Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


For this tutorial, we will be looking at how to extract text from PDF (Portable Document Format) documents in C# using two different PDF libraries.
In today's modern web age, there are a number of libraries out there that are capable of extracting text and images from PDF files for parsing and reading. Today, we will be using two powerful PDF libraries, IronPDF and QuestPDF, to extract text from a PDF file. By comparing how these two libraries handle a simple text extraction task, we can determine which may be better suited for handling such advanced PDF tasks. Before we get into the comparison section, let's first take a moment to look at a brief introduction for each library.
QuestPDF is a cutting-edge, open-source PDF generation library designed specifically for .NET developers. It utilizes a modern declarative API that enables users to define and generate complex PDF layouts with great flexibility and precision. While QuestPDF’s primary focus is on document generation rather than text extraction, it provides a clean, intuitive approach to building documents from scratch and manipulating different elements within the document. This makes it particularly well-suited for applications requiring customized, dynamic PDF content.
IronPDF is a versatile PDF processing library designed to make working with PDFs in C# easier and more efficient. Unlike QuestPDF, IronPDF is specifically built for both PDF generation and manipulation. Features it offers includes PDF encryption, extensive support for editing and annotating existing PDFs, converting various documents to PDF format, adding in headers and footers (which can be used to display page numbers), editing document metadata, multithreading & asynchronous support, and advanced PDF conversion tools.
On top of its rich set of features, IronPDF provides full cross-platform support, offering support for .NET 5/6/7, .NET Core, and .NET Framework. It is also fully compatible with Windows, macOS, Linux, and cloud platforms like Azure and AWS, making it a great choice for cross-platform .NET applications.
For today's example, we will be extracting text from our example invoice PDF document using both libraries.
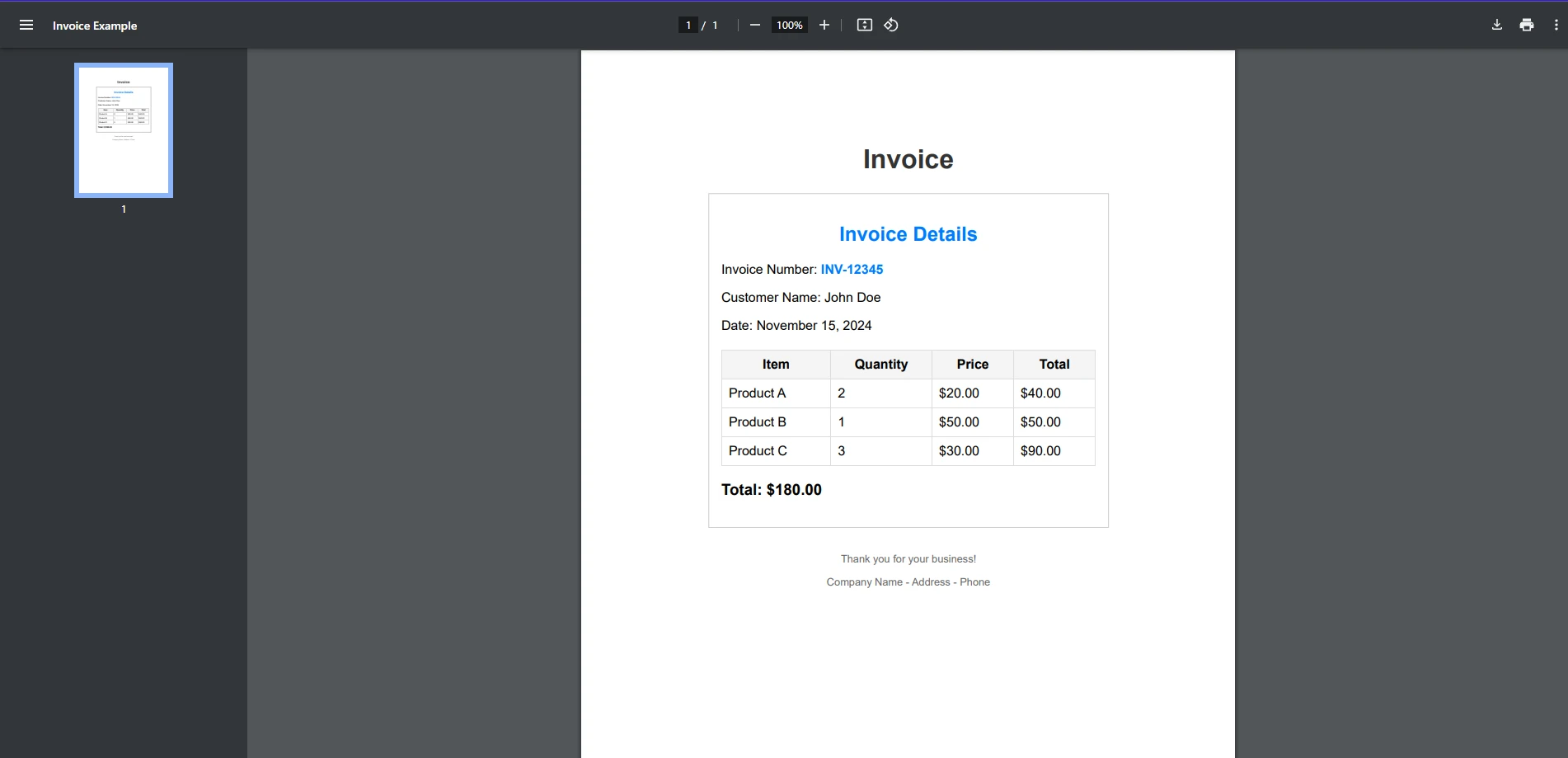
First, we will be looking at if QuestPDF can handle this task.
Unfortunately, while QuestPDF excels at handling PDF creation and the performance of certain PDF tasks, text extraction is not among the features it currently has to offer. Although QuestPDF is not inherently designed for extracting text from existing PDF files, it does provide basic tools for working with PDFs, which can be extended for text extraction with additional logic or third-party integrations. For example, QuestPDF could be used to generate PDF documents with structured content, and you could implement a custom solution to extract content based on the document's structure using a third-party library.
Text extraction is just one of the tasks that IronPDF excels at when it comes to working with PDFs, in just a few lines of code, we are able to extract text from an entire PDF document. This can be seen in the following code snippet:
using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}Imports IronPdf
Public Class Program
Public Shared Sub main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Console.WriteLine(text)
End Sub
End Class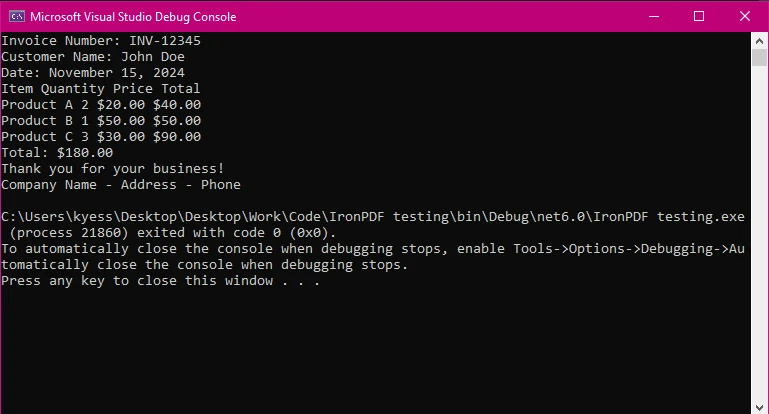
IronPDF provides a simple API for extracting text, making it ideal for developers focused on efficiency. In just three lines, we were able to extract the text content within our PDF document and display it to be read. From here, you could easily save the extracted text for further use or manipulation.
QuestPDF, on the other hand, could not handle a task such as text extraction, due to a more limited number of features than libraries such as IronPDF. While it can handle other tasks such as PDF generation and basic manipulation, you would need to implement external libraries in order to extract text.
When it comes to extracting text. QuestPDF is free through the use of it's community license for private projects, but also has the option of commercial licenses.
Both libraries are accurate and reliable, but the choice ultimately depends on your project requirements.
For a deeper comparison of these libraries, check out the full blog on IronPDF vs QuestPDF.
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents