Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF (Portable Document Format) files are widely used for document exchange, and being able to programmatically read their contents is valuable in various applications. The following libraries are available to read PDF in C++: Poppler, Mupdf, Haru free PDF library, Xpdf, and Qpdf.
In this article, we will explore how to read PDF files in C++ using the Xpdf command-line tool. Xpdf provides a range of utilities for working with PDF files, including extracting text content. By integrating Xpdf into a C++ program, we can extract the text from PDF files and process it programmatically.
Xpdf is an open-source software suite that provides a collection of tools and libraries for working with PDF (Portable Document Format) files. The Xpdf suite includes several command-line utilities and C++ libraries that enable various PDF-related functionalities, such as parsing, rendering, text extraction, and more. Some key components of Xpdf include pdfimages, pdftops, pdfinfo, and pdfimages. Here, we are going to use pdftotext to read PDF documents.
pdftotext is a command-line tool that extracts text content from PDF files and outputs it as plain text. This tool is particularly useful when you need to extract the textual information from PDFs for further processing or analysis. Using options, you can also specify which page or pages to extract text from.
To make a PDF reader project to extract text, we need the following prerequisites to be in place:
First, let's add the necessary header files in our main.cpp file at the top:
#include <cstdlib>
#include <iostream>
#include <fstream>#include <cstdlib>
#include <iostream>
#include <fstream>Let's write the C++ code that invokes the Xpdf command-line tool to extract text content from the PDF document. We are going to use the following input.pdf file:

The code example goes as follows:
// Include C library
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std;
int main() {
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
if (status == 0) {
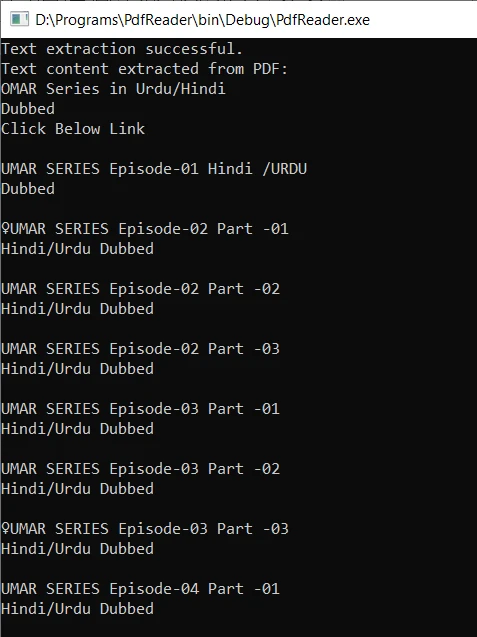
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1;
}
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n";
}
outputFile.close();
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1;
}
return 0;
}// Include C library
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std;
int main() {
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1;
}
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n";
}
outputFile.close();
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1;
}
return 0;
}In the above code, we define the pdfPath variable to hold the path to the input PDF file. Make sure to replace it with the appropriate path to your actual input PDF document.
We also define the outputFilePath variable to hold the path to the output text file that will be generated by Xpdf.
The code executes the pdftotext command using the system function, passing the input PDF file path and output text file path as command-line arguments. The status variable captures the exit status of the command.
If pdftotext executes successfully (indicated by a status of 0), we proceed to open the output text file using ifstream. We then read the text content line by line and store it in the textContent string.
Finally, we output the extracted text content to the console from the output file generated. If you do not need the editable output text file or want to free up disk space, at the end of the program simply delete it using the following command before ending the main function:
remove(outputFilePath.c_str());remove(outputFilePath.c_str());Compile the C++ code and run the executable. If the pdftotext is added to the Environment Variables System Path, its command will execute successfully. The program generates the output text file and extracts text content from the PDF document. The extracted text is then displayed on the console.
IronPDF C# Library Overview is a popular C# PDF library that provides powerful functionalities for working with PDF documents. It enables developers to create, edit, modify, and read PDF files programmatically.
Reading PDF documents using the IronPDF library is a straightforward process. The library offers various methods and properties that enable developers to extract text, images, metadata, and other data from PDF pages. The extracted information can be used for further processing, analysis, or display within the application.
Following code example will use IronPDF to read PDF files:
// Rendering PDF documents to Images or Thumbnails
using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// open a 128 bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
//...
}// Rendering PDF documents to Images or Thumbnails
using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// open a 128 bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
//...
}IRON VB CONVERTER ERROR developers@ironsoftware.comFor more detailed information on how to read PDF documents, please visit the IronPDF C# PDF Reading Guide.
In this article, we learned how to read the contents of a PDF document in C++ using the Xpdf command-line tool. By integrating Xpdf into a C++ program, we can programmatically extract text content from PDF files within a second. This approach enables us to process and analyze the extracted text within our C++ applications.
Explore IronPDF is a powerful C# library that facilitates reading and manipulating PDF files. Its extensive features, ease of use, and reliable rendering engine make it a popular choice for developers working with PDF documents in their C# projects.
IronPDF is free for development and provides a free trial for commercial use. Beyond this, it needs to be licensed for commercial purposes.
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents