Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


In today's increasingly digitized world, the Portable Document Format (PDF) has become a ubiquitous file format for sharing and preserving digital documents. However, there are instances where converting PDFs to images becomes necessary, unlocking a myriad of possibilities for users. Converting PDF to image format provides a versatile solution, enabling seamless integration of documents into presentations, web pages, or social media platforms. In this era of visual communication, the ability to transform PDFs into images offers enhanced accessibility and opens up new avenues for creativity and convenience. This article explores the significance of converting PDFs to images using Java and tools available to accomplish this task efficiently.
For this purpose, we will use and compare two Java PDF libraries named as follows:
renderPdf object.PdfRenderImageType method on the PDF file.PdfToImageRenderer.OUTPUT_DIRECTORY.IronPDF for Java opens the door to powerful PDF manipulation and generation capabilities within the Java programming ecosystem. As businesses and developers seek efficient solutions to handle PDF-related tasks programmatically, IronPDF emerges as a reliable and feature-rich library. Whether it's converting HTML content to PDF, merging, splitting, or editing existing PDF documents, IronPDF equips Java developers with a robust set of tools to streamline their workflow. With its easy integration and extensive documentation, this library empowers Java applications to seamlessly interact with PDFs, offering a comprehensive solution for all PDF-related requirements. In this article, we will explore the key features and benefits of IronPDF for Java and illustrate how it simplifies the PDF handling process in Java applications.
iTextSharp for Java (iText7), a powerful and versatile PDF library, equips developers with the ability to create, modify, and manipulate PDF documents programmatically. Originally developed for .NET, iTextSharp (iText7) has been adapted for Java, providing a seamless and efficient solution for all PDF-related tasks within the Java ecosystem. With its extensive functionality and easy-to-use API, iText7 enables Java developers to generate dynamic PDFs, add content, insert images, and extract data from existing PDFs effortlessly. Whether it's creating invoices, generating reports, or integrating PDF processing into enterprise applications, iText7 is a valuable tool that empowers developers to take full control of their PDF handling requirements. In this article, we will explore the essential features and benefits of iTextSharp for Java (iText7) and demonstrate its capabilities through practical examples.
To integrate IronPDF and its required logger dependency, SLF4J, into your Maven project, follow these steps:
Include the following dependency entries for IronPDF and SLF4J:
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2023.7.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>Save the pom.xml file.
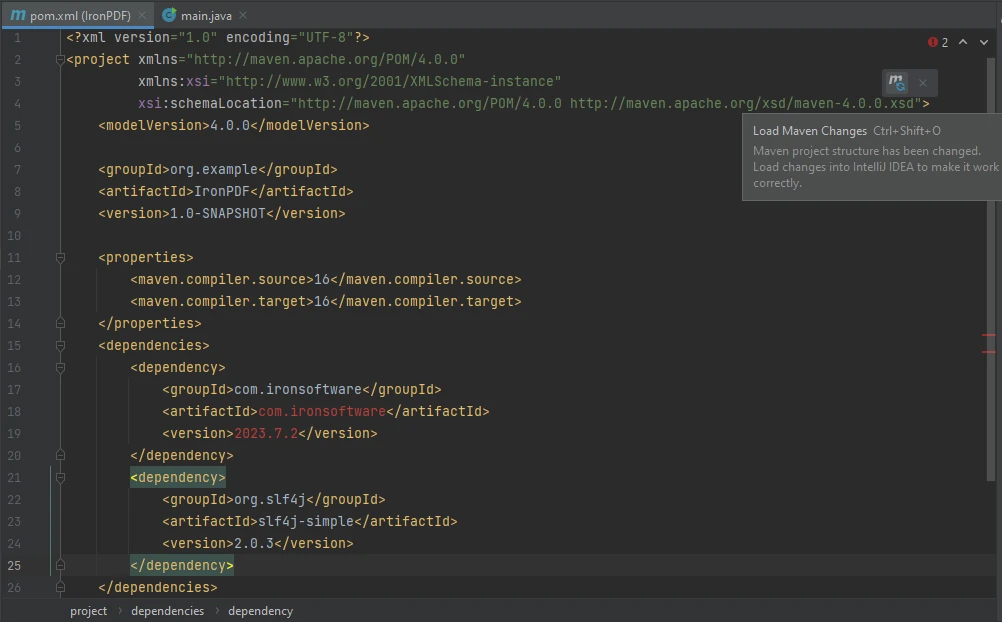
That's all! Just press the button shown above to include these dependencies in your project.
To install iText7, follow the steps below to add the dependency:
Find the dependencies tags. If they do not exist, create them and place the following code between these tags:
<!-- https://mvnrepository.com/artifact/com.itextpdf/itext7-core -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext7-core</artifactId>
<version>8.0.0</version>
<type>pom</type>
</dependency>Just like that, your dependencies are installed.
Extracting images from PDF pages using IronPDF is easier than you thought with just a few lines of code. IronPDF offers compatibility with many image file types, such as JPEG and PNG.
In this section, we will go through the sample code to convert a PDF file to images using IronPDF for Java.
import com.ironsoftware.ironpdf.License;
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
import java.io.File;
public class Main {
public static void main(String [] args) throws Exception {
// Create a new PdfDocument instance
PdfDocument pdf = PdfDocument.fromFile(Paths.get("composite.pdf"));
List<BufferedImage> images = pdf.extractAllImages();
int i = 1;
for (BufferedImage extractedImage : images) {
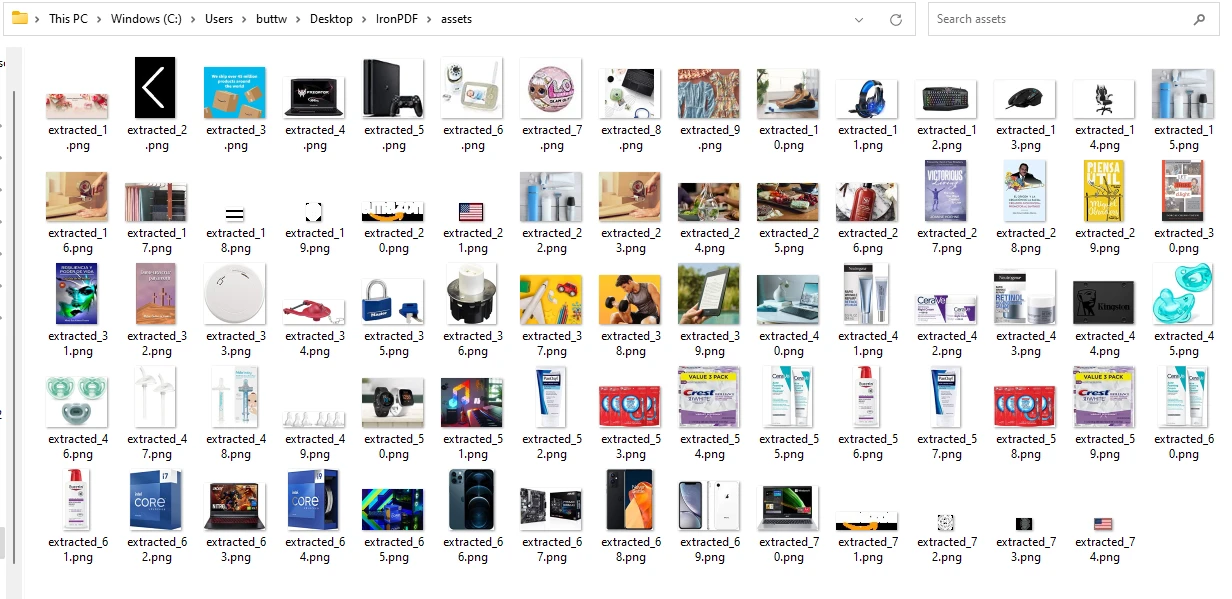
String fileName = "assets/extracted_" + i++ + ".png";
ImageIO.write(extractedImage, "PNG", new File(fileName));
}
}
}The above code first opens the PDF file using the PdfDocument.fromFile() method, which takes the file path as a parameter. Then it uses the extractAllImages() method to extract all images from the PDF document and save them in a list named images. Then, it loops through the images and saves each image using the ImageIO.write() method, which takes the image, file type ("PNG"), and the path + name as parameters.
In this section, we will see how you can extract images from PDF using the iText7 Java PDF Library. Here is an example code for the iText7 PDF to image extraction.
import com.itextpdf.pdfrender.PdfRenderImageType;
import com.itextpdf.pdfrender.PdfToImageRenderer;
import com.itextpdf.pdfrender.RenderingProperties;
import java.io.File;
import java.io.IOException;
public class PdfRender_Demo {
private static String ORIG = "/uploads/input.pdf";
private static String OUTPUT_DIRECTORY = "/myfiles/";
public static void main(String [] args) throws IOException {
final RenderingProperties properties = new RenderingProperties();
properties.setImageType(PdfRenderImageType.JPEG);
properties.setScaling(1.0f);
PdfToImageRenderer.renderPdf(new File(ORIG), new File(OUTPUT_DIRECTORY), "/customfilename-%d", properties);
}
}When working with iText7, it was observed that iText7 is slow in speed and cannot easily process large files.

In today's digitized world, the ability to convert PDFs to images offers diverse possibilities for seamless integration of documents into presentations, web pages, or social media platforms, enhancing accessibility and creativity. Both iTextSharp for Java (iText7) and IronPDF for Java present valuable solutions for this task.
iTextSharp empowers developers with a powerful and versatile PDF library, enabling the creation, modification, and manipulation of PDF documents programmatically. However, it may face challenges with large files and slower processing speed.
In contrast, the IronPDF for Java page offers a feature-rich and efficient library, providing developers with tools for handling PDF-related tasks programmatically, including extracting images, merging, splitting, and editing PDF documents. IronPDF for PDF to Image Conversion clearly stands victorious in this comparison.
For a complete tutorial on extracting images from PDF using Java, visit the following comprehensive guide on extracting images using IronPDF for Java. The complete comparison is available at this full comparison of PDF to image libraries.
iText7 Pricing Information starts at $0.15 per PDF. As for IronPDF, it offers a lifetime license starting from $liteLicense for a single-time purchase and also provides a free trial license for IronPDF. For more information, visit the IronPDF Licensing Information.
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents