Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Handling PDFs is a common task in C# development, from extracting text to modifying documents. iText 7 has long been a go-to library for this, but its complex syntax and steep learning curve can slow down development.
IronPDF offers a simpler, more efficient alternative. With an intuitive API, built-in HTML-to-PDF conversion, and easier text extraction, IronPDF streamlines PDF handling with less code. In this article, we’ll compare iText 7 and IronPDF, demonstrating why IronPDF is the smarter choice for C# developers.

iText 7 (originally iTextSharp) is a powerful open-source library for working with PDFs in .NET. It provides extensive functionality for creating, modifying, encrypting, and extracting content from PDF documents. Many developers rely on it for automating document workflows, generating reports, and handling large-scale PDF processing tasks.
One of iText 7’s biggest strengths is its fine-grained control over PDF structures. It supports annotations, form fields, watermarks, and digital signatures, making it a robust tool for advanced document manipulation. Additionally, it’s well-documented and widely used, with strong community support and many third-party resources available.
To install iText 7 in a .NET project, you can use the NuGet Package Manager in Visual Studio:
Using the NuGet Package Manager Console:
Install-Package itext7However, iText 7 comes with challenges. Its complex API requires more code for common tasks like text extraction or merging PDFs. It lacks built-in support for HTML-to-PDF conversion, making web-to-document workflows more difficult. Additionally, its AGPL licensing requires businesses to purchase a commercial license to avoid open-source distribution requirements.
For developers seeking a more streamlined, high-level API with modern features, IronPDF presents a compelling alternative.
IronPDF is a .NET library designed to make PDF extraction, manipulation, and generation simple and efficient. Unlike iText 7, which requires extensive coding for many operations, IronPDF allows developers to read, edit, and modify PDFs with minimal effort.
For PDF extraction, IronPDF makes it easy to pull text, images, and structured data from PDFs with just a few lines of code, making it easy to streamline your text extraction tasks with ease. When it comes to PDF manipulation, IronPDF supports merging, splitting, watermarking, and editing PDFs without requiring complex low-level operations.
Additionally, IronPDF includes native HTML-to-PDF conversion, making it simple to generate PDFs from web pages or existing HTML content. It also supports JavaScript rendering, digital signatures, and encryption, providing a well-rounded toolkit for modern applications.
With a cleaner API, better documentation, and commercial support, IronPDF is a developer-friendly alternative that simplifies PDF handling in C#. In the next sections, we’ll compare how both libraries handle key PDF tasks and why IronPDF offers a better experience for C# developers.
To get IronPDF up and running in your C# projects, it's as easy as running the following line in the NuGet Package Manager:
| Install-Package IronPdf |
|---|
Or, alternatively, going to Tools > NuGet Package Manager > Manage NuGet Packages for Solution, and searching for IronPDF.
Then, simply click “Install” and IronPDF will be added to your project in no time!
IronPDF simplifies PDF text extraction, manipulation, and reading with a much more developer-friendly API. Unlike iText 7, which requires low-level operations, IronPDF allows text extraction in just a few lines of code.
To demonstrate IronPDF’s powerful text extraction tool in action, I will take the following PDF document and extract the content from within it.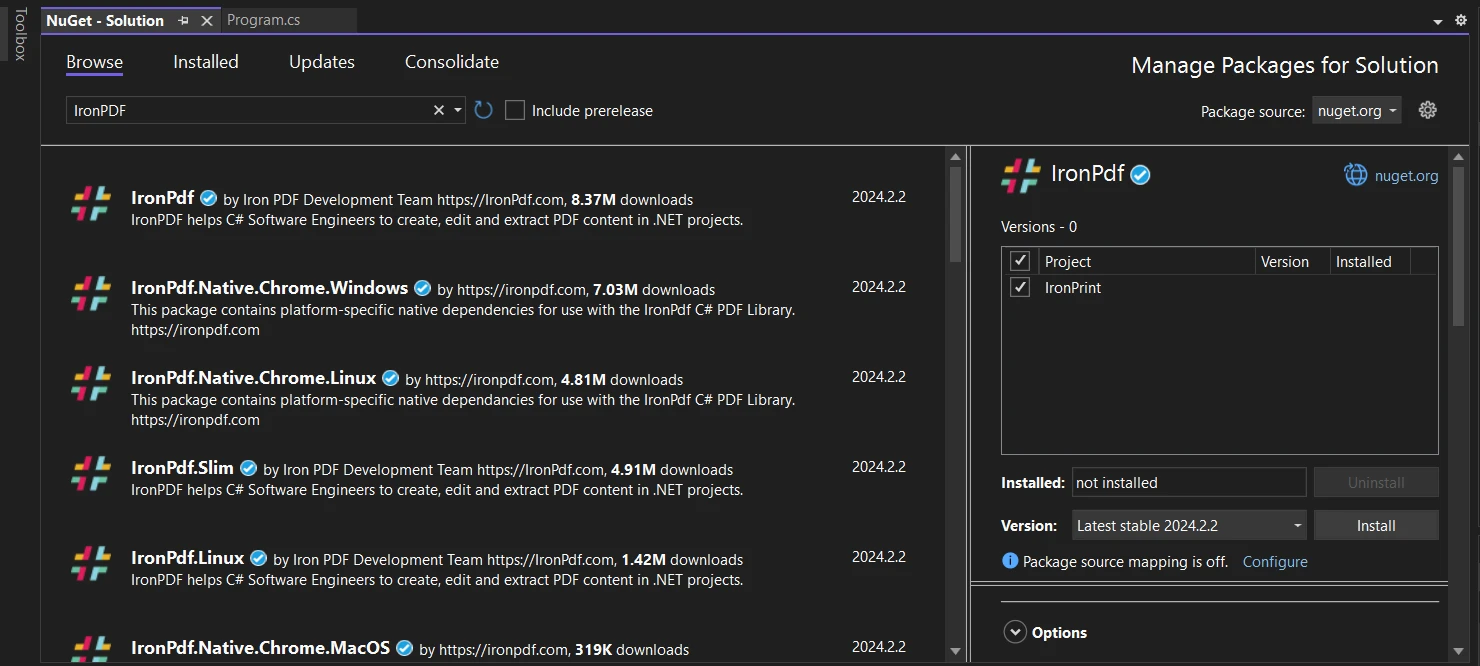
Code Example
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
var pdf = new PdfDocument(pdfPath);
string extractedText = pdf.ExtractAllText();
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
var pdf = new PdfDocument(pdfPath);
string extractedText = pdf.ExtractAllText();
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim pdf = New PdfDocument(pdfPath)
Dim extractedText As String = pdf.ExtractAllText()
Console.WriteLine(extractedText)
End Sub
End ClassOutput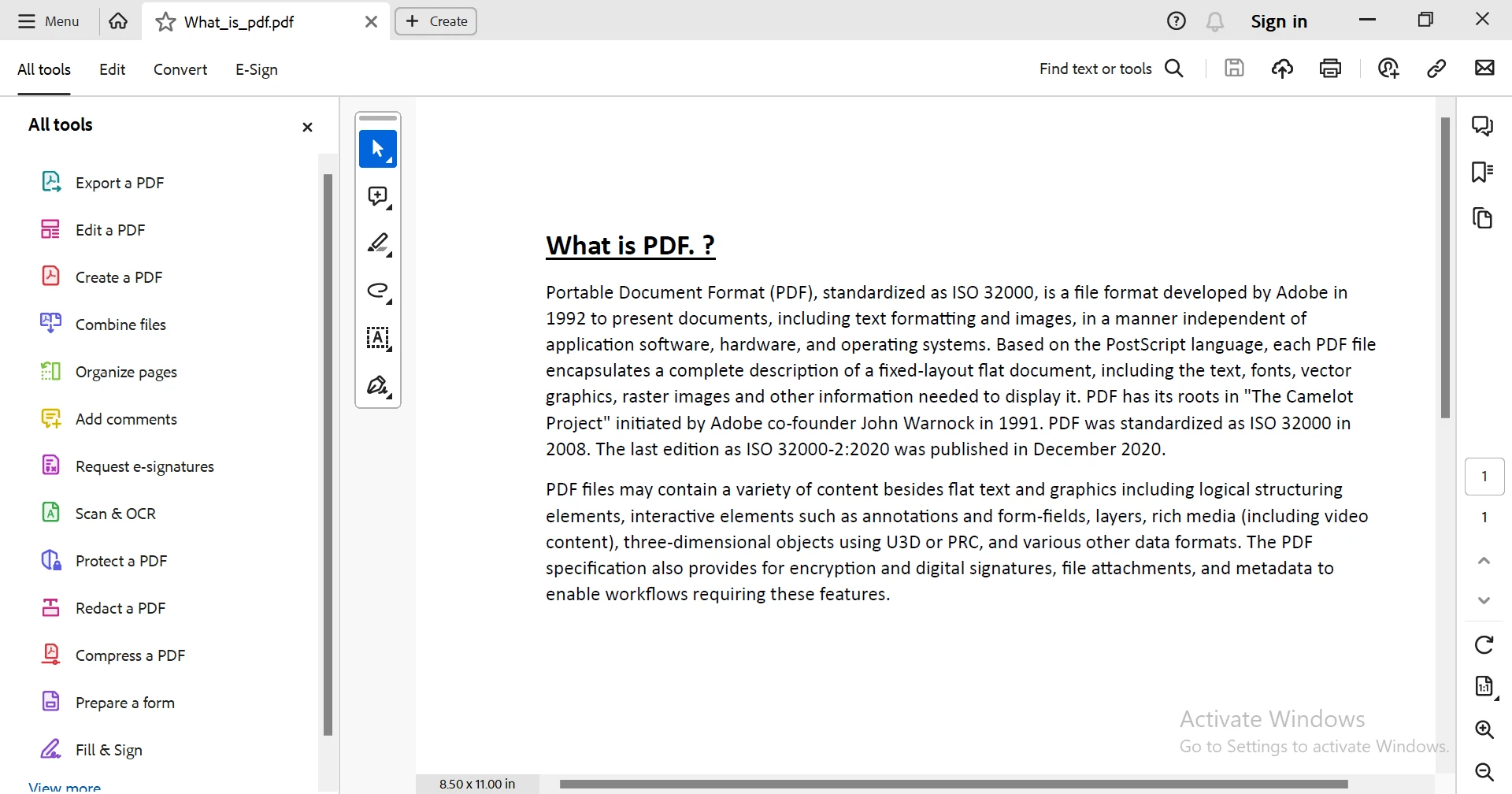
IronPDF simplifies PDF text extraction with its high-level API, eliminating the need for low-level operations. In just a few lines of code, IronPDF can efficiently extract all text from a PDF document, unlike libraries like iText 7, which often require manual page iteration and complex handling.
In the example, the PdfDocument class loads the PDF and the ExtractAllText() method quickly extracts all text, streamlining the process. This is a major advantage over iText 7, where you would need to manually handle individual pages and text elements.
Building on the basic text extraction example, IronPDF's high-level API simplifies other common PDF tasks, all while maintaining the ease of use and efficiency:
Extracting Text from Specific Pages: If you need to extract text from a specific page or range, IronPDF allows you to do this easily. For example, to extract text from the first page:
var pdf = new PdfDocument("sample.pdf");
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)PDF Manipulation: After extracting text or data from multiple PDFs, you might want to combine them into one document. IronPDF makes merging multiple PDFs simple:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")PDF to HTML Conversion: If you need to convert a PDF back into HTML for further extraction or manipulation, IronPDF provides this functionality as well:
var pdf = new PdfDocument("sample.pdf");
string htmlContent = pdf.ToHtmlString(); var pdf = new PdfDocument("sample.pdf");
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
Dim htmlContent As String = pdf.ToHtmlString()With IronPDF, text extraction is just the beginning. The library’s simple, powerful API extends to a wide range of PDF manipulation tasks, all in a format that’s intuitive and easy to integrate into your workflow.
iText 7 requires working with PDF readers, streams, and byte-level data processing. Extracting text is not straightforward, as it involves iterating through PDF pages and handling various structures manually. For this code example, we will be using the same PDF document as we did in the IronPDF section.
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
static string ExtractTextFromPdf(string pdfPath)
{
using (PdfReader reader = new PdfReader(pdfPath))
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
static string ExtractTextFromPdf(string pdfPath)
{
using (PdfReader reader = new PdfReader(pdfPath))
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
Using reader As New PdfReader(pdfPath)
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End ClassOutput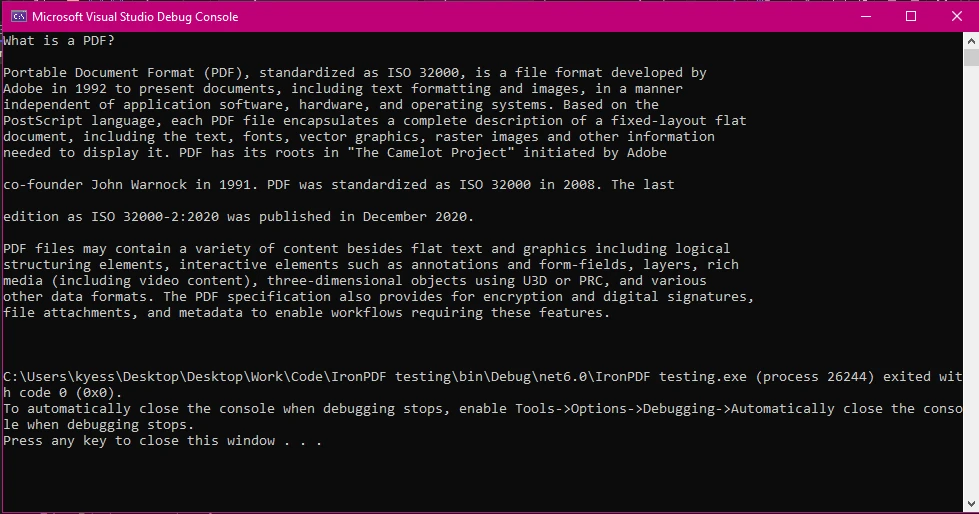
PdfReader loads the PDF file for reading.PdfDocument object allows iterating through pages.PdfTextExtractor.GetTextFromPage() retrieves text from each page.This method works but requires manual iteration and can be cumbersome for structured documents or scanned PDFs.
While iText 7 requires detailed coding to perform PDF operations, IronPDF streamlines these tasks with straightforward methods. For instance, extracting text from a PDF with iText 7 involves multiple steps and extensive code, whereas IronPDF accomplishes this in just a few lines. Additionally, IronPDF's support for HTML to PDF conversion is more robust, handling complex HTML, CSS, and JavaScript seamlessly.
IronPDF offers a suite of powerful features that go beyond just PDF reading. These features make it a robust solution for developers looking to optimize their PDF workflows. Here's how IronPDF can enhance your development process:
IronPDF allows for easy extraction of text from PDF files, making it ideal for workflows that involve document analysis, data extraction, or content indexing. With IronPDF, you can quickly pull text from PDFs and use it in your applications without dealing with complex parsing.
IronPDF makes it simple to generate PDFs from scratch, whether you're creating reports, invoices, or other types of documents. The tool also supports HTML to PDF conversion, allowing you to leverage existing web content and generate well-formatted PDFs. This is perfect for scenarios where you need to convert web pages or dynamic HTML content into downloadable PDF files.
Beyond basic text extraction and PDF creation, IronPDF supports advanced features such as filling out PDF forms, adding annotations, and manipulating document content. These capabilities are useful in industries like legal, financial, or education where forms and feedback are a regular part of the workflow.
IronPDF is well-suited for processing large numbers of PDF files. Whether you're extracting information from hundreds of documents or converting multiple HTML files to PDFs, IronPDF can automate these tasks and handle them efficiently, saving both time and effort.
IronPDF simplifies PDF manipulation tasks that are often time-consuming and repetitive. By automating tasks like PDF text extraction, form filling, or batch conversion, developers can focus on more complex aspects of their projects while letting IronPDF handle the heavy lifting.
To ensure developers can make the most of IronPDF, the tool is backed by strong support and community resources:
In this article, we've explored the capabilities of IronPDF as a powerful, user-friendly PDF handling library for .NET developers. We compared it to iText 7, highlighting how IronPDF simplifies complex tasks such as text extraction and PDF manipulation. IronPDF’s clean API and advanced features, including editing, watermarking, and digital signatures, make it a superior solution for modern PDF workflows.
Unlike iText 7, which requires intricate coding for common PDF tasks, IronPDF allows you to perform complex operations with minimal code, saving developers time and effort. Whether you’re working with scanned documents, generating PDFs from HTML, or adding custom watermarks, IronPDF offers an intuitive and efficient way to handle it all.
If you're looking to streamline your PDF workflows and increase productivity in your C# projects, IronPDF is the ideal choice.
We invite you to download IronPDF and try it for yourself. With a free trial available, you can experience firsthand how easy it is to integrate IronPDF into your applications and start benefiting from its powerful features today.
Click below to get started with your free trial:
Don’t wait – unlock the potential of seamless PDF handling with IronPDF!
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents