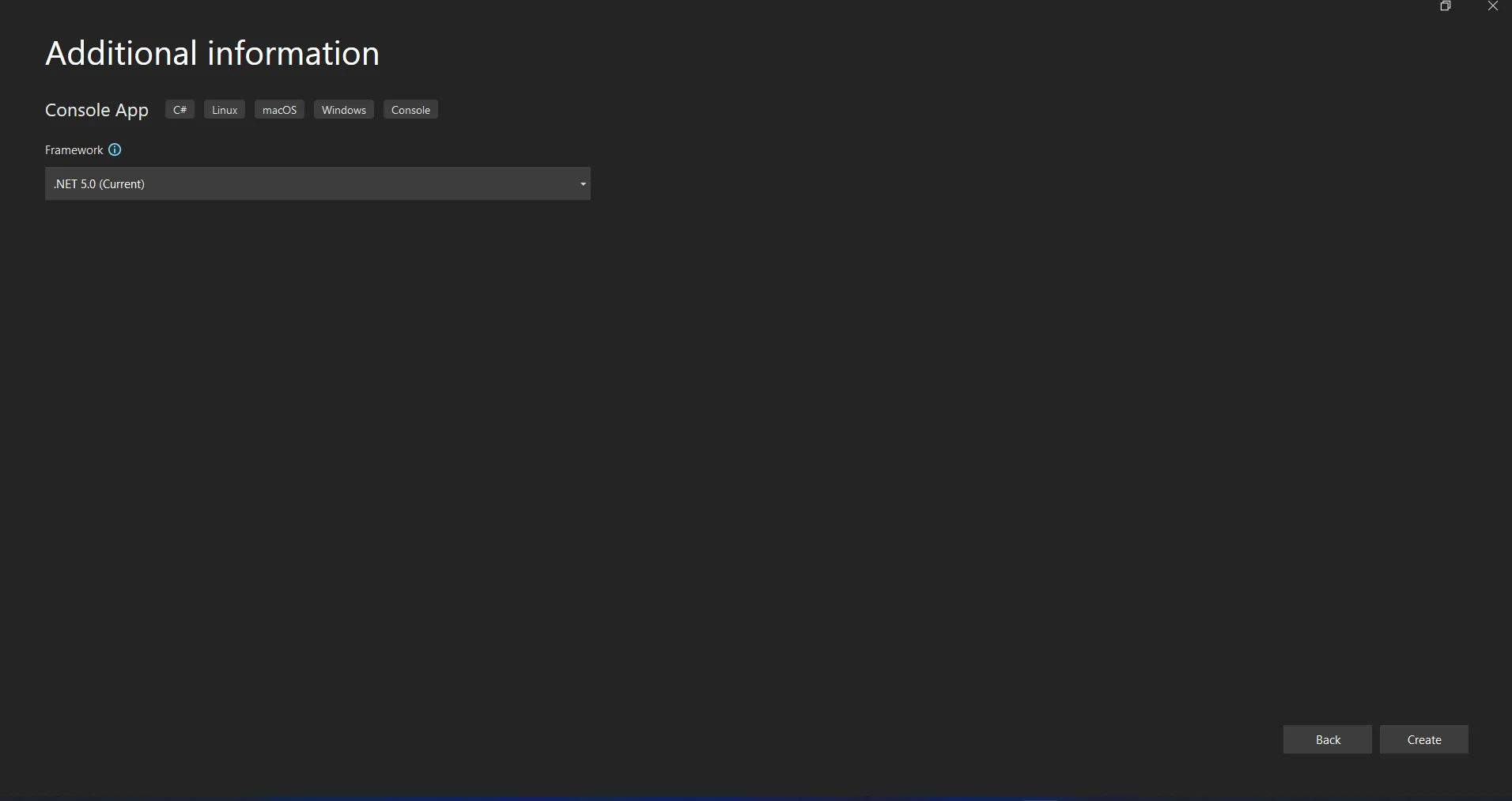
Enter the project name and select the file path in the appropriate text box. Then, click the Create button and select the required .NET Framework, as in the screenshot below.
 Configure new project in Visual Studio
Configure new project in Visual Studio
The Visual Studio project will now generate the structure for the selected application, and if you have selected the Console, Windows, and Web Application, it will open the program.cs file where you can enter the code and build/run the application.
 Selecting .NET Core
Selecting .NET Core
Next, we can add the library to test the code.
The IronPDF Library can be downloaded and installed in four ways.
These are:
The Visual Studio software provides the NuGet Package Manager option to install the package directly to the solution. The below screenshot shows how to open the NuGet Package Manager.
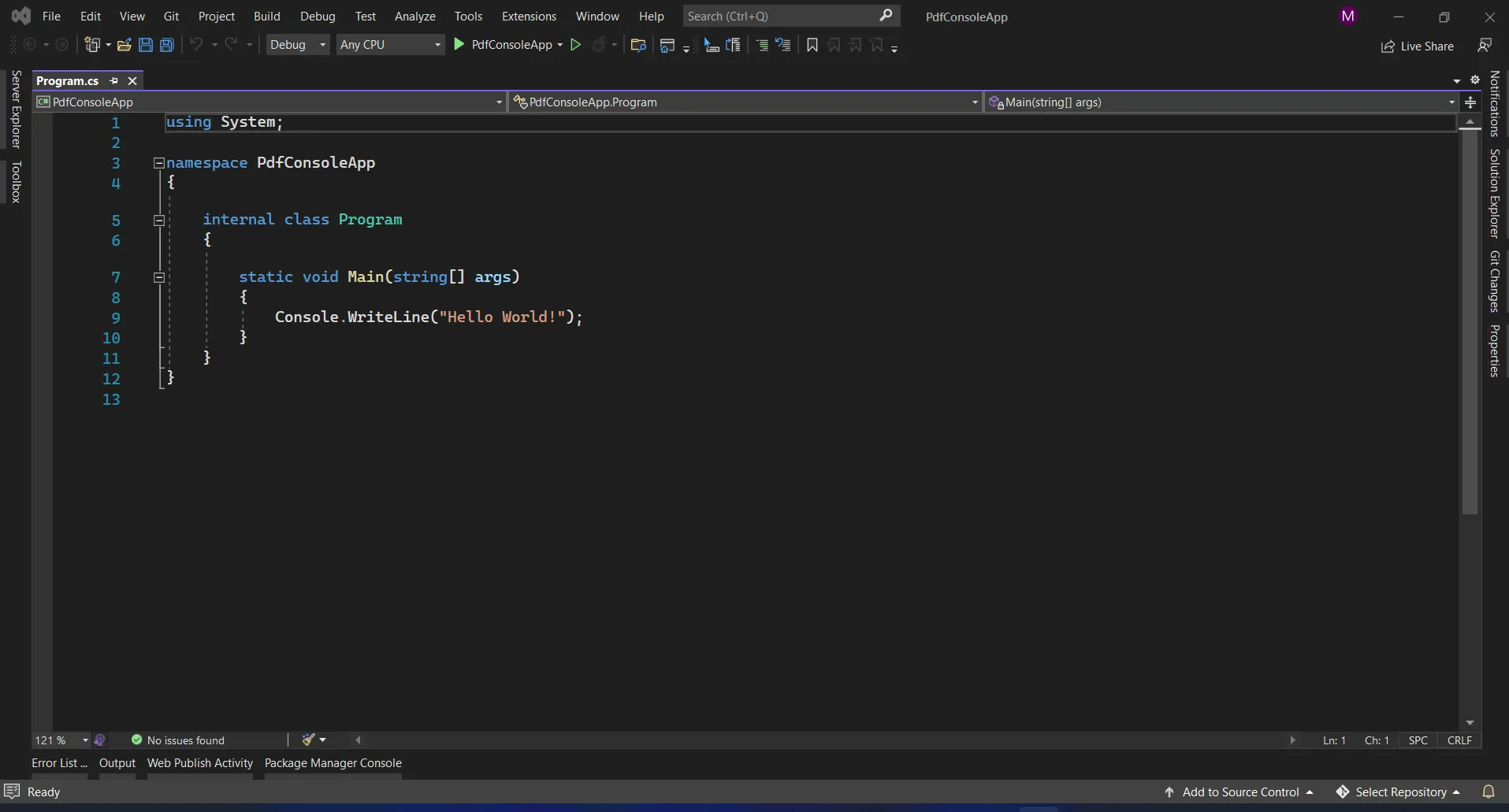 Visual Studio program.cs file
Visual Studio program.cs file
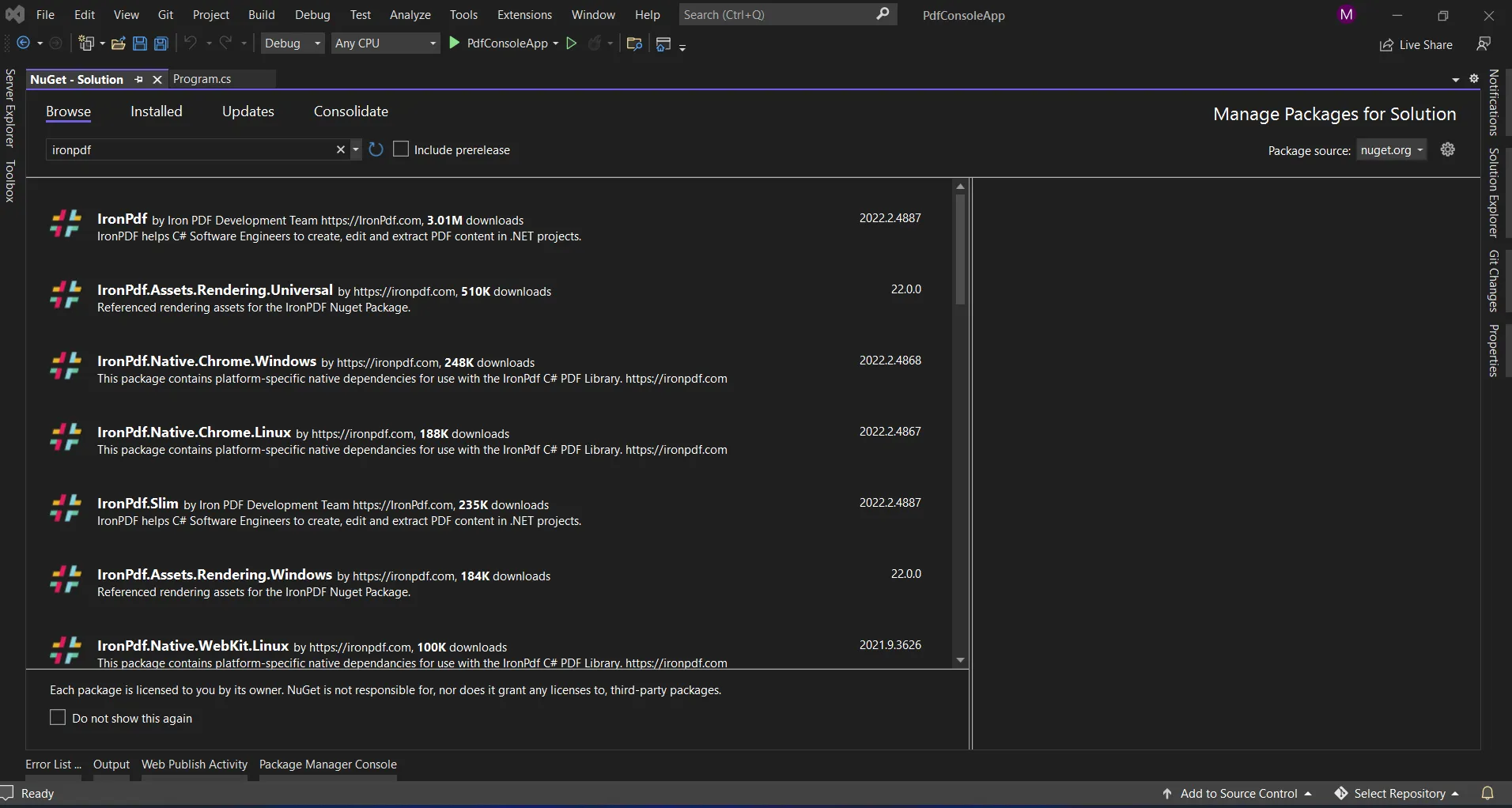
It provides the search box to show the list of packages from the NuGet website. In the package manager, we need to search for the keyword "IronPdf", as in the screenshot below.
 NuGet Package Manager
NuGet Package Manager
In the above image, we can see the list of the related search items. We need to select the required option to install the package to the solution.
In Visual Studio, go to Tools > NuGet Package Manager > Package Manager Console
Enter the following line in the package manager console tab:
Install-Package IronPdf
Now the package will download/install to the current project and be ready to use.
 IronPdf library in NuGet Package Manager
IronPdf library in NuGet Package Manager
The third way is to download the IronPDF NuGet package directly from their website.
Visit the IronPDF official site to download the latest package directly from their website. Once downloaded, follow the steps below to add the package to the project.
The IronPDF program allows us to perform text extraction from the PDF file and convert PDF pages into PDF objects. The following is an example of how to use IronPDF to read an existing PDF.
The first approach is to extract text from a PDF and the sample code snippet is below.
using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();Imports IronPdf
Private pdfDocument = PdfDocument.FromFile("result.pdf")
Private AllText As String = pdfDocument.ExtractAllText()The FromFile static method is used to load the PDF document from an existing file and transform it into PDFDocument objects, as shown in the code above. We can read the text and images accessible on the PDF pages using this object. The object has a method called ExtractAllText which extracts all the text from the whole PDF document, it then holds the extracted text into the string we can use the string to process.
Below is the code example for the second method that we can use to extract text from a PDF file, page by page.
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}Using pdf As PdfDocument = PdfDocument.FromFile("result.pdf")
For index = 0 To pdf.PageCount - 1
Dim Text As String = pdf.ExtractTextFromPage(index)
Next index
End UsingIn the above code, we see that it will first load the whole PDF document and convert it into a PDF object. Then, we obtain the page count of the whole PDF document by using an inbuilt method called PageCount, and this will retrieve the total number of pages available on the loaded PDF document. Using the "for loop" and ExtractTextFromPage function allows us to pass the page number as a parameter to extract text from the loaded document. It will then hold the exact text into the string variable. Likewise, it will extract text from the PDF page by page with the help of the "for" or the "for each" loop.
IronPDF is a versatile and powerful PDF library designed to make working with PDFs in .NET applications seamless. Its robust features enable developers to create, manipulate, and extract content from PDFs without relying on third-party dependencies like Adobe Reader. One of IronPDF's standout capabilities is its ability to extract text from PDF documents. This feature is invaluable for automating tasks like data analysis, document indexing, content migration, and enabling accessibility features. By allowing developers to retrieve and process text programmatically, IronPDF simplifies workflows and opens up new possibilities for handling PDF content.
With straightforward integration and cross-platform support, IronPDF is an excellent choice for developers seeking to handle PDF documents efficiently. Additionally, IronPDF offers a free trial, allowing you to explore its full range of features risk-free before committing. For pricing details and to learn more about licensing options, visit our pricing page.
Kye Stuart merges coding passion and writing skill at Iron Software. Educated at Yoobee College in software deployment, they now transform complex tech concepts into clear educational content. Kye values lifelong learning and embraces new tech challenges.
Outside work, they enjoy PC gaming, streaming on Twitch, and outdoor activities like gardening and walking their dog, Jaiya. Kye’s straightforward approach makes them key to Iron Software’s mission to demystify technology for developers globally.
30-day Trial Key instantly.
15-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
 No credit card or account creation required
No credit card or account creation requiredInstall-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents