Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


The need to dynamically manage and manipulate document content is widespread in the world of C# development. Developers commonly rely on robust libraries to automate activities like creating PDF reports and extracting data from web pages. This article explores the straightforward integration of IronPDF and HTML Agility Pack in C# and provides code examples to demonstrate how these libraries can be used to effortlessly create PDF documents and read HTML text.
On the other hand, IronPDF is a feature-rich .NET library for working with PDF files. As IronPDF allows developers to dynamically generate PDF files from HTML content, URLs, or raw data, it serves as a valuable tool for document creation, reporting, and data visualization.
To streamline document generation in .NET applications, we will look at how to connect IronPDF with HTML Agility Pack in this post. Combining these technologies allows programmers to work with remote systems, generate dynamic PDF pages, and get data via network connectivity, all while increasing productivity and scalability in their programs.
HTML Agility Pack is a versatile and powerful HTML parsing library for .NET developers. With the help of its extensive collection of APIs, developers can easily navigate, alter, and extract data from HTML documents. HTML Agility Pack makes working with HTML content programmatically easier for all developers, regardless of experience level.
The capacity of HTML Agility Pack to gently manage HTML that is badly organized or faulty is what makes it unique. It is perfect for online scraping operations where the quality of HTML markup may vary since it uses a forgiving parsing algorithm that can parse even the most badly constructed HTML.
With the powerful HTML parsing features offered by HTML Agility Pack, developers may load HTML documents from a variety of sources, including files, URLs, and strings. Due to its lenient parsing approach, it can gracefully handle poorly formatted or incorrect HTML, making it suitable for web scraping activities where the HTML markup quality can vary.
For exploring, browsing, and working with the HTML Document Object Model (DOM) structure, HAP offers a user-friendly API. HTML elements, attributes, and text nodes can all be added, removed, or modified programmatically by developers, allowing for dynamic HTML content manipulation.
For choosing and querying HTML components, HTML Agility Pack supports LINQ (Language Integrated Query) as well as XPath syntax searches. To choose items in an HTML document according to their attributes, tags, or hierarchy, XPath expression queries provide a strong and easy-to-understand syntax. For developers used to working with LINQ in C#, LINQ queries offer a familiar querying syntax that facilitates smooth integration with other .NET components.
The HtmlAgility Base Class Library comes in a single bundled package, which should be available in NuGet by installing it and can be used in the C# project. It offers an HTML parser and CSS selectors from the HTML document and HTML URLs.
Many C# application types, such as Windows Forms (WinForms) and Windows Console, implement HtmlAgilityPack. Though the implementation varies from framework to framework, the fundamental idea remains constant.
One of the most important tools in the C# developer's toolbox for navigating, processing, and working with HTML documents is the HTML Agility Pack (HAP). Data extraction from HTML pages is made easier by its user-friendly API, which works like an organized tree of elements. Let's examine a straightforward code example to demonstrate how to use it.
using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();using HtmlAgilityPack;
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
var doc = web.Load("https://ironpdf.com/");
// Select specific html nodes and parse html string
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
Console.ReadKey();Imports HtmlAgilityPack
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc = web.Load("https://ironpdf.com/")
' Select specific html nodes and parse html string
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
Console.WriteLine(node.InnerText)
Next node
Console.ReadKey()In this example, we load HTML node material from a URL using HTML Agility Pack. The HTML is then loaded into the var doc for parsing and manipulation. To extract content, the program first identifies the root node of the HTML document and then specifically targets nodes within the document using XPath queries. From the code above, we specifically select div elements with the class product-homepage-header from the string HTML data, and then each selected node's inner text is printed to the console.
Developers can perform several transformations and manipulations to HTML texts using the HTML Agility Pack. This covers operations like adding, deleting, or changing text nodes, elements, and attributes in addition to reorganizing the DOM hierarchy of the HTML document.
Because HAP is meant to be expandable, programmers can add new features and behaviors to increase its functionality. Using the supplied API, developers can design their own HTML parsers, filters, or manipulators to customize HAP to their unique needs and use cases.
Large HTML texts can be handled well by the algorithms and data structures of HTML Agility Pack, which is tuned for speed and effectiveness. It ensures quick and responsive HTML content parsing and manipulation by reducing memory utilization and processing overhead.
The possibilities for document management and report creation are endless when HTML Agility Pack and IronPDF for PDF Conversion are combined. Through the use of HTML Agility Pack for HTML parsing and IronPDF Documentation for PDF conversion, developers may effortlessly automate the creation of PDF documents from dynamic online material.
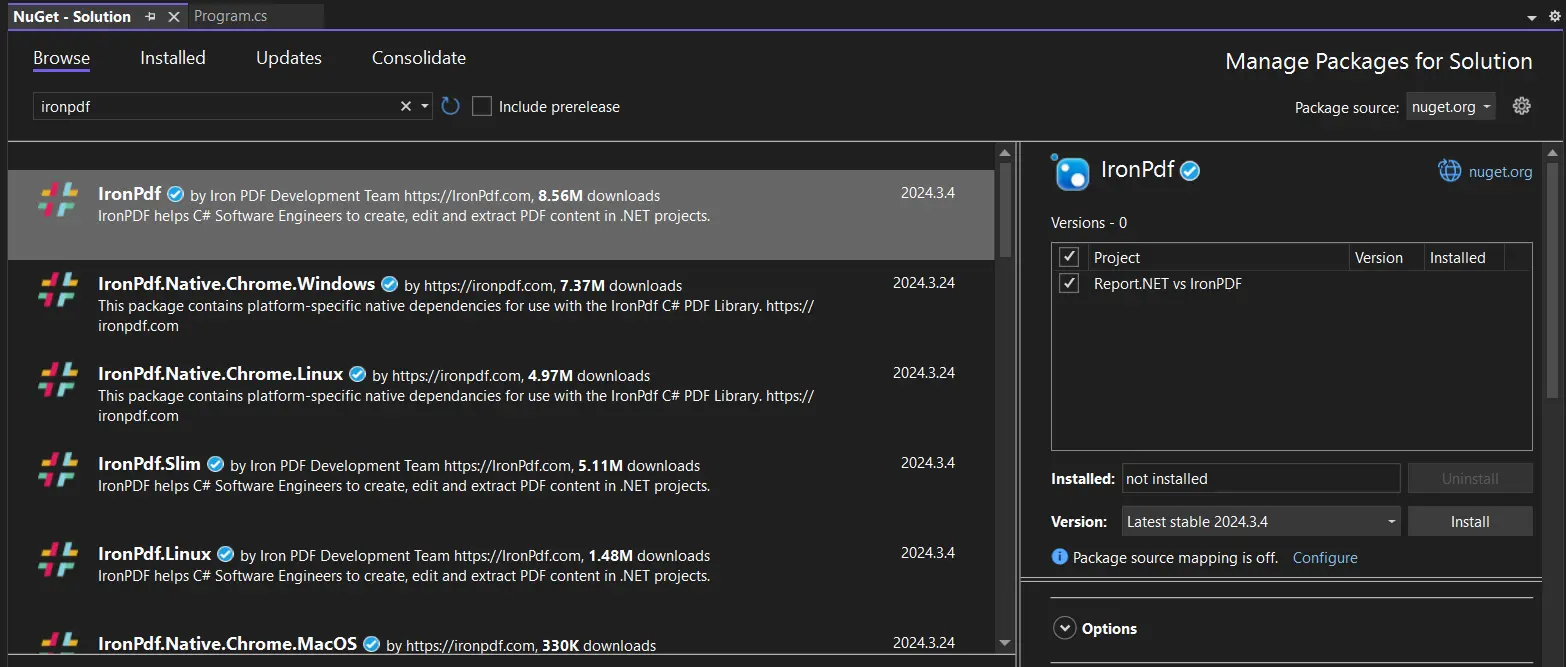
Install-Package IronPdf
Search results for the IronPDF package may be browsed, and chosen, and then the "Install" button can be clicked. Visual Studio will take care of the installation and download for you.
To find out more about the features, compatibility, and other download choices of IronPDF, see its IronPDF NuGet Package Information on the NuGet website.
As an alternative, you can use IronPDF's DLL file to integrate it straight into your project. Click this IronPDF DLL Download to obtain the ZIP file containing the DLL. After unzipping, incorporate the DLL into your project.
By integrating the features of both libraries, HTML Agility Pack (HAP) and IronPDF may be implemented in C# to read HTML information and produce PDF documents on the fly. The steps for implementation are listed below, along with a sample code that walks through each one:
using HtmlAgilityPack;
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new IronPdf.HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();using HtmlAgilityPack;
StringBuilder htmlContent = new StringBuilder();
// Load HTML content from a file or URL
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://ironpdf.com/");
// Select specific elements using XPath or LINQ
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']");
// Iterate through selected nodes and extract content
foreach (HtmlNode node in nodes)
{
htmlContent.Append(node.OuterHtml);
Console.WriteLine(node.InnerText);
}
// Convert HTML content to PDF using IronPDF
var Renderer = new IronPdf.HtmlToPdf();
var PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString());
// Save PDF to file
PDF.SaveAs("output.pdf");
Console.WriteLine("PDF generated successfully!");
Console.ReadKey();Imports HtmlAgilityPack
Private htmlContent As New StringBuilder()
' Load HTML content from a file or URL
Private web As New HtmlWeb()
Private doc As HtmlDocument = web.Load("https://ironpdf.com/")
' Select specific elements using XPath or LINQ
Private nodes As HtmlNodeCollection = doc.DocumentNode.SelectNodes("//h1[@class='product-homepage-header product-homepage-header--ironpdf']")
' Iterate through selected nodes and extract content
For Each node As HtmlNode In nodes
htmlContent.Append(node.OuterHtml)
Console.WriteLine(node.InnerText)
Next node
' Convert HTML content to PDF using IronPDF
Dim Renderer = New IronPdf.HtmlToPdf()
Dim PDF = Renderer.RenderHtmlAsPdf(htmlContent.ToString())
' Save PDF to file
PDF.SaveAs("output.pdf")
Console.WriteLine("PDF generated successfully!")
Console.ReadKey()Visit Utilizing IronPDF for Conversion to learn more about the code example.
The execution output is shown below:
Whether parsing HTML data or creating PDF reports, developers can manage and alter document material with ease thanks to the smooth integration of HTML Agility Pack and IronPDF in C#. Developers can easily and precisely automate operations connected to documents by combining the PDF production features of IronPDF with the parsing capabilities of HTML Agility Pack. The combination of these two libraries provides a strong C# document management solution, regardless of whether you're building dynamic reports or pulling data from web pages.
A perpetual license, a year of software maintenance, and a library upgrade are all included in the $749 Lite bundle. IronPDF provides free licensing with temporal and redistribution limitations. During the trial period, users can evaluate the solution without seeing a watermark. Please go to IronPDF's Licensing Information to learn more about the cost and license. To learn more about Iron Software libraries, visit their Product Information Page.
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents